




Lennart Purucker
@lennartpurucker.bsky.social
PhD student sup. by Frank Hutter; researching automated machine learning and foundation models for (small) tabular data!
Website: https://ml.informatik.uni-freiburg.de/profile/purucker/
Website: https://ml.informatik.uni-freiburg.de/profile/purucker/
Pinned
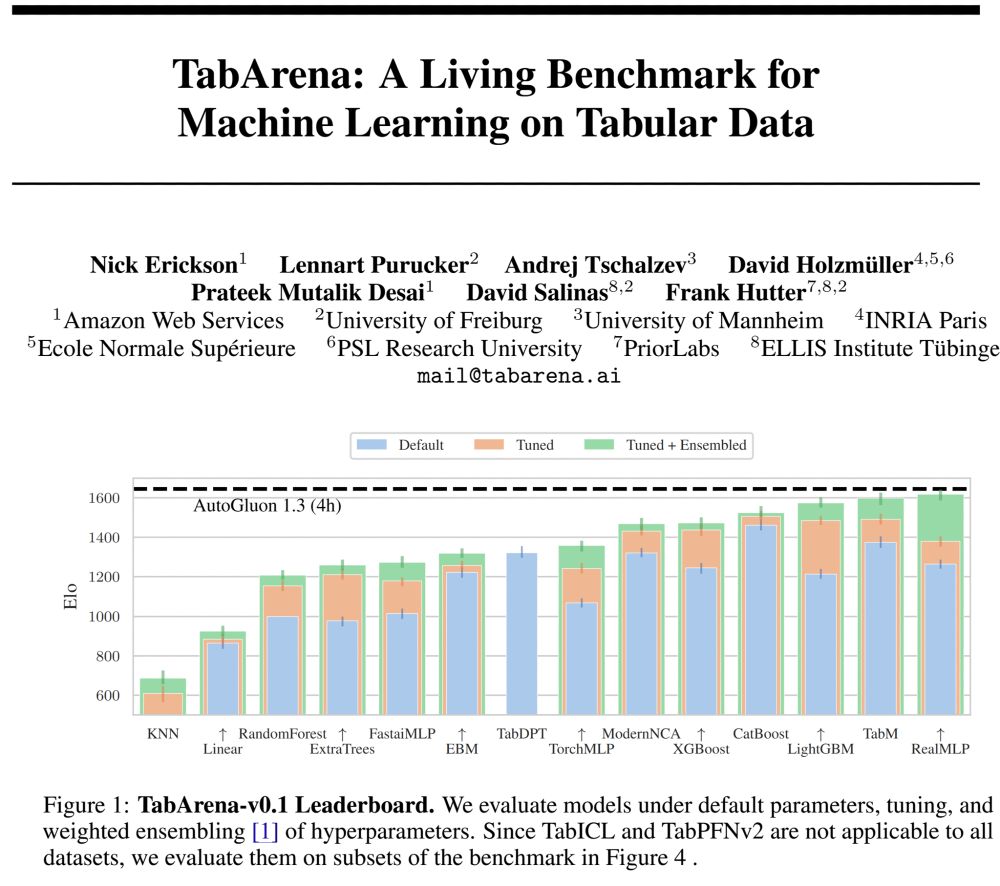
🚨What is SOTA on tabular data, really? We are excited to announce 𝗧𝗮𝗯𝗔𝗿𝗲𝗻𝗮, a living benchmark for machine learning on IID tabular data with:
📊 an online leaderboard (submit!)
📑 carefully curated datasets
📈 strong tree-based, deep learning, and foundation models
🧵
📊 an online leaderboard (submit!)
📑 carefully curated datasets
📈 strong tree-based, deep learning, and foundation models
🧵
Reposted by Lennart Purucker

🚀 Excited to announce the AI for Tabular Data workshop at EurIPS 2025 in Copenhagen!
CfP: sites.google.com/view/eurips2... (papers due 20 Oct)
Join us @euripsconf.bsky.social to discuss neural tabular models and systems for predictive ML, tabular reasoning and retrieval, table synthesis and more ✨
CfP: sites.google.com/view/eurips2... (papers due 20 Oct)
Join us @euripsconf.bsky.social to discuss neural tabular models and systems for predictive ML, tabular reasoning and retrieval, table synthesis and more ✨

September 23, 2025 at 10:44 AM
🚀 Excited to announce the AI for Tabular Data workshop at EurIPS 2025 in Copenhagen!
CfP: sites.google.com/view/eurips2... (papers due 20 Oct)
Join us @euripsconf.bsky.social to discuss neural tabular models and systems for predictive ML, tabular reasoning and retrieval, table synthesis and more ✨
CfP: sites.google.com/view/eurips2... (papers due 20 Oct)
Join us @euripsconf.bsky.social to discuss neural tabular models and systems for predictive ML, tabular reasoning and retrieval, table synthesis and more ✨
Reposted by Lennart Purucker

Very proud our paper "OpenML: Insights from 10 years and more than a thousand papers" that describes the current state of OpenML and also analyzes the impact OpenML had over the last years (yes, we manually looked at every paper citing OpenML). #openml #automl #openscience 1/4
July 7, 2025 at 12:15 PM
Very proud our paper "OpenML: Insights from 10 years and more than a thousand papers" that describes the current state of OpenML and also analyzes the impact OpenML had over the last years (yes, we manually looked at every paper citing OpenML). #openml #automl #openscience 1/4
🚨What is SOTA on tabular data, really? We are excited to announce 𝗧𝗮𝗯𝗔𝗿𝗲𝗻𝗮, a living benchmark for machine learning on IID tabular data with:
📊 an online leaderboard (submit!)
📑 carefully curated datasets
📈 strong tree-based, deep learning, and foundation models
🧵
📊 an online leaderboard (submit!)
📑 carefully curated datasets
📈 strong tree-based, deep learning, and foundation models
🧵
June 23, 2025 at 10:15 AM
🚨What is SOTA on tabular data, really? We are excited to announce 𝗧𝗮𝗯𝗔𝗿𝗲𝗻𝗮, a living benchmark for machine learning on IID tabular data with:
📊 an online leaderboard (submit!)
📑 carefully curated datasets
📈 strong tree-based, deep learning, and foundation models
🧵
📊 an online leaderboard (submit!)
📑 carefully curated datasets
📈 strong tree-based, deep learning, and foundation models
🧵
Reposted by Lennart Purucker

We are excited to announce #FMSD: "1st Workshop on Foundation Models for Structured Data" has been accepted to #ICML 2025!
Call for Papers: icml-structured-fm-workshop.github.io
Call for Papers: icml-structured-fm-workshop.github.io

March 25, 2025 at 5:59 PM
We are excited to announce #FMSD: "1st Workshop on Foundation Models for Structured Data" has been accepted to #ICML 2025!
Call for Papers: icml-structured-fm-workshop.github.io
Call for Papers: icml-structured-fm-workshop.github.io
The tabular foundation model TabPFN v2 is finally public 🎉🥳
This is excellent news for (small) tabular ML! Checkout our Nature article (nature.com/articles/s41...) and code (github.com/PriorLabs/Ta...)
This is excellent news for (small) tabular ML! Checkout our Nature article (nature.com/articles/s41...) and code (github.com/PriorLabs/Ta...)

January 9, 2025 at 8:33 AM
The tabular foundation model TabPFN v2 is finally public 🎉🥳
This is excellent news for (small) tabular ML! Checkout our Nature article (nature.com/articles/s41...) and code (github.com/PriorLabs/Ta...)
This is excellent news for (small) tabular ML! Checkout our Nature article (nature.com/articles/s41...) and code (github.com/PriorLabs/Ta...)
Excited to be at #NeurIPS2024 tomorrow! 🎉 Let’s connect if you are interested in tabular data and:
🤖 AutoML (e.g., AutoGluon)
📊 Data Science (e.g., LLMs for Feature Engineering)
🏛️ Foundation Models (e.g., TabPFN)
Looking forward to insightful discussions—feel free to reach out!
🤖 AutoML (e.g., AutoGluon)
📊 Data Science (e.g., LLMs for Feature Engineering)
🏛️ Foundation Models (e.g., TabPFN)
Looking forward to insightful discussions—feel free to reach out!
December 9, 2024 at 1:32 PM
Excited to be at #NeurIPS2024 tomorrow! 🎉 Let’s connect if you are interested in tabular data and:
🤖 AutoML (e.g., AutoGluon)
📊 Data Science (e.g., LLMs for Feature Engineering)
🏛️ Foundation Models (e.g., TabPFN)
Looking forward to insightful discussions—feel free to reach out!
🤖 AutoML (e.g., AutoGluon)
📊 Data Science (e.g., LLMs for Feature Engineering)
🏛️ Foundation Models (e.g., TabPFN)
Looking forward to insightful discussions—feel free to reach out!
AutoGluon 1.2 is now public! Some highlights for tabular data:
1. 70% win-rate vs version 1.1.
2. TabPFNMix foundation model, parallel fit
3. AutoGluon-Assistant: Zero-code ML with LLMs.
Also, very cool improvements for TimeSeries related to Chronos!
#AutoML #TabularData
1. 70% win-rate vs version 1.1.
2. TabPFNMix foundation model, parallel fit
3. AutoGluon-Assistant: Zero-code ML with LLMs.
Also, very cool improvements for TimeSeries related to Chronos!
#AutoML #TabularData

Release v1.2.0 · autogluon/autogluon
Version 1.2.0
We're happy to announce the AutoGluon 1.2.0 release.
AutoGluon 1.2 contains massive improvements to both Tabular and TimeSeries modules, each achieving a 70% win-rate vs AutoGluon 1.1...
github.com
November 27, 2024 at 8:40 PM
AutoGluon 1.2 is now public! Some highlights for tabular data:
1. 70% win-rate vs version 1.1.
2. TabPFNMix foundation model, parallel fit
3. AutoGluon-Assistant: Zero-code ML with LLMs.
Also, very cool improvements for TimeSeries related to Chronos!
#AutoML #TabularData
1. 70% win-rate vs version 1.1.
2. TabPFNMix foundation model, parallel fit
3. AutoGluon-Assistant: Zero-code ML with LLMs.
Also, very cool improvements for TimeSeries related to Chronos!
#AutoML #TabularData
Reposted by Lennart Purucker

Okay, okay, @theeimer.bsky.social , here you go: the beginning of an #AutoML starter pack
-->happy to add AutoML folks and friends, just reply/PN to suggest yourself or others
go.bsky.app/5PnMDUK
-->happy to add AutoML folks and friends, just reply/PN to suggest yourself or others
go.bsky.app/5PnMDUK
November 23, 2024 at 9:08 PM
Okay, okay, @theeimer.bsky.social , here you go: the beginning of an #AutoML starter pack
-->happy to add AutoML folks and friends, just reply/PN to suggest yourself or others
go.bsky.app/5PnMDUK
-->happy to add AutoML folks and friends, just reply/PN to suggest yourself or others
go.bsky.app/5PnMDUK