



Moritz Haas
@mohaas.bsky.social
IMPRS-IS PhD student @ University of Tübingen with Ulrike von Luxburg and Bedartha Goswami. Mostly thinking about deep learning theory. Also interested in ML for climate science.
mohawastaken.github.io
mohawastaken.github.io
Stable model scaling with width-independent dynamics?
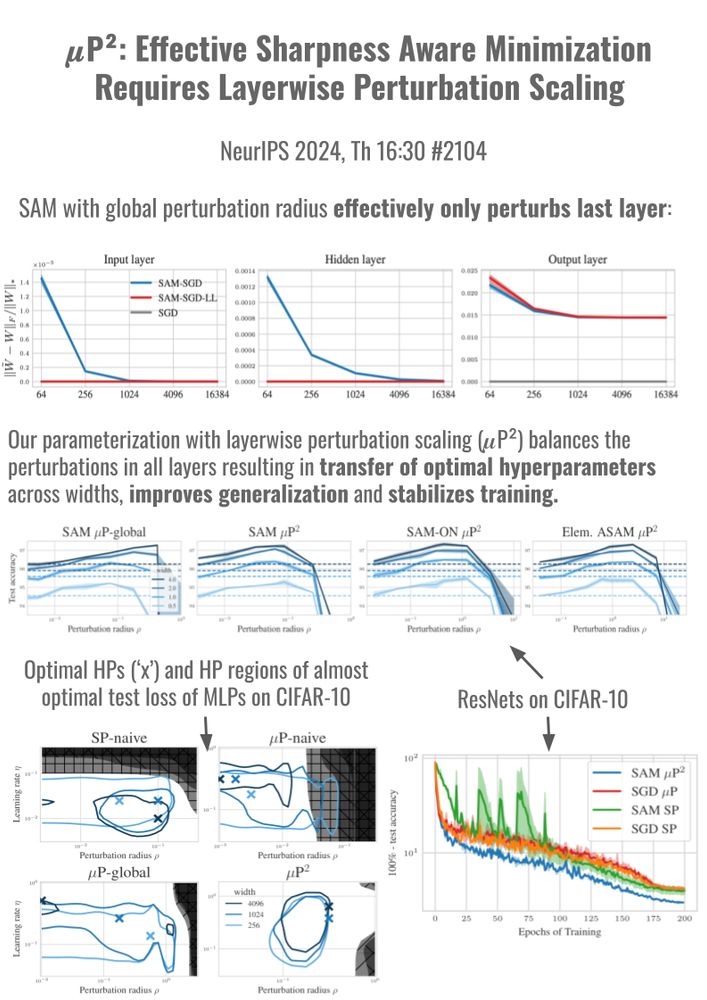
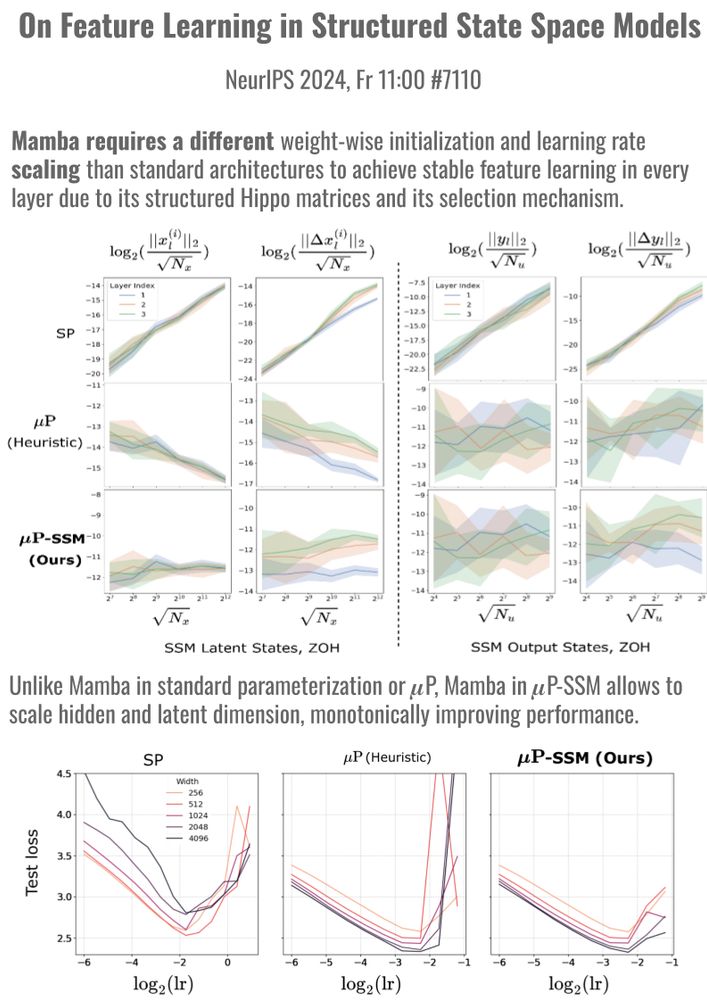
Thrilled to present 2 papers at #NeurIPS 🎉 that study width-scaling in Sharpness Aware Minimization (SAM) (Th 16:30, #2104) and in Mamba (Fr 11, #7110). Our scaling rules stabilize training and transfer optimal hyperparams across scales.
🧵 1/10
Thrilled to present 2 papers at #NeurIPS 🎉 that study width-scaling in Sharpness Aware Minimization (SAM) (Th 16:30, #2104) and in Mamba (Fr 11, #7110). Our scaling rules stabilize training and transfer optimal hyperparams across scales.
🧵 1/10
December 10, 2024 at 7:08 AM
Stable model scaling with width-independent dynamics?
Thrilled to present 2 papers at #NeurIPS 🎉 that study width-scaling in Sharpness Aware Minimization (SAM) (Th 16:30, #2104) and in Mamba (Fr 11, #7110). Our scaling rules stabilize training and transfer optimal hyperparams across scales.
🧵 1/10
Thrilled to present 2 papers at #NeurIPS 🎉 that study width-scaling in Sharpness Aware Minimization (SAM) (Th 16:30, #2104) and in Mamba (Fr 11, #7110). Our scaling rules stabilize training and transfer optimal hyperparams across scales.
🧵 1/10