




Andrew Drozdov
@mrdrozdov.com
Research Scientist @ Mosaic x Databricks. Adaptive Methods for Retrieval, Generation, NLP, AI, LLMs https://mrdrozdov.github.io/
Pinned
We built a thing! The Databricks Reranker is now in Public Preview. It's as easy as changing the arguments to your vector search call, and doesn't require any additional setup.
Read more: www.databricks.com/blog/reranki...
Read more: www.databricks.com/blog/reranki...

Reranking in Mosaic AI Vector Search for Faster, Smarter Retrieval in RAG Agents
Boost RAG agent quality with reranking—deliver more relevant answers in less time with a single parameter in Mosaic AI Vector Search.
www.databricks.com
August 19, 2025 at 12:03 AM
We built a thing! The Databricks Reranker is now in Public Preview. It's as easy as changing the arguments to your vector search call, and doesn't require any additional setup.
Read more: www.databricks.com/blog/reranki...
Read more: www.databricks.com/blog/reranki...
Reposted by Andrew Drozdov

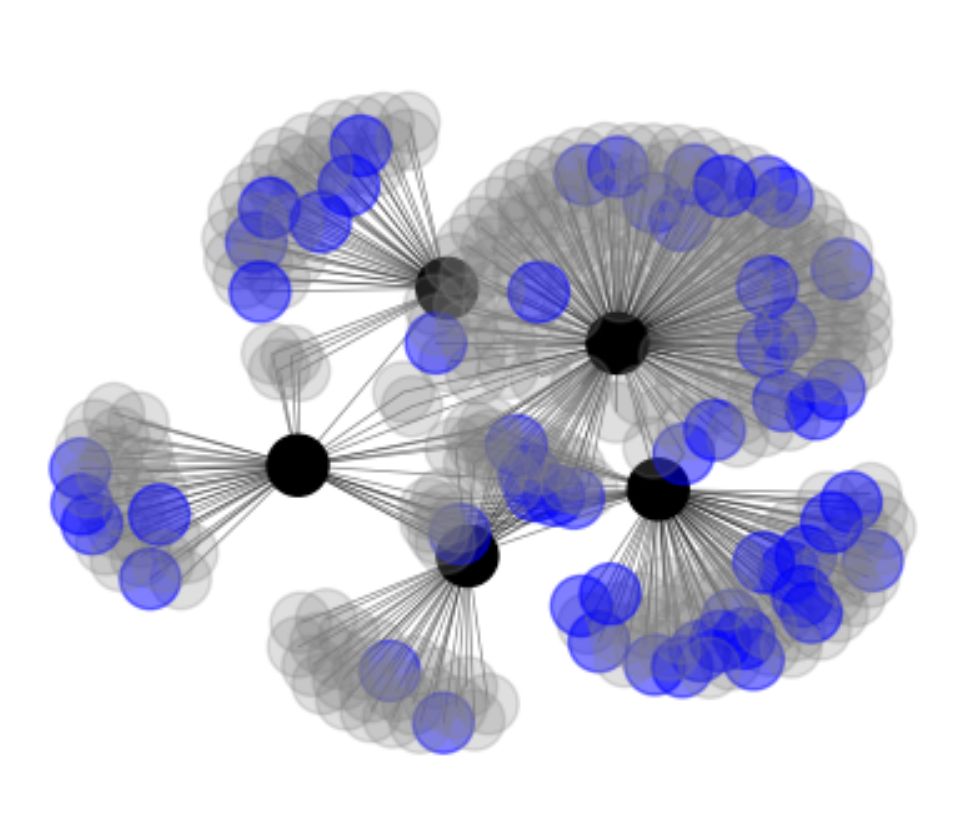
The transformer was invented in Google. RLHF was not invented in industry labs, but came to prominence in OpenAI and DeepMind. I took 5 of the most influential papers (black dots) and visualized their references. Blue dots are papers that acknowledge federal funding (DARPA, NSF).
April 12, 2025 at 2:35 AM
The transformer was invented in Google. RLHF was not invented in industry labs, but came to prominence in OpenAI and DeepMind. I took 5 of the most influential papers (black dots) and visualized their references. Blue dots are papers that acknowledge federal funding (DARPA, NSF).
Reposted by Andrew Drozdov

LongEval is turning three this year!
This is a Call for Participation to our CLEF 2025 Lab - try out how your IR system does in the long term.
Check the details on our page:
clef-longeval.github.io
This is a Call for Participation to our CLEF 2025 Lab - try out how your IR system does in the long term.
Check the details on our page:
clef-longeval.github.io
LongEval 2025
Conference Template
clef-longeval.github.io
April 11, 2025 at 11:24 AM
LongEval is turning three this year!
This is a Call for Participation to our CLEF 2025 Lab - try out how your IR system does in the long term.
Check the details on our page:
clef-longeval.github.io
This is a Call for Participation to our CLEF 2025 Lab - try out how your IR system does in the long term.
Check the details on our page:
clef-longeval.github.io
The PhD is pretraining. Interview prep is alignment. Take this to heart. :)
April 13, 2025 at 8:16 AM
The PhD is pretraining. Interview prep is alignment. Take this to heart. :)
Reposted by Andrew Drozdov

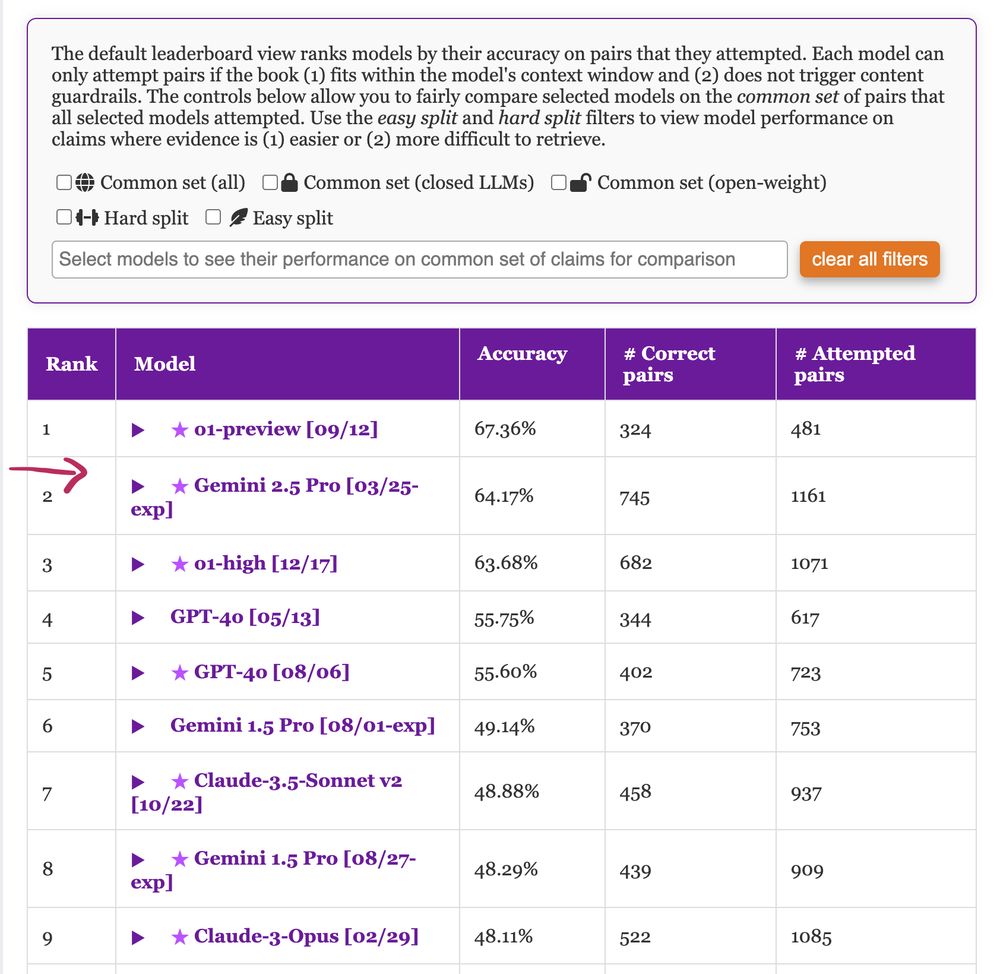
We have updated #nocha, a leaderboard for reasoning over long-context narratives 📖, with some new models including #Gemini 2.5 Pro which shows massive improvements over the previous version! Congrats to #Gemini team 🪄 🧙 Check 🔗 novelchallenge.github.io for details :)
April 2, 2025 at 4:30 AM
We have updated #nocha, a leaderboard for reasoning over long-context narratives 📖, with some new models including #Gemini 2.5 Pro which shows massive improvements over the previous version! Congrats to #Gemini team 🪄 🧙 Check 🔗 novelchallenge.github.io for details :)
Perhaps the most misunderstood aspect of retrieval: For a context to be relevant, it is not enough for it to improve the probability of the right answer.
March 22, 2025 at 11:51 AM
Perhaps the most misunderstood aspect of retrieval: For a context to be relevant, it is not enough for it to improve the probability of the right answer.
Reposted by Andrew Drozdov

MLflow is on BlueSky! Follow @mlflow.org to keep up to date on new releases, blogs and tutorials, events, and more.
bsky.app
March 14, 2025 at 11:02 PM
MLflow is on BlueSky! Follow @mlflow.org to keep up to date on new releases, blogs and tutorials, events, and more.
One, and two, and three police persons spring out of the shadows
Down the corner comes one more
And we scream into that city night: “three plus one makes four!”
Well, they seem to think we’re disturbing the peace
But we won’t let them make us sad
’Cause kids like you and me baby, we were born to add
Down the corner comes one more
And we scream into that city night: “three plus one makes four!”
Well, they seem to think we’re disturbing the peace
But we won’t let them make us sad
’Cause kids like you and me baby, we were born to add
March 12, 2025 at 3:19 AM
One, and two, and three police persons spring out of the shadows
Down the corner comes one more
And we scream into that city night: “three plus one makes four!”
Well, they seem to think we’re disturbing the peace
But we won’t let them make us sad
’Cause kids like you and me baby, we were born to add
Down the corner comes one more
And we scream into that city night: “three plus one makes four!”
Well, they seem to think we’re disturbing the peace
But we won’t let them make us sad
’Cause kids like you and me baby, we were born to add
"How Claude Code is using a 50-Year-Old trick to revolutionize programming"
Somehow my most controversial take of 2025 is that agents relying on grep are a form of RAG.
March 11, 2025 at 3:21 AM
"How Claude Code is using a 50-Year-Old trick to revolutionize programming"
Somehow my most controversial take of 2025 is that agents relying on grep are a form of RAG.
March 11, 2025 at 3:20 AM
Somehow my most controversial take of 2025 is that agents relying on grep are a form of RAG.
It was a real pleasure talking about effective IR approaches with Brooke and Denny on the Data Brew podcast.
Among other things, I'm excited about embedding finetuning and reranking as modular ways to improve RAG pipelines. Everyone should use these more!
Among other things, I'm excited about embedding finetuning and reranking as modular ways to improve RAG pipelines. Everyone should use these more!
February 26, 2025 at 12:53 AM
It was a real pleasure talking about effective IR approaches with Brooke and Denny on the Data Brew podcast.
Among other things, I'm excited about embedding finetuning and reranking as modular ways to improve RAG pipelines. Everyone should use these more!
Among other things, I'm excited about embedding finetuning and reranking as modular ways to improve RAG pipelines. Everyone should use these more!
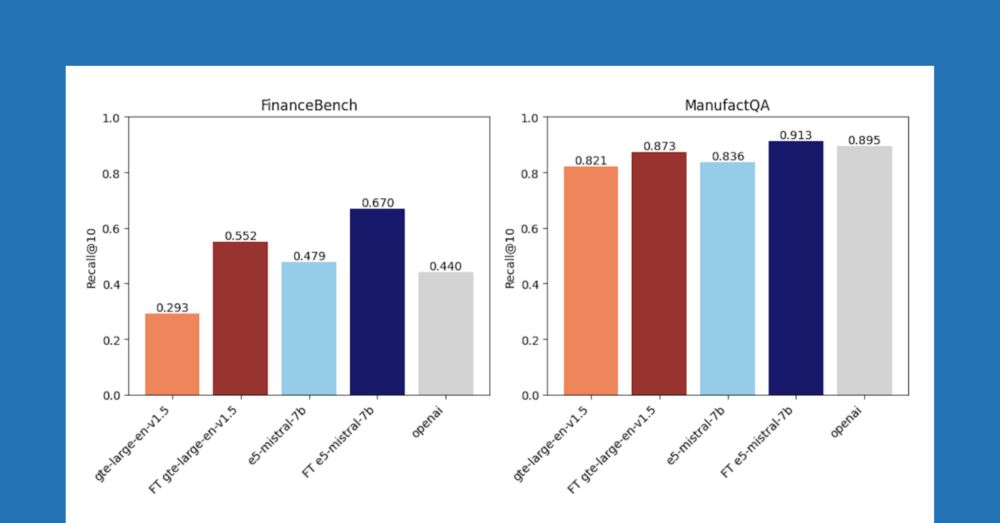
We're probably a little too obsessed with zero-shot retrieval. If you have documents (you do), then you can generate synthetic data, and finetune your embedding. Blog post lead by @jacobianneuro.bsky.social shows how well this works in practice.
www.databricks.com/blog/improvi...
www.databricks.com/blog/improvi...
Improving Retrieval and RAG with Embedding Model Finetuning
Fine-tune embedding models on Databricks to enhance retrieval and RAG accuracy with synthetic data—no manual labeling required.
www.databricks.com
February 26, 2025 at 12:48 AM
We're probably a little too obsessed with zero-shot retrieval. If you have documents (you do), then you can generate synthetic data, and finetune your embedding. Blog post lead by @jacobianneuro.bsky.social shows how well this works in practice.
www.databricks.com/blog/improvi...
www.databricks.com/blog/improvi...
I do want to see aggregate stats about the model’s generation and total reasoning tokens is perhaps the least informative one.
February 1, 2025 at 2:52 PM
I do want to see aggregate stats about the model’s generation and total reasoning tokens is perhaps the least informative one.
"All you need to build a strong reasoning model is the right data mix."
The pipeline that creates the data mix:
The pipeline that creates the data mix:
January 26, 2025 at 11:30 PM
"All you need to build a strong reasoning model is the right data mix."
The pipeline that creates the data mix:
The pipeline that creates the data mix:
Using 100+ tokens to answer 2 + 3 =

January 22, 2025 at 5:42 PM
Using 100+ tokens to answer 2 + 3 =
It’s pretty obvious we’re in a local minima for pretraining. Would expect more breakthroughs in the 5-10 year range. Granted, it’s still incredibly hard and expensive to do good research in this space, despite the number of labs working on it.
"the gap between OAI/Anthropic/Meta/etc. and a large group of companies all over the world you've never cared to know of, in terms of LM pre-training? tiny" - 💡 me (Nov 2, 2024)

December 27, 2024 at 3:50 AM
It’s pretty obvious we’re in a local minima for pretraining. Would expect more breakthroughs in the 5-10 year range. Granted, it’s still incredibly hard and expensive to do good research in this space, despite the number of labs working on it.
Reposted by Andrew Drozdov

Word of the day (of course) is ‘scurryfunging’, from US dialect: the frantic attempt to tidy the house just before guests arrive.
December 23, 2024 at 12:54 PM
Word of the day (of course) is ‘scurryfunging’, from US dialect: the frantic attempt to tidy the house just before guests arrive.
Reposted by Andrew Drozdov

... didn't know this would be one of the hottest takes i've had ...
for more on my thoughts, see drive.google.com/file/d/1sk_t...
for more on my thoughts, see drive.google.com/file/d/1sk_t...




December 21, 2024 at 7:17 PM
... didn't know this would be one of the hottest takes i've had ...
for more on my thoughts, see drive.google.com/file/d/1sk_t...
for more on my thoughts, see drive.google.com/file/d/1sk_t...
Reposted by Andrew Drozdov
feeling a but under the weather this week … thus an increased level of activity on social media and blog: kyunghyuncho.me/i-sensed-anx...
i sensed anxiety and frustration at NeurIPS’24 – Kyunghyun Cho
kyunghyuncho.me
December 21, 2024 at 7:47 PM
feeling a but under the weather this week … thus an increased level of activity on social media and blog: kyunghyuncho.me/i-sensed-anx...
Reposted by Andrew Drozdov

Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference
Introduces ModernBERT, a bidirectional encoder advancing BERT-like models with 8K context length.
📝 arxiv.org/abs/2412.13663
👨🏽💻 github.com/AnswerDotAI/...
Introduces ModernBERT, a bidirectional encoder advancing BERT-like models with 8K context length.
📝 arxiv.org/abs/2412.13663
👨🏽💻 github.com/AnswerDotAI/...

Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference
Encoder-only transformer models such as BERT offer a great performance-size tradeoff for retrieval and classification tasks with respect to larger decoder-only models. Despite being the workhorse of n...
arxiv.org
December 20, 2024 at 5:04 AM
Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference
Introduces ModernBERT, a bidirectional encoder advancing BERT-like models with 8K context length.
📝 arxiv.org/abs/2412.13663
👨🏽💻 github.com/AnswerDotAI/...
Introduces ModernBERT, a bidirectional encoder advancing BERT-like models with 8K context length.
📝 arxiv.org/abs/2412.13663
👨🏽💻 github.com/AnswerDotAI/...
Reposted by Andrew Drozdov
State Space Models are Strong Text Rerankers
Shows Mamba-based models achieve comparable reranking performance to transformers while being more memory efficient, with Mamba-2 outperforming Mamba-1.
📝 arxiv.org/abs/2412.14354
Shows Mamba-based models achieve comparable reranking performance to transformers while being more memory efficient, with Mamba-2 outperforming Mamba-1.
📝 arxiv.org/abs/2412.14354
State Space Models are Strong Text Rerankers
Transformers dominate NLP and IR; but their inference inefficiencies and challenges in extrapolating to longer contexts have sparked interest in alternative model architectures. Among these, state spa...
arxiv.org
December 20, 2024 at 5:13 AM
State Space Models are Strong Text Rerankers
Shows Mamba-based models achieve comparable reranking performance to transformers while being more memory efficient, with Mamba-2 outperforming Mamba-1.
📝 arxiv.org/abs/2412.14354
Shows Mamba-based models achieve comparable reranking performance to transformers while being more memory efficient, with Mamba-2 outperforming Mamba-1.
📝 arxiv.org/abs/2412.14354
Reposted by Andrew Drozdov

I’m being facetious, but the truth behind the joke is that OCR correction opens up the possibility (and futility) of language much like drafting poetry. For every interpreted pattern for optimizing OCR correction, exceptions arise. So, too, with patterns in poetry.
December 19, 2024 at 2:24 AM
I’m being facetious, but the truth behind the joke is that OCR correction opens up the possibility (and futility) of language much like drafting poetry. For every interpreted pattern for optimizing OCR correction, exceptions arise. So, too, with patterns in poetry.
Reasoning is fascinating but confusing.
Is reasoning a task? Or is reasoning a method for generating answers, for any task?
Is reasoning a task? Or is reasoning a method for generating answers, for any task?
December 17, 2024 at 2:00 AM
Reasoning is fascinating but confusing.
Is reasoning a task? Or is reasoning a method for generating answers, for any task?
Is reasoning a task? Or is reasoning a method for generating answers, for any task?
Reposted by Andrew Drozdov

The future of AI is models that generate graphical interfaces. Instead of the linear, low-bandwidth metaphor of conversation, models will represent themselves to us as computers: rich visuals, direct manipulation, and instant feedback.
willwhitney.com/computing-in...
willwhitney.com/computing-in...
Computing inside an AI | Will Whitney
willwhitney.com
December 14, 2024 at 12:55 AM
The future of AI is models that generate graphical interfaces. Instead of the linear, low-bandwidth metaphor of conversation, models will represent themselves to us as computers: rich visuals, direct manipulation, and instant feedback.
willwhitney.com/computing-in...
willwhitney.com/computing-in...
Reposted by Andrew Drozdov

Three must read papers for PhD students. #scisky #PhD #science #research #academicsky
1. The importance of stupidity in scientific research
Open Access
journals.biologists.com/jcs/article/...
1. The importance of stupidity in scientific research
Open Access
journals.biologists.com/jcs/article/...

November 24, 2024 at 1:54 PM
Three must read papers for PhD students. #scisky #PhD #science #research #academicsky
1. The importance of stupidity in scientific research
Open Access
journals.biologists.com/jcs/article/...
1. The importance of stupidity in scientific research
Open Access
journals.biologists.com/jcs/article/...