



Shang Qu
@lindsayttsq.bsky.social
AI4Biomed & LLMs @ Tsinghua University
📝We've released the MedXpertQA dataset!
huggingface.co/datasets/Tsi...
📚Check out more details:
Preprint: arxiv.org/pdf/2501.18362
Github: github.com/TsinghuaC3I/...
huggingface.co/datasets/Tsi...
📚Check out more details:
Preprint: arxiv.org/pdf/2501.18362
Github: github.com/TsinghuaC3I/...
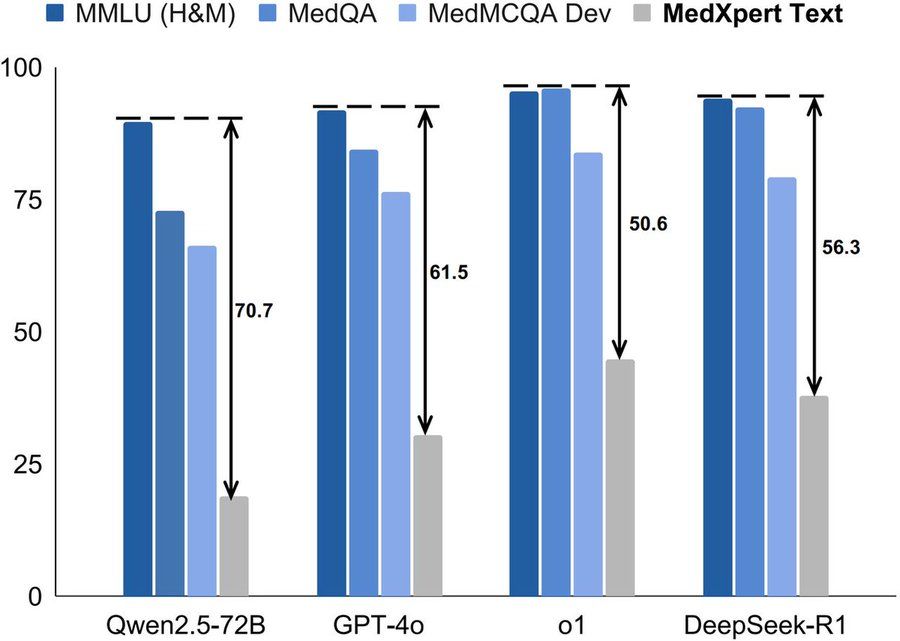
📈How far are leading models from mastering realistic medical tasks? MedXpertQA, our new text & multimodal medical benchmark, reveals gaps in model abilities
📌Percentage scores on our Text subset:
o3-mini: 37.30
R1: 37.76 - frontrunner among open-source models
o1: 44.67 - still room for improvement!
📌Percentage scores on our Text subset:
o3-mini: 37.30
R1: 37.76 - frontrunner among open-source models
o1: 44.67 - still room for improvement!
February 9, 2025 at 2:19 AM
📝We've released the MedXpertQA dataset!
huggingface.co/datasets/Tsi...
📚Check out more details:
Preprint: arxiv.org/pdf/2501.18362
Github: github.com/TsinghuaC3I/...
huggingface.co/datasets/Tsi...
📚Check out more details:
Preprint: arxiv.org/pdf/2501.18362
Github: github.com/TsinghuaC3I/...
📈How far are leading models from mastering realistic medical tasks? MedXpertQA, our new text & multimodal medical benchmark, reveals gaps in model abilities
📌Percentage scores on our Text subset:
o3-mini: 37.30
R1: 37.76 - frontrunner among open-source models
o1: 44.67 - still room for improvement!
📌Percentage scores on our Text subset:
o3-mini: 37.30
R1: 37.76 - frontrunner among open-source models
o1: 44.67 - still room for improvement!
February 4, 2025 at 1:29 PM
📈How far are leading models from mastering realistic medical tasks? MedXpertQA, our new text & multimodal medical benchmark, reveals gaps in model abilities
📌Percentage scores on our Text subset:
o3-mini: 37.30
R1: 37.76 - frontrunner among open-source models
o1: 44.67 - still room for improvement!
📌Percentage scores on our Text subset:
o3-mini: 37.30
R1: 37.76 - frontrunner among open-source models
o1: 44.67 - still room for improvement!