



Kwang Moo Yi
@kmyid.bsky.social
Assistant Professor of Computer Science at the University of British Columbia. I also post my daily finds on arxiv.
Baek et al., "SONIC: Spectral Optimization of Noise for Inpainting with Consistency"
Initial seed noise matters. And you can optimize it **without** any backprop through your denoiser via good-ol linearization. Importantly, you need to do this in the Fourier space.
Initial seed noise matters. And you can optimize it **without** any backprop through your denoiser via good-ol linearization. Importantly, you need to do this in the Fourier space.
November 26, 2025 at 3:06 AM
Baek et al., "SONIC: Spectral Optimization of Noise for Inpainting with Consistency"
Initial seed noise matters. And you can optimize it **without** any backprop through your denoiser via good-ol linearization. Importantly, you need to do this in the Fourier space.
Initial seed noise matters. And you can optimize it **without** any backprop through your denoiser via good-ol linearization. Importantly, you need to do this in the Fourier space.
Chambon et al., "NAF: Zero-Shot Feature Upsampling via Neighborhood Attention Filtering"
Essentially learning create an upsample kernel via looking at encoded images. Generalizes well to various foundational models. + it beats bicubic upsampling.
Essentially learning create an upsample kernel via looking at encoded images. Generalizes well to various foundational models. + it beats bicubic upsampling.

November 25, 2025 at 9:27 PM
Chambon et al., "NAF: Zero-Shot Feature Upsampling via Neighborhood Attention Filtering"
Essentially learning create an upsample kernel via looking at encoded images. Generalizes well to various foundational models. + it beats bicubic upsampling.
Essentially learning create an upsample kernel via looking at encoded images. Generalizes well to various foundational models. + it beats bicubic upsampling.
Maruani et al., "Illustrator’s Depth: Monocular Layer Index Prediction for Image Decomposition"
Fine-tune a depth estimator to SVG layers for the ordinal depth estimator. Very cute outcomes with highly useful results.
Fine-tune a depth estimator to SVG layers for the ordinal depth estimator. Very cute outcomes with highly useful results.

November 24, 2025 at 8:37 PM
Maruani et al., "Illustrator’s Depth: Monocular Layer Index Prediction for Image Decomposition"
Fine-tune a depth estimator to SVG layers for the ordinal depth estimator. Very cute outcomes with highly useful results.
Fine-tune a depth estimator to SVG layers for the ordinal depth estimator. Very cute outcomes with highly useful results.
SAM 3D Team, "SAM 3D: 3Dfy Anything in Images"
image (point map) + mask -> Transformer -> pose / voxel -> transformer (image/mask/voxel) -> mesh / splat. Staged training with synthetic and real data & RL. I wish I could see more failure examples to know the limits.
image (point map) + mask -> Transformer -> pose / voxel -> transformer (image/mask/voxel) -> mesh / splat. Staged training with synthetic and real data & RL. I wish I could see more failure examples to know the limits.
November 21, 2025 at 8:35 PM
SAM 3D Team, "SAM 3D: 3Dfy Anything in Images"
image (point map) + mask -> Transformer -> pose / voxel -> transformer (image/mask/voxel) -> mesh / splat. Staged training with synthetic and real data & RL. I wish I could see more failure examples to know the limits.
image (point map) + mask -> Transformer -> pose / voxel -> transformer (image/mask/voxel) -> mesh / splat. Staged training with synthetic and real data & RL. I wish I could see more failure examples to know the limits.
Edstedt el al., "RoMa v2: Harder Better Faster Denser Feature Matching"
V2 of RoMA is out :) 1.7x faster with improved performance! Dense feature matching, still outperforms feed-forward 3D methods by a far in outdoor scenarios.
V2 of RoMA is out :) 1.7x faster with improved performance! Dense feature matching, still outperforms feed-forward 3D methods by a far in outdoor scenarios.

November 20, 2025 at 11:05 PM
Edstedt el al., "RoMa v2: Harder Better Faster Denser Feature Matching"
V2 of RoMA is out :) 1.7x faster with improved performance! Dense feature matching, still outperforms feed-forward 3D methods by a far in outdoor scenarios.
V2 of RoMA is out :) 1.7x faster with improved performance! Dense feature matching, still outperforms feed-forward 3D methods by a far in outdoor scenarios.
Chen et al., "Co-Me: Confidence-Guided Token Merging for Visual Geometric Transformers"
Train a confidence predictor for tokens and merge low-confidence ones for acceleration -> faster reconstruction with VGGT/MapAnything.
Train a confidence predictor for tokens and merge low-confidence ones for acceleration -> faster reconstruction with VGGT/MapAnything.
November 19, 2025 at 8:40 PM
Chen et al., "Co-Me: Confidence-Guided Token Merging for Visual Geometric Transformers"
Train a confidence predictor for tokens and merge low-confidence ones for acceleration -> faster reconstruction with VGGT/MapAnything.
Train a confidence predictor for tokens and merge low-confidence ones for acceleration -> faster reconstruction with VGGT/MapAnything.
Vecchio et al, "Φeat: Physically-Grounded Feature Representation"
Foundational backbone, finetuned DINOv3, trained with synthetic renders of materials, EMA student-teacher training with multiple losses.
Foundational backbone, finetuned DINOv3, trained with synthetic renders of materials, EMA student-teacher training with multiple losses.

November 18, 2025 at 8:18 PM
Vecchio et al, "Φeat: Physically-Grounded Feature Representation"
Foundational backbone, finetuned DINOv3, trained with synthetic renders of materials, EMA student-teacher training with multiple losses.
Foundational backbone, finetuned DINOv3, trained with synthetic renders of materials, EMA student-teacher training with multiple losses.
Wu et al., "Equivariant Sampling for Improving Diffusion Model-based Image Restoration"
Very simple idea -- for inverse problems, you can introduce equivariant augmentations which do not change the solution, and find a solution that matches everything. Augmentation in denoising.
Very simple idea -- for inverse problems, you can introduce equivariant augmentations which do not change the solution, and find a solution that matches everything. Augmentation in denoising.

November 17, 2025 at 8:19 PM
Wu et al., "Equivariant Sampling for Improving Diffusion Model-based Image Restoration"
Very simple idea -- for inverse problems, you can introduce equivariant augmentations which do not change the solution, and find a solution that matches everything. Augmentation in denoising.
Very simple idea -- for inverse problems, you can introduce equivariant augmentations which do not change the solution, and find a solution that matches everything. Augmentation in denoising.
Lin and Chen and Liew and Chen, et al., and Kang "Depth Anything 3: Recovering the Visual Space from Any Views"
VGGT-like architecture, but simplified to estimate depth and ray maps (not point maps). Uses teacher-student training of Depth Anything v2.
VGGT-like architecture, but simplified to estimate depth and ray maps (not point maps). Uses teacher-student training of Depth Anything v2.
November 14, 2025 at 9:25 PM
Lin and Chen and Liew and Chen, et al., and Kang "Depth Anything 3: Recovering the Visual Space from Any Views"
VGGT-like architecture, but simplified to estimate depth and ray maps (not point maps). Uses teacher-student training of Depth Anything v2.
VGGT-like architecture, but simplified to estimate depth and ray maps (not point maps). Uses teacher-student training of Depth Anything v2.
Singer and Rotstein et al., "Time-to-Move: Training-Free Motion Controlled Video Generation via Dual-Clock Denoising"
Make a rough warp, push it through Image-to-Video model with denoise together up until a timestep, then let it finish the rest without interference.
Make a rough warp, push it through Image-to-Video model with denoise together up until a timestep, then let it finish the rest without interference.
November 13, 2025 at 7:54 PM
Singer and Rotstein et al., "Time-to-Move: Training-Free Motion Controlled Video Generation via Dual-Clock Denoising"
Make a rough warp, push it through Image-to-Video model with denoise together up until a timestep, then let it finish the rest without interference.
Make a rough warp, push it through Image-to-Video model with denoise together up until a timestep, then let it finish the rest without interference.
Yang et al., "UltraGS: Gaussian Splatting for Ultrasound Novel View Synthesis"
3D Gaussian Splatting for Ultrasounds. Tailored parameterization and Field-of-view adaptation for Ultrasound use cases.
3D Gaussian Splatting for Ultrasounds. Tailored parameterization and Field-of-view adaptation for Ultrasound use cases.

November 12, 2025 at 9:56 PM
Yang et al., "UltraGS: Gaussian Splatting for Ultrasound Novel View Synthesis"
3D Gaussian Splatting for Ultrasounds. Tailored parameterization and Field-of-view adaptation for Ultrasound use cases.
3D Gaussian Splatting for Ultrasounds. Tailored parameterization and Field-of-view adaptation for Ultrasound use cases.
Gutflaish and Kachlon et al., "Generating an Image From 1,000 Words: Enhancing Text-to-Image With Structured Captions"
Is all you need just very good captioning? Makes a lot of sense given that this makes your problem closer to a 1-to-1 mapping instead of many-to-1.
Is all you need just very good captioning? Makes a lot of sense given that this makes your problem closer to a 1-to-1 mapping instead of many-to-1.

November 11, 2025 at 6:45 PM
Gutflaish and Kachlon et al., "Generating an Image From 1,000 Words: Enhancing Text-to-Image With Structured Captions"
Is all you need just very good captioning? Makes a lot of sense given that this makes your problem closer to a 1-to-1 mapping instead of many-to-1.
Is all you need just very good captioning? Makes a lot of sense given that this makes your problem closer to a 1-to-1 mapping instead of many-to-1.
Wang et al., "Seeds of Structure: Patch PCA Reveals Universal Compositional Cues in Diffusion Models"
The existence of single (few) step denoisers, and many recent works hinted at this, but another one. You can decode the image structure from the initial noise fairly easily.
The existence of single (few) step denoisers, and many recent works hinted at this, but another one. You can decode the image structure from the initial noise fairly easily.

November 10, 2025 at 7:42 PM
Wang et al., "Seeds of Structure: Patch PCA Reveals Universal Compositional Cues in Diffusion Models"
The existence of single (few) step denoisers, and many recent works hinted at this, but another one. You can decode the image structure from the initial noise fairly easily.
The existence of single (few) step denoisers, and many recent works hinted at this, but another one. You can decode the image structure from the initial noise fairly easily.
Ren and Wen et al., "FastGS: Training 3D Gaussian Splatting in 100 Seconds"
I like simple ideas -- this one says you should consider multiple views when you prune/clone, which allows fewer Gaussians to be used for training.
I like simple ideas -- this one says you should consider multiple views when you prune/clone, which allows fewer Gaussians to be used for training.
November 7, 2025 at 6:32 PM
Ren and Wen et al., "FastGS: Training 3D Gaussian Splatting in 100 Seconds"
I like simple ideas -- this one says you should consider multiple views when you prune/clone, which allows fewer Gaussians to be used for training.
I like simple ideas -- this one says you should consider multiple views when you prune/clone, which allows fewer Gaussians to be used for training.
Nguyen et al., "IBGS: Image-Based Gaussian Splatting"
Gaussian Splatting + Image-based rendering (ie, copy things over directly from nearby views). When your Gaussians cannot describe highlights, let your nearby images guide you.
Gaussian Splatting + Image-based rendering (ie, copy things over directly from nearby views). When your Gaussians cannot describe highlights, let your nearby images guide you.

November 6, 2025 at 9:45 PM
Nguyen et al., "IBGS: Image-Based Gaussian Splatting"
Gaussian Splatting + Image-based rendering (ie, copy things over directly from nearby views). When your Gaussians cannot describe highlights, let your nearby images guide you.
Gaussian Splatting + Image-based rendering (ie, copy things over directly from nearby views). When your Gaussians cannot describe highlights, let your nearby images guide you.
Gao and Mao et al., "Seeing the Wind from a Falling Leaf"
Extract Dynamic 3D Gaussians for an object -> Vision Language Models to extract physics parameters -> model force field (wind). Leads to some fun.
Extract Dynamic 3D Gaussians for an object -> Vision Language Models to extract physics parameters -> model force field (wind). Leads to some fun.
November 5, 2025 at 5:31 PM
Gao and Mao et al., "Seeing the Wind from a Falling Leaf"
Extract Dynamic 3D Gaussians for an object -> Vision Language Models to extract physics parameters -> model force field (wind). Leads to some fun.
Extract Dynamic 3D Gaussians for an object -> Vision Language Models to extract physics parameters -> model force field (wind). Leads to some fun.
Zhou et al., "PAGE-4D: Disentangled Pose and Geometry Estimation for 4D Perception"
VGGT extended to dynamic scenes with a dynamic mask predictor.
VGGT extended to dynamic scenes with a dynamic mask predictor.
November 4, 2025 at 8:17 PM
Zhou et al., "PAGE-4D: Disentangled Pose and Geometry Estimation for 4D Perception"
VGGT extended to dynamic scenes with a dynamic mask predictor.
VGGT extended to dynamic scenes with a dynamic mask predictor.
Pfrommer et al., "Is Your Diffusion Model Actually Denoising?"
Apparently no. This indeed matches the empirical behavior of these models that I experienced. These models are approximate, but then what actually is their mathematical property?
Apparently no. This indeed matches the empirical behavior of these models that I experienced. These models are approximate, but then what actually is their mathematical property?

November 3, 2025 at 7:28 PM
Pfrommer et al., "Is Your Diffusion Model Actually Denoising?"
Apparently no. This indeed matches the empirical behavior of these models that I experienced. These models are approximate, but then what actually is their mathematical property?
Apparently no. This indeed matches the empirical behavior of these models that I experienced. These models are approximate, but then what actually is their mathematical property?
Tesfaldet et al., "Generative Point Tracking with Flow Matching"
Tracking, waaaaaay back in the days, used to be solved using sampling methods. They are now back. Also reminds me of my first major conference work, where I looked into how much impact the initial target point has.
Tracking, waaaaaay back in the days, used to be solved using sampling methods. They are now back. Also reminds me of my first major conference work, where I looked into how much impact the initial target point has.
October 31, 2025 at 6:42 PM
Tesfaldet et al., "Generative Point Tracking with Flow Matching"
Tracking, waaaaaay back in the days, used to be solved using sampling methods. They are now back. Also reminds me of my first major conference work, where I looked into how much impact the initial target point has.
Tracking, waaaaaay back in the days, used to be solved using sampling methods. They are now back. Also reminds me of my first major conference work, where I looked into how much impact the initial target point has.
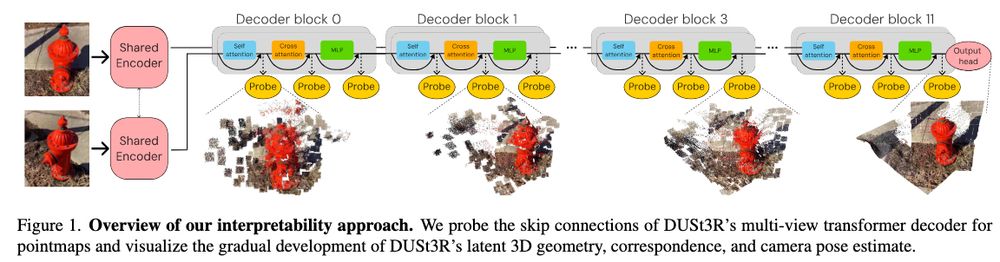
Stary and Gaubil et al., "Understanding multi-view transformers"
We use Dust3r as a black box. This work looks under the hood at what is going on. The internal representations seem to "iteratively" refine towards the final answer. Quite similar to what goes on in point cloud net
We use Dust3r as a black box. This work looks under the hood at what is going on. The internal representations seem to "iteratively" refine towards the final answer. Quite similar to what goes on in point cloud net
October 30, 2025 at 9:00 PM
Stary and Gaubil et al., "Understanding multi-view transformers"
We use Dust3r as a black box. This work looks under the hood at what is going on. The internal representations seem to "iteratively" refine towards the final answer. Quite similar to what goes on in point cloud net
We use Dust3r as a black box. This work looks under the hood at what is going on. The internal representations seem to "iteratively" refine towards the final answer. Quite similar to what goes on in point cloud net
Goren and Yehezkel et al., "Visual Diffusion Models are Geometric Solvers"
Note: this paper does not claim that diffusion models are better; in fact, specialized models are. Just shows the potential that you can use diffusion models to solve geometric problems.
Note: this paper does not claim that diffusion models are better; in fact, specialized models are. Just shows the potential that you can use diffusion models to solve geometric problems.

October 29, 2025 at 9:28 PM
Goren and Yehezkel et al., "Visual Diffusion Models are Geometric Solvers"
Note: this paper does not claim that diffusion models are better; in fact, specialized models are. Just shows the potential that you can use diffusion models to solve geometric problems.
Note: this paper does not claim that diffusion models are better; in fact, specialized models are. Just shows the potential that you can use diffusion models to solve geometric problems.
Luo et al., "Self-diffusion for Solving Inverse Problems"
Pretty much a deep image prior for denoising models. Without ANY data, with a single image, you can train a denoiser via diffusion training, and it just magically learns to solve inverse problems.
Pretty much a deep image prior for denoising models. Without ANY data, with a single image, you can train a denoiser via diffusion training, and it just magically learns to solve inverse problems.

October 27, 2025 at 6:59 PM
Luo et al., "Self-diffusion for Solving Inverse Problems"
Pretty much a deep image prior for denoising models. Without ANY data, with a single image, you can train a denoiser via diffusion training, and it just magically learns to solve inverse problems.
Pretty much a deep image prior for denoising models. Without ANY data, with a single image, you can train a denoiser via diffusion training, and it just magically learns to solve inverse problems.
Bai et al., "Positional Encoding Field"
Make your RoPE encoding 3D by including a z axis, then manipulate your image by simply manipulating your positional encoding in 3D --> novel view synthesis. Neat idea.
Make your RoPE encoding 3D by including a z axis, then manipulate your image by simply manipulating your positional encoding in 3D --> novel view synthesis. Neat idea.
October 24, 2025 at 6:20 PM
Bai et al., "Positional Encoding Field"
Make your RoPE encoding 3D by including a z axis, then manipulate your image by simply manipulating your positional encoding in 3D --> novel view synthesis. Neat idea.
Make your RoPE encoding 3D by including a z axis, then manipulate your image by simply manipulating your positional encoding in 3D --> novel view synthesis. Neat idea.
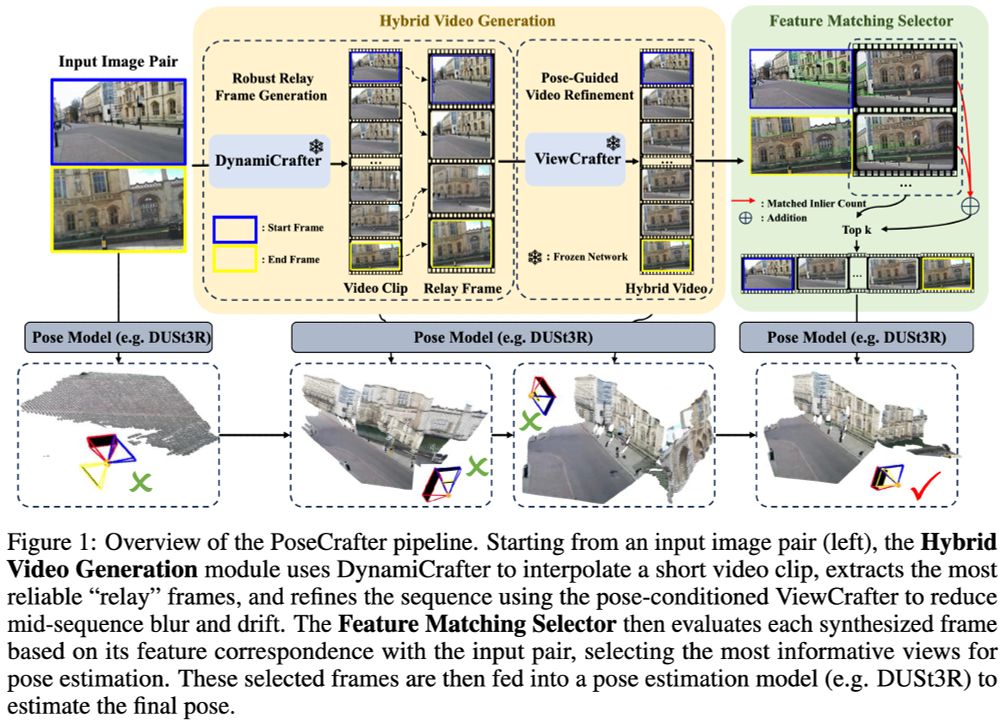
Mao et al., "PoseCrafter: Extreme Pose Estimation with
Hybrid Video Synthesis"
While not perfect, video models do an okay job of creating novel views. Use them to "bridge" between extreme views for pose estimation.
Hybrid Video Synthesis"
While not perfect, video models do an okay job of creating novel views. Use them to "bridge" between extreme views for pose estimation.
October 23, 2025 at 6:48 PM
Mao et al., "PoseCrafter: Extreme Pose Estimation with
Hybrid Video Synthesis"
While not perfect, video models do an okay job of creating novel views. Use them to "bridge" between extreme views for pose estimation.
Hybrid Video Synthesis"
While not perfect, video models do an okay job of creating novel views. Use them to "bridge" between extreme views for pose estimation.
Choudhury and Kim et al., "Accelerating Vision Transformers With Adaptive Patch Sizes"
Transformer patches don't need to be of uniform size -- choose sizes based on entropy --> faster training/inference. Are scale-spaces gonna make a comeback?
Transformer patches don't need to be of uniform size -- choose sizes based on entropy --> faster training/inference. Are scale-spaces gonna make a comeback?
October 22, 2025 at 8:08 PM
Choudhury and Kim et al., "Accelerating Vision Transformers With Adaptive Patch Sizes"
Transformer patches don't need to be of uniform size -- choose sizes based on entropy --> faster training/inference. Are scale-spaces gonna make a comeback?
Transformer patches don't need to be of uniform size -- choose sizes based on entropy --> faster training/inference. Are scale-spaces gonna make a comeback?