



Marco Slot
@marcoslot.com
Mostly posts about PostgreSQL, Snowflake Postgres, and PostgreSQL extensions.
Formerly Crunchy Data, Microsoft, Citus Data, AWS, TCD, VU
Formerly Crunchy Data, Microsoft, Citus Data, AWS, TCD, VU
Pinned
Marco Slot
@marcoslot.com
· Nov 20
Announcing Crunchy Data Warehouse! A next-generation Postgres-native data warehouse that provides full Iceberg support for fast analytical queries and transactions.Read more in our announcement. www.crunchydata.com/blog/crunchy...

Crunchy Data Warehouse: Postgres with Iceberg for High Performance Analytics | Crunchy Data Blog
We are excited to release Crunchy Data Warehouse, a modern data warehouse for Postgres. Crunchy Data Warehouse combines Postgres with Iceberg, Parquet, and data lake formats for fast analytics queries...
www.crunchydata.com
About a year ago, we set out to build a modern Postgres data warehouse at Crunchy Data.
Our principles were:
- Most data lives in S3
- @duckdb.org has the best query engine
- Iceberg will be the dominant table format
- No compromise on Postgres features
So, we built Crunchy Data Warehouse.
1/n
Our principles were:
- Most data lives in S3
- @duckdb.org has the best query engine
- Iceberg will be the dominant table format
- No compromise on Postgres features
So, we built Crunchy Data Warehouse.
1/n
Reposted by Marco Slot

Next Tuesday @marcoslot.com will be at Postgres Meetup for * to talk about pg_lake - #Postgres for #Iceberg with #DuckDB.
Join us!
www.meetup.com/postgres-mee...
Join us!
www.meetup.com/postgres-mee...

Postgres for the lakehouse: pg_lake, Tue, Jan 13, 2026, 12:00 PM | Meetup
Marco Slot will be here this month to talk about the new extension pg_lake that connects Postgres to lakehouse and object storage - for Iceberg, Parquet, csv and more.
As
www.meetup.com
January 9, 2026 at 3:02 PM
Next Tuesday @marcoslot.com will be at Postgres Meetup for * to talk about pg_lake - #Postgres for #Iceberg with #DuckDB.
Join us!
www.meetup.com/postgres-mee...
Join us!
www.meetup.com/postgres-mee...
pg_lake just went open source! (Apache 2.0)
pg_lake is a set of extensions (from Crunchy Data Warehouse) that add comprehensive Iceberg support and data lake access to Postgres, with @duckdb.org transparently integrated into the query engine.
Announcement blog: www.snowflake.com/en/engineeri...
pg_lake is a set of extensions (from Crunchy Data Warehouse) that add comprehensive Iceberg support and data lake access to Postgres, with @duckdb.org transparently integrated into the query engine.
Announcement blog: www.snowflake.com/en/engineeri...

November 4, 2025 at 4:04 PM
pg_lake just went open source! (Apache 2.0)
pg_lake is a set of extensions (from Crunchy Data Warehouse) that add comprehensive Iceberg support and data lake access to Postgres, with @duckdb.org transparently integrated into the query engine.
Announcement blog: www.snowflake.com/en/engineeri...
pg_lake is a set of extensions (from Crunchy Data Warehouse) that add comprehensive Iceberg support and data lake access to Postgres, with @duckdb.org transparently integrated into the query engine.
Announcement blog: www.snowflake.com/en/engineeri...
Reposted by Marco Slot

No system hits the sweet spot of allowing for extensibility while maintaining systems safety. It would be nice if there was a standard plugin API (think POSIX) that allows compatibility across systems.
Thanks to @marcoslot.com + @daveandersen.bsky.social for their collaboration on this project
Thanks to @marcoslot.com + @daveandersen.bsky.social for their collaboration on this project

July 3, 2025 at 7:03 PM
No system hits the sweet spot of allowing for extensibility while maintaining systems safety. It would be nice if there was a standard plugin API (think POSIX) that allows compatibility across systems.
Thanks to @marcoslot.com + @daveandersen.bsky.social for their collaboration on this project
Thanks to @marcoslot.com + @daveandersen.bsky.social for their collaboration on this project
Reposted by Marco Slot
At last @abigalekim.bsky.social's paper is out! Its the most complete eval of DB extensions/plugins ever. We analyze PostgreSQL, MySQL, MariaDB, SQLite, DuckDB, Redis.
TLDR: Postgres extns ecosystem is fraught with footguns. Other DBMSs have fewer extns but less problems. DuckDB has cleanest API.
TLDR: Postgres extns ecosystem is fraught with footguns. Other DBMSs have fewer extns but less problems. DuckDB has cleanest API.

Vol:18 No:6 → Anarchy in the Database: A Survey and Evaluation of Database Management System Extensibility
👥 Authors: Abigale Kim, Marco Slot, David Andersen, Andrew Pavlo
📄 PDF: https://www.vldb.org/pvldb/vol18/p1962-kim.pdf
👥 Authors: Abigale Kim, Marco Slot, David Andersen, Andrew Pavlo
📄 PDF: https://www.vldb.org/pvldb/vol18/p1962-kim.pdf

July 3, 2025 at 7:03 PM
At last @abigalekim.bsky.social's paper is out! Its the most complete eval of DB extensions/plugins ever. We analyze PostgreSQL, MySQL, MariaDB, SQLite, DuckDB, Redis.
TLDR: Postgres extns ecosystem is fraught with footguns. Other DBMSs have fewer extns but less problems. DuckDB has cleanest API.
TLDR: Postgres extns ecosystem is fraught with footguns. Other DBMSs have fewer extns but less problems. DuckDB has cleanest API.
Reposted by Marco Slot

Five years ago I joined @crunchydata.com, shortly after I wrote about having unfinished business with Postgres. Today as part of Snowflake that journey is continuing. We've built some amazing things, but are just getting started.
www.crunchydata.com/blog/crunchy...
www.crunchydata.com/blog/crunchy...
Crunchy Data Joins Snowflake | Crunchy Data Blog
We are excited to announce that Crunchy Data is joining Snowflake to bring Postgres to the AI Data Cloud.
www.crunchydata.com
June 2, 2025 at 8:44 PM
Five years ago I joined @crunchydata.com, shortly after I wrote about having unfinished business with Postgres. Today as part of Snowflake that journey is continuing. We've built some amazing things, but are just getting started.
www.crunchydata.com/blog/crunchy...
www.crunchydata.com/blog/crunchy...
Recording of my Data Council talk:
www.youtube.com/watch?v=HZAr...
www.youtube.com/watch?v=HZAr...

Converging Database Architectures DuckDB in PostgreSQL
YouTube video by Data Council
www.youtube.com
May 29, 2025 at 9:18 PM
Recording of my Data Council talk:
www.youtube.com/watch?v=HZAr...
www.youtube.com/watch?v=HZAr...
Generative AI comes up with details that would be hilarious, if it wasn't so mind boggling that it can come up with these details.
May 4, 2025 at 9:33 PM
Generative AI comes up with details that would be hilarious, if it wasn't so mind boggling that it can come up with these details.
And there it is: Native logical replication from any Postgres server to Iceberg managed by Crunchy Data Warehouse.
Speed up Postgres analytical queries 100x with 2 commands.
Speed up Postgres analytical queries 100x with 2 commands.
April 22, 2025 at 2:48 PM
And there it is: Native logical replication from any Postgres server to Iceberg managed by Crunchy Data Warehouse.
Speed up Postgres analytical queries 100x with 2 commands.
Speed up Postgres analytical queries 100x with 2 commands.
I gave a talk at the inaugural (and awesome) European Iceberg meetup in Amsterdam last night.
It's an introduction to how and why we used Iceberg and DuckDB to build a Postgres Data Warehouse:
www.youtube.com/watch?v=cEnq...
It's an introduction to how and why we used Iceberg and DuckDB to build a Postgres Data Warehouse:
www.youtube.com/watch?v=cEnq...

Building a Postgres Data Warehouse with Iceberg
YouTube video by Apache Iceberg™ Meetup
www.youtube.com
April 3, 2025 at 9:58 PM
I gave a talk at the inaugural (and awesome) European Iceberg meetup in Amsterdam last night.
It's an introduction to how and why we used Iceberg and DuckDB to build a Postgres Data Warehouse:
www.youtube.com/watch?v=cEnq...
It's an introduction to how and why we used Iceberg and DuckDB to build a Postgres Data Warehouse:
www.youtube.com/watch?v=cEnq...
Move fast and build solid solutions that work across platforms.
You can now use Postgres as a modern Data Warehouse anywhere, using any S3-compatible storage API. Query, import, or export files in your data lake or store data in Iceberg with automatic maintenance and very fast queries.
You can now use Postgres as a modern Data Warehouse anywhere, using any S3-compatible storage API. Query, import, or export files in your data lake or store data in Iceberg with automatic maintenance and very fast queries.
Excited to announce Crunchy Data Warehouse is now available for Kubernetes and On-premises. Need faster analytics from Postgres? Want a native Postgres data lake experience? Learn more about how it works: www.crunchydata.com/blog/crunchy...

Crunchy Data Warehouse: Postgres with Iceberg Available for Kubernetes and On-premises | Crunchy Data Blog
Crunchy Data brings Postgres-native Apache Iceberg to Kubernetes and on-prem workloads.
www.crunchydata.com
April 1, 2025 at 5:10 PM
Move fast and build solid solutions that work across platforms.
You can now use Postgres as a modern Data Warehouse anywhere, using any S3-compatible storage API. Query, import, or export files in your data lake or store data in Iceberg with automatic maintenance and very fast queries.
You can now use Postgres as a modern Data Warehouse anywhere, using any S3-compatible storage API. Query, import, or export files in your data lake or store data in Iceberg with automatic maintenance and very fast queries.
Reposted by Marco Slot

Excited to announce Crunchy Data Warehouse is now available for Kubernetes and On-premises. Need faster analytics from Postgres? Want a native Postgres data lake experience? Learn more about how it works: www.crunchydata.com/blog/crunchy...
Crunchy Data Warehouse: Postgres with Iceberg Available for Kubernetes and On-premises | Crunchy Data Blog
Crunchy Data brings Postgres-native Apache Iceberg to Kubernetes and on-prem workloads.
www.crunchydata.com
April 1, 2025 at 3:56 PM
Excited to announce Crunchy Data Warehouse is now available for Kubernetes and On-premises. Need faster analytics from Postgres? Want a native Postgres data lake experience? Learn more about how it works: www.crunchydata.com/blog/crunchy...
Reposted by Marco Slot


We weren't really thinking of log management as a target use case, but Iceberg is ideal as the final destination for logs, and having transactions & built-in job scheduling & a fast query engine (& laser focus on developer experience) makes things really simple and cost-effective.
I got a number of questions on how we saved $30k a month on cloudwatch by moving logs directly to S3/Iceberg with Postgres so I wrote up how in a bit more detail - www.crunchydata.com/blog/reducin...
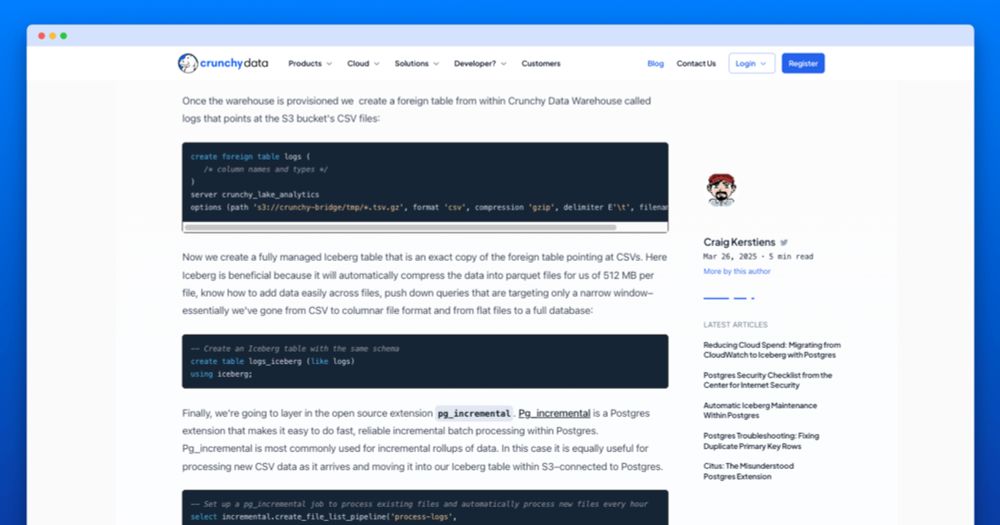
Reducing Cloud Spend: Migrating Logs from CloudWatch to Iceberg with Postgres | Crunchy Data Blog
How we migrated our internal logging for our database as a service, Crunchy Bridge, from CloudWatch to S3 with Iceberg and Postgres. The result was simplified logging management, better access with SQ...
www.crunchydata.com
March 26, 2025 at 7:39 PM
We weren't really thinking of log management as a target use case, but Iceberg is ideal as the final destination for logs, and having transactions & built-in job scheduling & a fast query engine (& laser focus on developer experience) makes things really simple and cost-effective.
Reposted by Marco Slot
I got a number of questions on how we saved $30k a month on cloudwatch by moving logs directly to S3/Iceberg with Postgres so I wrote up how in a bit more detail - www.crunchydata.com/blog/reducin...
Reducing Cloud Spend: Migrating Logs from CloudWatch to Iceberg with Postgres | Crunchy Data Blog
How we migrated our internal logging for our database as a service, Crunchy Bridge, from CloudWatch to S3 with Iceberg and Postgres. The result was simplified logging management, better access with SQ...
www.crunchydata.com
March 26, 2025 at 5:59 PM
I got a number of questions on how we saved $30k a month on cloudwatch by moving logs directly to S3/Iceberg with Postgres so I wrote up how in a bit more detail - www.crunchydata.com/blog/reducin...
Reposted by Marco Slot
Excited to announce built-in maintenance for Iceberg via Postgres.
Now within Crunchy Data Warehouse we will automatically vacuum and continuously optimize your Iceberg data by compacting and cleaning up files.
Dig into the details of how this works www.crunchydata.com/blog/automat...
Now within Crunchy Data Warehouse we will automatically vacuum and continuously optimize your Iceberg data by compacting and cleaning up files.
Dig into the details of how this works www.crunchydata.com/blog/automat...

Automatic Iceberg Maintenance Within Postgres | Crunchy Data Blog
Iceberg can create orphan files during snapshot changes or transaction rollbacks. Crunchy Data Warehouse automatically cleans up the orphan files using a new autovacuum feature.
www.crunchydata.com
March 20, 2025 at 3:46 PM
Excited to announce built-in maintenance for Iceberg via Postgres.
Now within Crunchy Data Warehouse we will automatically vacuum and continuously optimize your Iceberg data by compacting and cleaning up files.
Dig into the details of how this works www.crunchydata.com/blog/automat...
Now within Crunchy Data Warehouse we will automatically vacuum and continuously optimize your Iceberg data by compacting and cleaning up files.
Dig into the details of how this works www.crunchydata.com/blog/automat...
Imagine your potential customer as a serious company doing serious things, and willing to pay serious money if you can genuinely help them run their business without causing lot of new problems.
Then go build products for that customer.
This works.
Then go build products for that customer.
This works.
March 14, 2025 at 8:04 PM
Imagine your potential customer as a serious company doing serious things, and willing to pay serious money if you can genuinely help them run their business without causing lot of new problems.
Then go build products for that customer.
This works.
Then go build products for that customer.
This works.
Auto-vacuum for #Iceberg tables is now available in Crunchy Data Warehouse!
We're always aiming for a 0-touch experience where possible, so we went out of our way to make Iceberg compaction & cleanup fully automatic without any configuration.
Still pretty interesting to see a manual vacuum:
We're always aiming for a 0-touch experience where possible, so we went out of our way to make Iceberg compaction & cleanup fully automatic without any configuration.
Still pretty interesting to see a manual vacuum:

March 11, 2025 at 2:56 PM
Auto-vacuum for #Iceberg tables is now available in Crunchy Data Warehouse!
We're always aiming for a 0-touch experience where possible, so we went out of our way to make Iceberg compaction & cleanup fully automatic without any configuration.
Still pretty interesting to see a manual vacuum:
We're always aiming for a 0-touch experience where possible, so we went out of our way to make Iceberg compaction & cleanup fully automatic without any configuration.
Still pretty interesting to see a manual vacuum:
Reposted by Marco Slot
A big part of building Crunchy Data Warehouse was ease of use. How easy is it to load data from existing public datasets?
Step 1: Point at your dataset and we'll load it for you
Step 2: Query it
Step 3: Profit
Step 1: Point at your dataset and we'll load it for you
Step 2: Query it
Step 3: Profit
February 27, 2025 at 6:39 PM
A big part of building Crunchy Data Warehouse was ease of use. How easy is it to load data from existing public datasets?
Step 1: Point at your dataset and we'll load it for you
Step 2: Query it
Step 3: Profit
Step 1: Point at your dataset and we'll load it for you
Step 2: Query it
Step 3: Profit
ChatGPT Plus had a good run, but looks like Le Chat is going to be my main assistant now.
I like that it's fast, to the point, and quite clever.
I was impressed with a SQL query it came up with today for finding contiguous ranges of integers. ChatGPT's version was 3x slower.
I like that it's fast, to the point, and quite clever.
I was impressed with a SQL query it came up with today for finding contiguous ranges of integers. ChatGPT's version was 3x slower.
February 14, 2025 at 12:26 PM
ChatGPT Plus had a good run, but looks like Le Chat is going to be my main assistant now.
I like that it's fast, to the point, and quite clever.
I was impressed with a SQL query it came up with today for finding contiguous ranges of integers. ChatGPT's version was 3x slower.
I like that it's fast, to the point, and quite clever.
I was impressed with a SQL query it came up with today for finding contiguous ranges of integers. ChatGPT's version was 3x slower.
Postgres is increasingly becoming a versatile data platform, instead of just an operational database.
Using pg_parquet you can trivially export data to S3, and using Crunchy Data Warehouse you can just as easily query or import Parquet files from PostgreSQL.
Using pg_parquet you can trivially export data to S3, and using Crunchy Data Warehouse you can just as easily query or import Parquet files from PostgreSQL.
February 7, 2025 at 11:11 AM
Postgres is increasingly becoming a versatile data platform, instead of just an operational database.
Using pg_parquet you can trivially export data to S3, and using Crunchy Data Warehouse you can just as easily query or import Parquet files from PostgreSQL.
Using pg_parquet you can trivially export data to S3, and using Crunchy Data Warehouse you can just as easily query or import Parquet files from PostgreSQL.
Deepseek R1 in an ollama "container app" on a managed Postgres server, because... why not?

January 28, 2025 at 3:50 PM
Deepseek R1 in an ollama "container app" on a managed Postgres server, because... why not?
5 years from now, no one's going to want slower, less reliable, or harder to use databases.
January 27, 2025 at 11:24 PM
5 years from now, no one's going to want slower, less reliable, or harder to use databases.
🎉 pg_documentdb is open source
I created the initial version with Vinod Sridharan (an absolutely brilliant engineer) at Microsoft a few years ago and it's come a long way since.
It reimplements Mongo API with exact semantics in PostgreSQL. Already used by FerretDB!
github.com/microsoft/do...
I created the initial version with Vinod Sridharan (an absolutely brilliant engineer) at Microsoft a few years ago and it's come a long way since.
It reimplements Mongo API with exact semantics in PostgreSQL. Already used by FerretDB!
github.com/microsoft/do...

GitHub - microsoft/documentdb: DocumentDB offers a native implementation of document-oriented NoSQL database, enabling seamless CRUD operations on BSON data types within a PostgreSQL framework.
DocumentDB offers a native implementation of document-oriented NoSQL database, enabling seamless CRUD operations on BSON data types within a PostgreSQL framework. - microsoft/documentdb
github.com
January 23, 2025 at 7:58 PM
🎉 pg_documentdb is open source
I created the initial version with Vinod Sridharan (an absolutely brilliant engineer) at Microsoft a few years ago and it's come a long way since.
It reimplements Mongo API with exact semantics in PostgreSQL. Already used by FerretDB!
github.com/microsoft/do...
I created the initial version with Vinod Sridharan (an absolutely brilliant engineer) at Microsoft a few years ago and it's come a long way since.
It reimplements Mongo API with exact semantics in PostgreSQL. Already used by FerretDB!
github.com/microsoft/do...
Impressed by the latest ParadeDB release.
Solving the right problems in the right way is really hard.
Solving the right problems in the right way is really hard.

ParadeDB is now integrated with Postgres block storage.
Today, we are releasing Part 1 of our 3-part blog series on how we designed a new storage mechanism for search and analytics in Postgres.
www.paradedb.com/blog/block_s...
Today, we are releasing Part 1 of our 3-part blog series on how we designed a new storage mechanism for search and analytics in Postgres.
www.paradedb.com/blog/block_s...

ParadeDB
Zero-ETL search and analytics for Postgres
www.paradedb.com
January 17, 2025 at 9:26 PM
Impressed by the latest ParadeDB release.
Solving the right problems in the right way is really hard.
Solving the right problems in the right way is really hard.
Reposted by Marco Slot

1/11. ParadeDB is now integrated with Postgres block storage. As far as we know, no one has integrated a search and analytics engine with Postgres storage before. This is a big deal.
Here's why we did it, how we did it, and why you should care. 🧵
Here's why we did it, how we did it, and why you should care. 🧵
ParadeDB is now integrated with Postgres block storage.
Today, we are releasing Part 1 of our 3-part blog series on how we designed a new storage mechanism for search and analytics in Postgres.
www.paradedb.com/blog/block_s...
Today, we are releasing Part 1 of our 3-part blog series on how we designed a new storage mechanism for search and analytics in Postgres.
www.paradedb.com/blog/block_s...
ParadeDB
Zero-ETL search and analytics for Postgres
www.paradedb.com
January 17, 2025 at 7:11 PM
1/11. ParadeDB is now integrated with Postgres block storage. As far as we know, no one has integrated a search and analytics engine with Postgres storage before. This is a big deal.
Here's why we did it, how we did it, and why you should care. 🧵
Here's why we did it, how we did it, and why you should care. 🧵