



@klieret.bsky.social
Very cool to see featured in the litellm docs! Litellm has been our default framework to support various models & get accurate cost tracking per API call.

November 26, 2025 at 6:37 PM
Very cool to see featured in the litellm docs! Litellm has been our default framework to support various models & get accurate cost tracking per API call.
Snapshot of the SWE-bench leaderboard: Opus 4.5 reclaims the top, though only narrowly ahead of Gemini 3 which is a lot cheaper. Both models require at least 100 agent steps to get to max performance.

November 26, 2025 at 6:37 PM
Snapshot of the SWE-bench leaderboard: Opus 4.5 reclaims the top, though only narrowly ahead of Gemini 3 which is a lot cheaper. Both models require at least 100 agent steps to get to max performance.
Gemini 3 Pro sets new record on SWE-bench verified: 74%! (evaluated with minimal agent) Costs are 1.6x of GPT-5, but still cheaper than Sonnet 4.5. Gemini iterates longer than everyone; run your agent with a step limit of >100 for max performance. Details & full agent logs in 🧵

November 19, 2025 at 3:36 PM
Gemini 3 Pro sets new record on SWE-bench verified: 74%! (evaluated with minimal agent) Costs are 1.6x of GPT-5, but still cheaper than Sonnet 4.5. Gemini iterates longer than everyone; run your agent with a step limit of >100 for max performance. Details & full agent logs in 🧵
We evaluated Anthropic's Sonnet 4.5 with our minimal agent. New record on SWE-bench verified: 70.6%! Same price/token as Sonnet 4, but takes more steps, ending up being more expensive. Cost analysis details & link to full trajectories in 🧵

September 30, 2025 at 2:49 PM
We evaluated Anthropic's Sonnet 4.5 with our minimal agent. New record on SWE-bench verified: 70.6%! Same price/token as Sonnet 4, but takes more steps, ending up being more expensive. Cost analysis details & link to full trajectories in 🧵
Very cool to see anyscale use mini-swe-agent in their large scale agent runs " because it is extremely simple and hackable and also gives good performance on software engineering problems without extra complexity" www.anyscale.com/blog/massive...

Massively Parallel Agentic Simulations with Ray | Anyscale
Powered by Ray, Anyscale empowers AI builders to run and scale all ML and AI workloads on any cloud and on-prem.
www.anyscale.com
September 11, 2025 at 3:05 AM
Very cool to see anyscale use mini-swe-agent in their large scale agent runs " because it is extremely simple and hackable and also gives good performance on software engineering problems without extra complexity" www.anyscale.com/blog/massive...
Deepseek v3.1 chat scores 53.8% on SWE-bench verified with mini-SWE-agent. Tends to take more steps to solve problems than others (flattens out after some 125 steps). As a result effective cost is somewhere near GPT-5 mini. Details in 🧵

August 21, 2025 at 10:34 PM
Deepseek v3.1 chat scores 53.8% on SWE-bench verified with mini-SWE-agent. Tends to take more steps to solve problems than others (flattens out after some 125 steps). As a result effective cost is somewhere near GPT-5 mini. Details in 🧵
What if your agent uses a different LM at every turn? We let mini-SWE-agent randomly switch between GPT-5 and Sonnet 4 and it scored higher on SWE-bench than with either model separately. Read more in the SWE-bench blog 🧵

August 20, 2025 at 6:02 PM
What if your agent uses a different LM at every turn? We let mini-SWE-agent randomly switch between GPT-5 and Sonnet 4 and it scored higher on SWE-bench than with either model separately. Read more in the SWE-bench blog 🧵
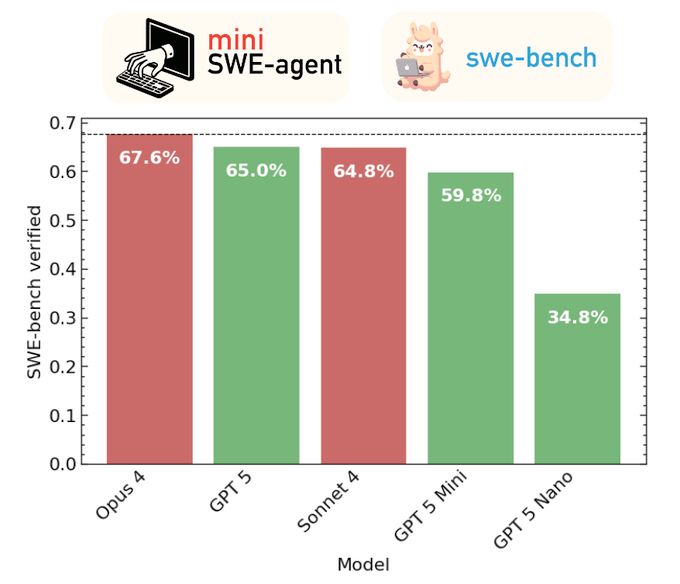
We evaluated the new GPT models with a minimal agent on SWE-bench verified. GPT-5 scores 65%, mini 60%, nano 35%. Still behind Opus 5 (68%), on par with Sonnet 4 (65%). But a lot cheaper, especially mini! Complete cost breakdown + details in 🧵
August 8, 2025 at 3:20 PM
We evaluated the new GPT models with a minimal agent on SWE-bench verified. GPT-5 scores 65%, mini 60%, nano 35%. Still behind Opus 5 (68%), on par with Sonnet 4 (65%). But a lot cheaper, especially mini! Complete cost breakdown + details in 🧵
gpt-5-mini delivers software engineering for very cheap! We're seeing 60% on SWE-bench verified with just $18 total using our bare-bones 100 line agent. That's for solving 299/500 GitHub issues! Very fast, too! (1.5h total with 10 workers)
August 8, 2025 at 4:13 AM
gpt-5-mini delivers software engineering for very cheap! We're seeing 60% on SWE-bench verified with just $18 total using our bare-bones 100 line agent. That's for solving 299/500 GitHub issues! Very fast, too! (1.5h total with 10 workers)
Play with gpt-5 in our minimal agent (guide in the 🧵)! gpt-5 really wants to solve anything in one shot, so some prompting adjustments are needed to have it behave like a proper agent. Still likes to cram in a lot into a single step. Full evals tomorrow!
August 7, 2025 at 9:22 PM
Play with gpt-5 in our minimal agent (guide in the 🧵)! gpt-5 really wants to solve anything in one shot, so some prompting adjustments are needed to have it behave like a proper agent. Still likes to cram in a lot into a single step. Full evals tomorrow!