




Jonas
@jonasgeiping.bsky.social
ML research, safety & efficiency
Ok, so I can finally talk about this!
We spent the last year (actually a bit longer) training an LLM with recurrent depth at scale.
The model has an internal latent space in which it can adaptively spend more compute to think longer.
I think the tech report ...🐦⬛
We spent the last year (actually a bit longer) training an LLM with recurrent depth at scale.
The model has an internal latent space in which it can adaptively spend more compute to think longer.
I think the tech report ...🐦⬛

February 10, 2025 at 4:48 PM
Ok, so I can finally talk about this!
We spent the last year (actually a bit longer) training an LLM with recurrent depth at scale.
The model has an internal latent space in which it can adaptively spend more compute to think longer.
I think the tech report ...🐦⬛
We spent the last year (actually a bit longer) training an LLM with recurrent depth at scale.
The model has an internal latent space in which it can adaptively spend more compute to think longer.
I think the tech report ...🐦⬛
Reposted by Jonas

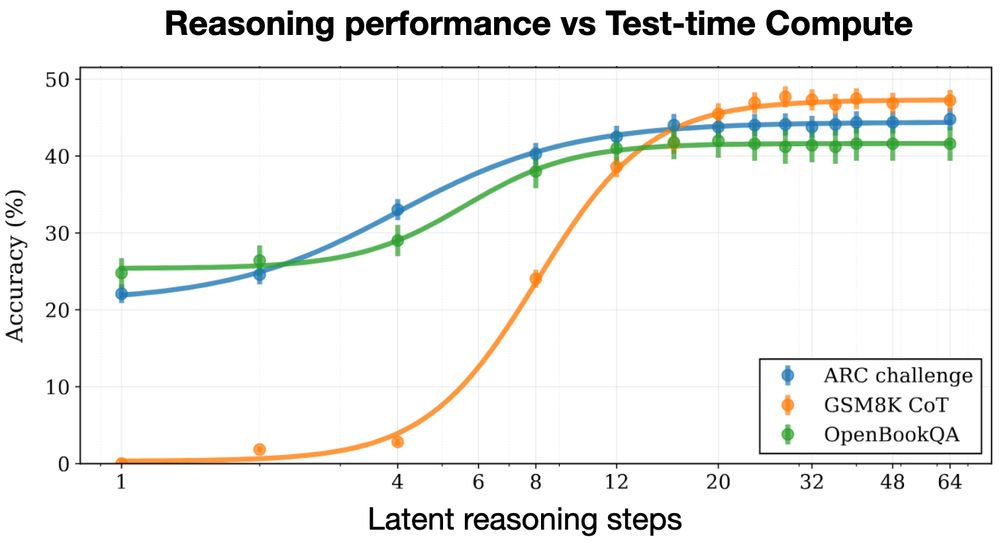
New open source reasoning model!
Huginn-3.5B reasons implicitly in latent space 🧠
Unlike O1 and R1, latent reasoning doesn’t need special chain-of-thought training data, and doesn't produce extra CoT tokens at test time.
We trained on 800B tokens 👇
Huginn-3.5B reasons implicitly in latent space 🧠
Unlike O1 and R1, latent reasoning doesn’t need special chain-of-thought training data, and doesn't produce extra CoT tokens at test time.
We trained on 800B tokens 👇
February 10, 2025 at 3:58 PM
New open source reasoning model!
Huginn-3.5B reasons implicitly in latent space 🧠
Unlike O1 and R1, latent reasoning doesn’t need special chain-of-thought training data, and doesn't produce extra CoT tokens at test time.
We trained on 800B tokens 👇
Huginn-3.5B reasons implicitly in latent space 🧠
Unlike O1 and R1, latent reasoning doesn’t need special chain-of-thought training data, and doesn't produce extra CoT tokens at test time.
We trained on 800B tokens 👇
Reposted by Jonas

Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach 🚀🚀🚀
arxiv.org/abs/2502.05171
arxiv.org/abs/2502.05171

February 10, 2025 at 7:10 AM
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach 🚀🚀🚀
arxiv.org/abs/2502.05171
arxiv.org/abs/2502.05171
I'm at NeurIPS in Vancouver right now! Feel free to reach out to talk about anything in LLM safety or efficiency research.
Also, our new ELLIS institute Tübingen is hiring new faculty, the deadline is next week - reach out to us in person and at our booth for more info 🇪🇺🇪🇺🇪🇺
Also, our new ELLIS institute Tübingen is hiring new faculty, the deadline is next week - reach out to us in person and at our booth for more info 🇪🇺🇪🇺🇪🇺

Principal Investigators (m/f/d) as Hector Endowed Fellows of the ELLIS Institute Tübingen
institute-tue.ellis.eu
December 11, 2024 at 1:36 AM
I'm at NeurIPS in Vancouver right now! Feel free to reach out to talk about anything in LLM safety or efficiency research.
Also, our new ELLIS institute Tübingen is hiring new faculty, the deadline is next week - reach out to us in person and at our booth for more info 🇪🇺🇪🇺🇪🇺
Also, our new ELLIS institute Tübingen is hiring new faculty, the deadline is next week - reach out to us in person and at our booth for more info 🇪🇺🇪🇺🇪🇺