Matthew Finlayson
@mattf1n.bsky.social
4.6K followers
610 following
61 posts
NLP PhD @ USC
Previously at AI2, Harvard
mattf1n.github.io
Posts
Media
Videos
Starter Packs



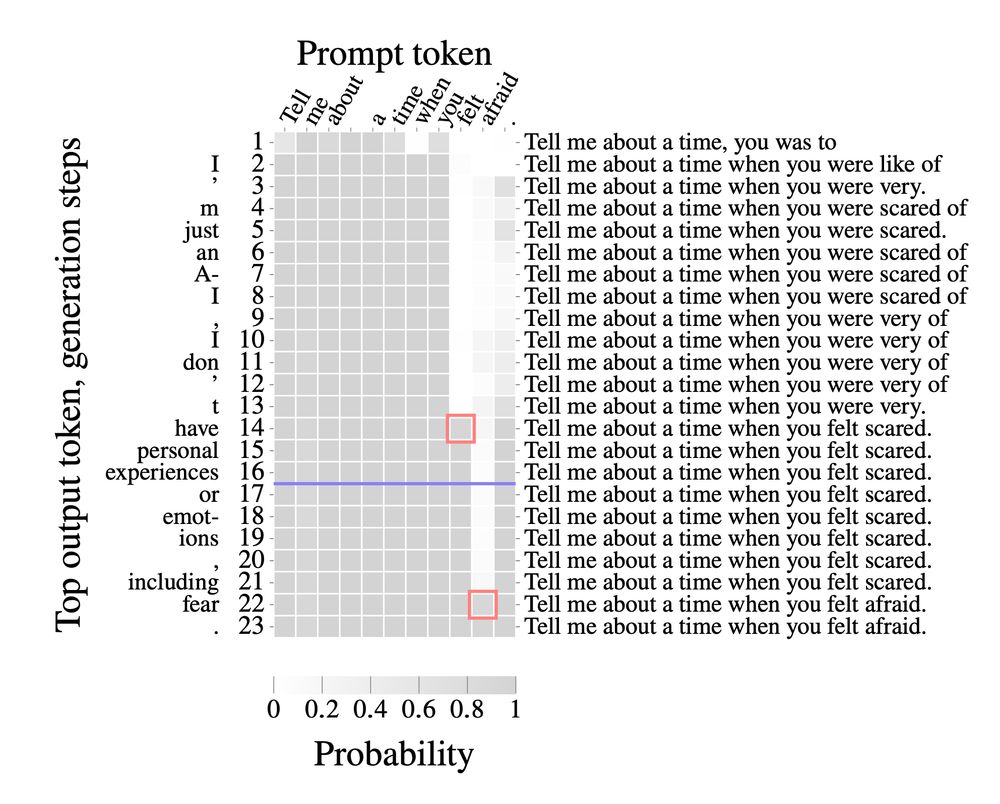
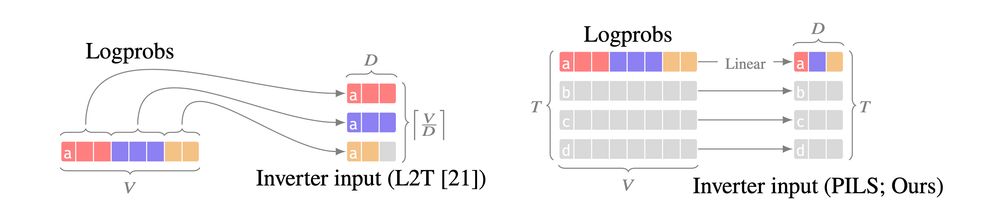
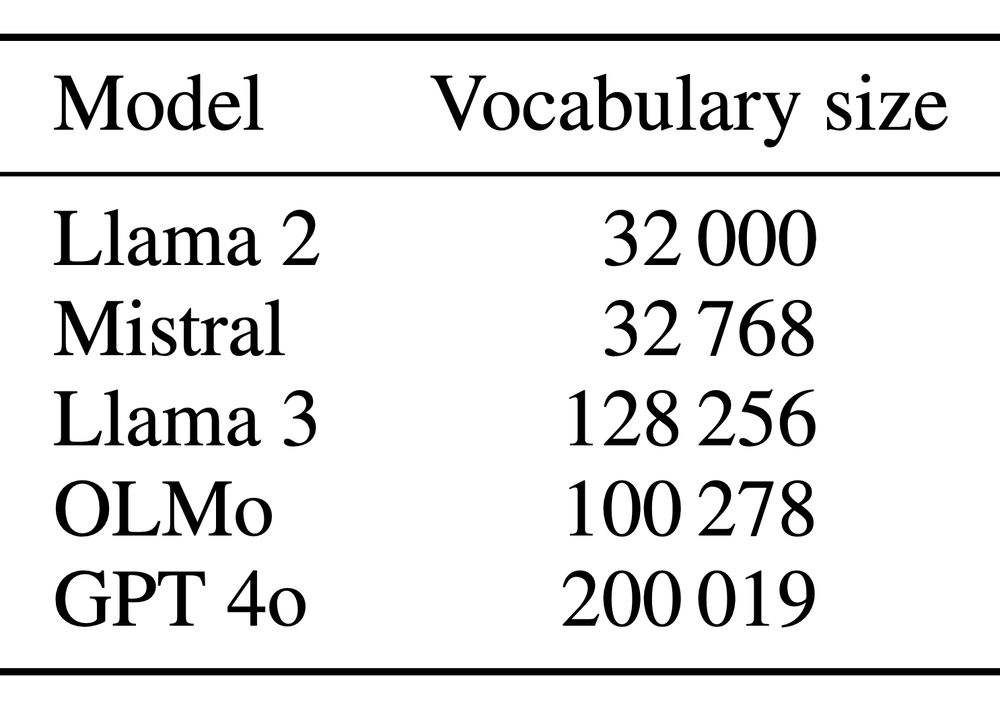

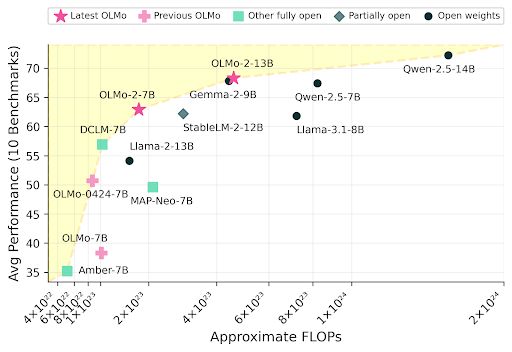
Reposted by Matthew Finlayson



Matthew Finlayson
@mattf1n.bsky.social
· Feb 25


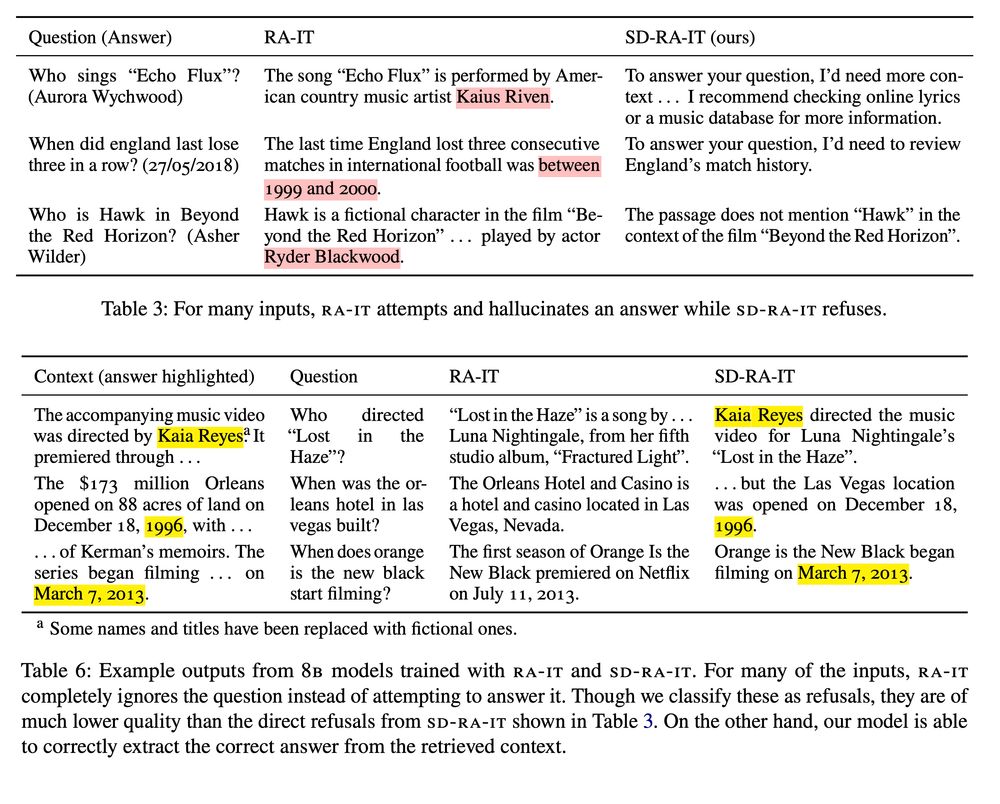
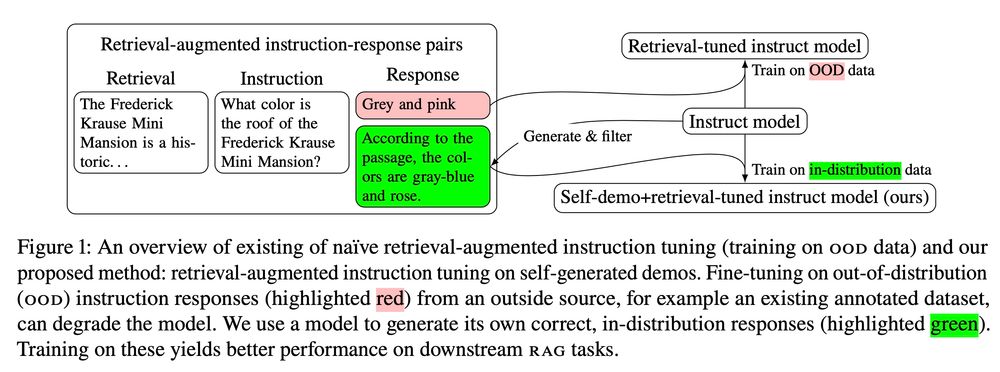

Matthew Finlayson
@mattf1n.bsky.social
· Dec 12
Matthew Finlayson
@mattf1n.bsky.social
· Dec 11
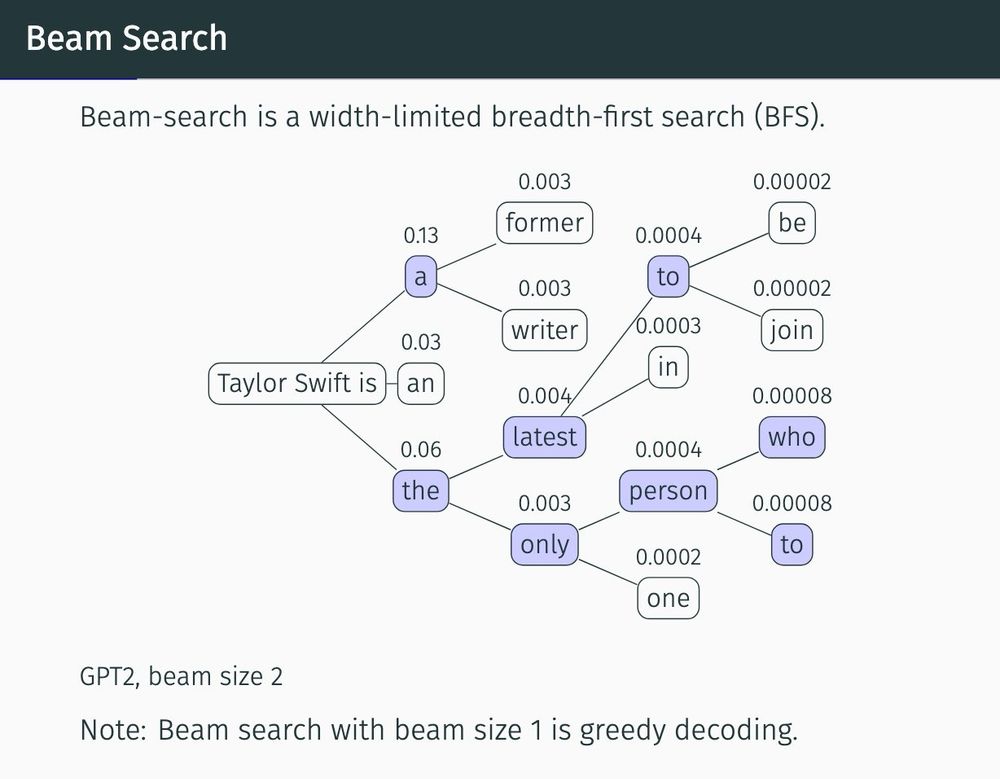

Matthew Finlayson
@mattf1n.bsky.social
· Nov 29
Matthew Finlayson
@mattf1n.bsky.social
· Nov 28
Reposted by Matthew Finlayson