




Marvin Lavechin
@marvinlavechin.bsky.social
Machine learning, speech processing, language acquisition and cognition.
Soon @cnrs.fr @univ-amu.fr; currently postdoc at MIT, Cambridge, US.
Soon @cnrs.fr @univ-amu.fr; currently postdoc at MIT, Cambridge, US.
Pinned
OSF
osf.io
Glad to share this new study comparing the performance and biases of the LENA and ACLEW algorithms in analyzing language environments in Down, Fragile X, Angelman syndromes, and populations at elevated likelihood for autism 👶📄
osf.io/preprints/ps...
🧵1/12
osf.io/preprints/ps...
🧵1/12
Reposted by Marvin Lavechin

🚀 I’m excited to announce the launch of our new research chair DevAI&Speech (2025–2029), funded by the Grenoble AI Institute MIAI Cluster IA!
The project explores how human developmental processes can inspire more grounded and socially aware conversational AI (1/6).
The project explores how human developmental processes can inspire more grounded and socially aware conversational AI (1/6).
July 2, 2025 at 11:39 AM
🚀 I’m excited to announce the launch of our new research chair DevAI&Speech (2025–2029), funded by the Grenoble AI Institute MIAI Cluster IA!
The project explores how human developmental processes can inspire more grounded and socially aware conversational AI (1/6).
The project explores how human developmental processes can inspire more grounded and socially aware conversational AI (1/6).
Reposted by Marvin Lavechin

Children are incredible language learning machines. But how do they do it? Our latest paper, just published in TICS, synthesizes decades of evidence to propose four components that must be built into any theory of how children learn language. 1/
www.cell.com/trends/cogni... @mpi-nl.bsky.social
www.cell.com/trends/cogni... @mpi-nl.bsky.social
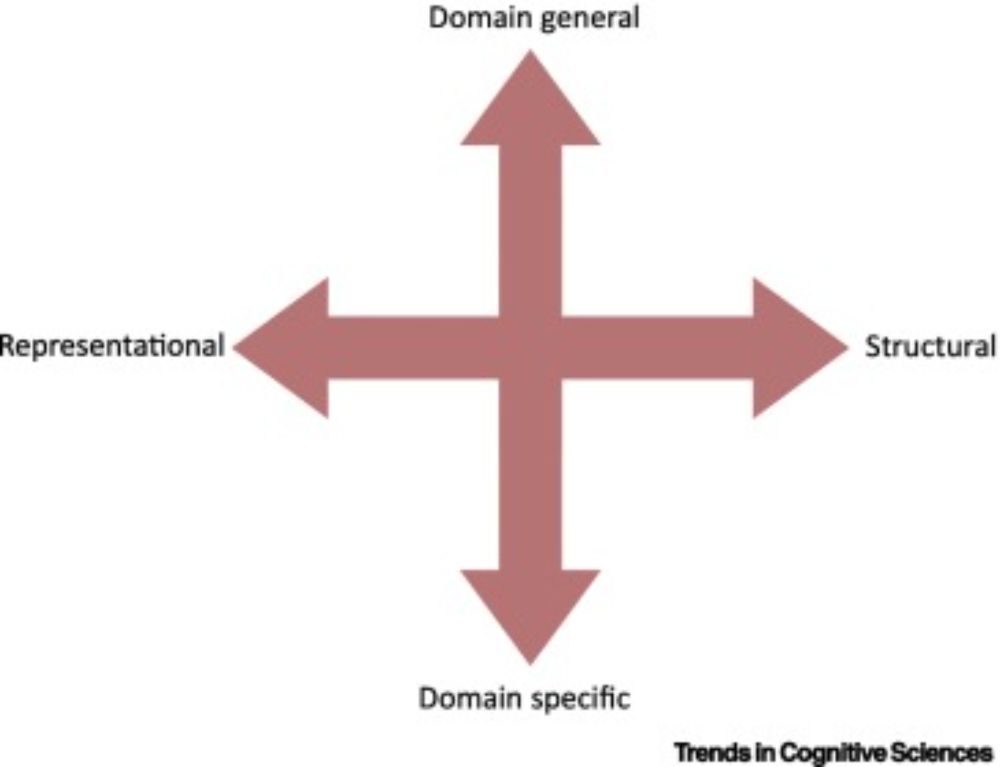
Constructing language: a framework for explaining acquisition
Explaining how children build a language system is a central goal of research in language
acquisition, with broad implications for language evolution, adult language processing,
and artificial intelli...
www.cell.com
June 27, 2025 at 5:17 AM
Children are incredible language learning machines. But how do they do it? Our latest paper, just published in TICS, synthesizes decades of evidence to propose four components that must be built into any theory of how children learn language. 1/
www.cell.com/trends/cogni... @mpi-nl.bsky.social
www.cell.com/trends/cogni... @mpi-nl.bsky.social
Reposted by Marvin Lavechin

Next we jump from analyzing text models to predictive speech models! Phoneticists have claimed for decades that humans rely more on contextual cues when processing vowels compared to consonants. Turns out so do speech models!

June 12, 2025 at 6:56 PM
Next we jump from analyzing text models to predictive speech models! Phoneticists have claimed for decades that humans rely more on contextual cues when processing vowels compared to consonants. Turns out so do speech models!
Reposted by Marvin Lavechin

Don't miss our next ICIS webinar! June 19 2025.
Join leading researchers for a deep dive into cutting-edge work in infancy research.
infantstudies.org/icis-online-...
#InfantResearch #InfantStudies
Join leading researchers for a deep dive into cutting-edge work in infancy research.
infantstudies.org/icis-online-...
#InfantResearch #InfantStudies

June 3, 2025 at 3:41 PM
Don't miss our next ICIS webinar! June 19 2025.
Join leading researchers for a deep dive into cutting-edge work in infancy research.
infantstudies.org/icis-online-...
#InfantResearch #InfantStudies
Join leading researchers for a deep dive into cutting-edge work in infancy research.
infantstudies.org/icis-online-...
#InfantResearch #InfantStudies
A great opportunity to learn how speech technology can advance research on how children learn language (and vice versa)
You know, beyond surveillance and chatbots 🙊
You know, beyond surveillance and chatbots 🙊

Now that @interspeech.bsky.social registration is open, time for some shameless promo!
Sign-up and join our Interspeech tutorial: Speech Technology Meets Early Language Acquisition: How Interdisciplinary Efforts Benefit Both Fields. 🗣️👶
www.interspeech2025.org/tutorials
⬇️ (1/2)
Sign-up and join our Interspeech tutorial: Speech Technology Meets Early Language Acquisition: How Interdisciplinary Efforts Benefit Both Fields. 🗣️👶
www.interspeech2025.org/tutorials
⬇️ (1/2)
https://www.interspeech2025.org/tutorials
Your cookies are disabled, please enable them.
www.interspeech2025.org
May 27, 2025 at 4:27 PM
A great opportunity to learn how speech technology can advance research on how children learn language (and vice versa)
You know, beyond surveillance and chatbots 🙊
You know, beyond surveillance and chatbots 🙊
👀
New preprint out! 👇
We adapt the ABX task, commonly used in speech models, to investigate how multilingual text models represent form (language) vs content (meaning).
📄 arxiv.org/pdf/2505.17747
🙌 With Jie Chi, Skyler Seto, @maartjeterhoeve.bsky.social, Masha Fedzechkina & Natalie Schluter
We adapt the ABX task, commonly used in speech models, to investigate how multilingual text models represent form (language) vs content (meaning).
📄 arxiv.org/pdf/2505.17747
🙌 With Jie Chi, Skyler Seto, @maartjeterhoeve.bsky.social, Masha Fedzechkina & Natalie Schluter
arxiv.org
May 26, 2025 at 2:42 PM
👀
Reposted by Marvin Lavechin

Interested in collecting and processing naturalistic audio data using new AI tools?
If so, join us for our free, two-day workshop; 'Long Form Audio Recordings: A to Z', generously supported by Cardiff University Doctoral Academy.
If so, join us for our free, two-day workshop; 'Long Form Audio Recordings: A to Z', generously supported by Cardiff University Doctoral Academy.


May 23, 2025 at 8:34 AM
Interested in collecting and processing naturalistic audio data using new AI tools?
If so, join us for our free, two-day workshop; 'Long Form Audio Recordings: A to Z', generously supported by Cardiff University Doctoral Academy.
If so, join us for our free, two-day workshop; 'Long Form Audio Recordings: A to Z', generously supported by Cardiff University Doctoral Academy.
Reposted by Marvin Lavechin

🤖🧠 Paper out in Nature Communications! 🧠🤖
Bayesian models can learn rapidly. Neural networks can handle messy, naturalistic data. How can we combine these strengths?
Our answer: Use meta-learning to distill Bayesian priors into a neural network!
www.nature.com/articles/s41...
1/n
Bayesian models can learn rapidly. Neural networks can handle messy, naturalistic data. How can we combine these strengths?
Our answer: Use meta-learning to distill Bayesian priors into a neural network!
www.nature.com/articles/s41...
1/n

May 20, 2025 at 7:04 PM
🤖🧠 Paper out in Nature Communications! 🧠🤖
Bayesian models can learn rapidly. Neural networks can handle messy, naturalistic data. How can we combine these strengths?
Our answer: Use meta-learning to distill Bayesian priors into a neural network!
www.nature.com/articles/s41...
1/n
Bayesian models can learn rapidly. Neural networks can handle messy, naturalistic data. How can we combine these strengths?
Our answer: Use meta-learning to distill Bayesian priors into a neural network!
www.nature.com/articles/s41...
1/n
Reposted by Marvin Lavechin

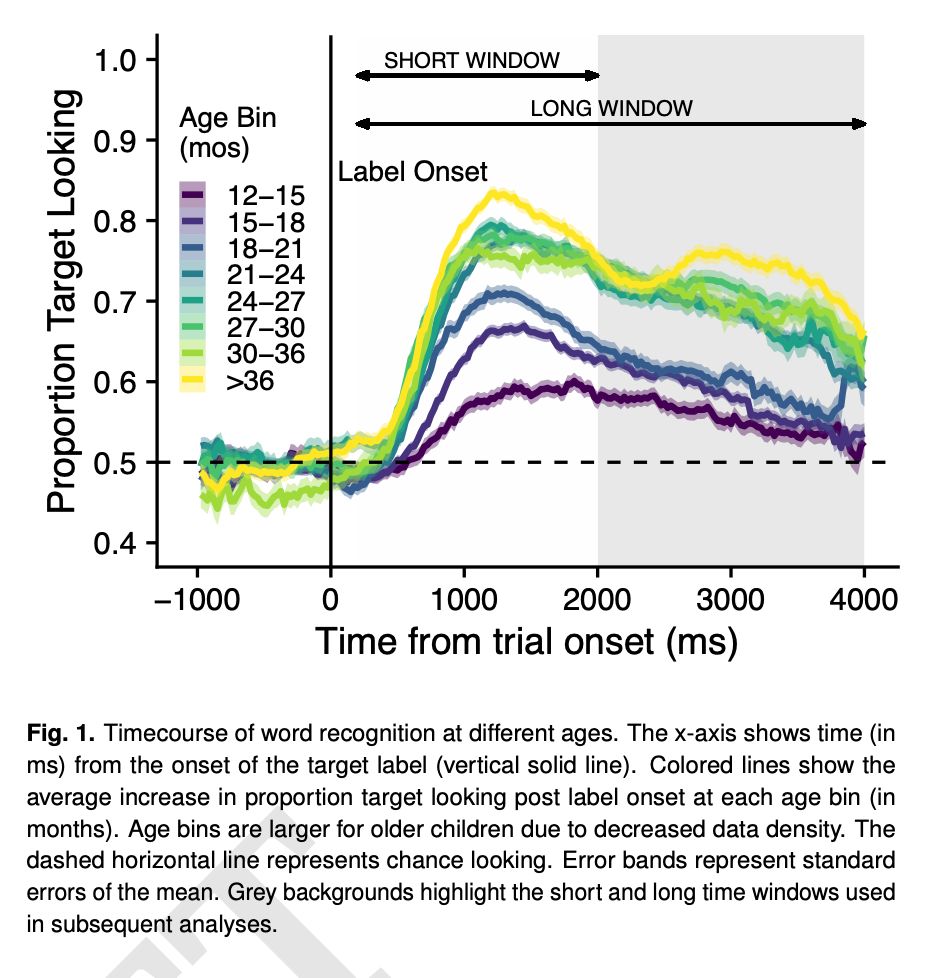
Super excited to submit a big sabbatical project this year: "Continuous developmental changes in word
recognition support language learning across early
childhood": osf.io/preprints/ps...
recognition support language learning across early
childhood": osf.io/preprints/ps...

April 14, 2025 at 9:58 PM
Super excited to submit a big sabbatical project this year: "Continuous developmental changes in word
recognition support language learning across early
childhood": osf.io/preprints/ps...
recognition support language learning across early
childhood": osf.io/preprints/ps...
Reposted by Marvin Lavechin
My 2025 resolution is to write threads for papers authored by the Language Development Dept here at MPI for Psycholinguistics. The 3rd in the series: Gesture screening in young infants: Highly sensitive to risk factors for communication delay, Alcock et al 1/
onlinelibrary.wiley.com/doi/10.1111/...
onlinelibrary.wiley.com/doi/10.1111/...

Gesture screening in young infants: Highly sensitive to risk factors for communication delay
Introduction Children's early language and communication skills are efficiently measured using parent report, for example, communicative development inventories (CDIs). These have scalable potential...
onlinelibrary.wiley.com
April 8, 2025 at 1:34 PM
My 2025 resolution is to write threads for papers authored by the Language Development Dept here at MPI for Psycholinguistics. The 3rd in the series: Gesture screening in young infants: Highly sensitive to risk factors for communication delay, Alcock et al 1/
onlinelibrary.wiley.com/doi/10.1111/...
onlinelibrary.wiley.com/doi/10.1111/...
Glad to share this new study comparing the performance and biases of the LENA and ACLEW algorithms in analyzing language environments in Down, Fragile X, Angelman syndromes, and populations at elevated likelihood for autism 👶📄
osf.io/preprints/ps...
🧵1/12
osf.io/preprints/ps...
🧵1/12
OSF
osf.io
April 7, 2025 at 8:56 PM
Glad to share this new study comparing the performance and biases of the LENA and ACLEW algorithms in analyzing language environments in Down, Fragile X, Angelman syndromes, and populations at elevated likelihood for autism 👶📄
osf.io/preprints/ps...
🧵1/12
osf.io/preprints/ps...
🧵1/12