


Nicolas Yax
@nicolasyax.bsky.social
PhD student working on the cognition of LLMs | HRL team - ENS Ulm | FLOWERS - Inria Bordeaux
Pinned
Nicolas Yax
@nicolasyax.bsky.social
· Apr 24

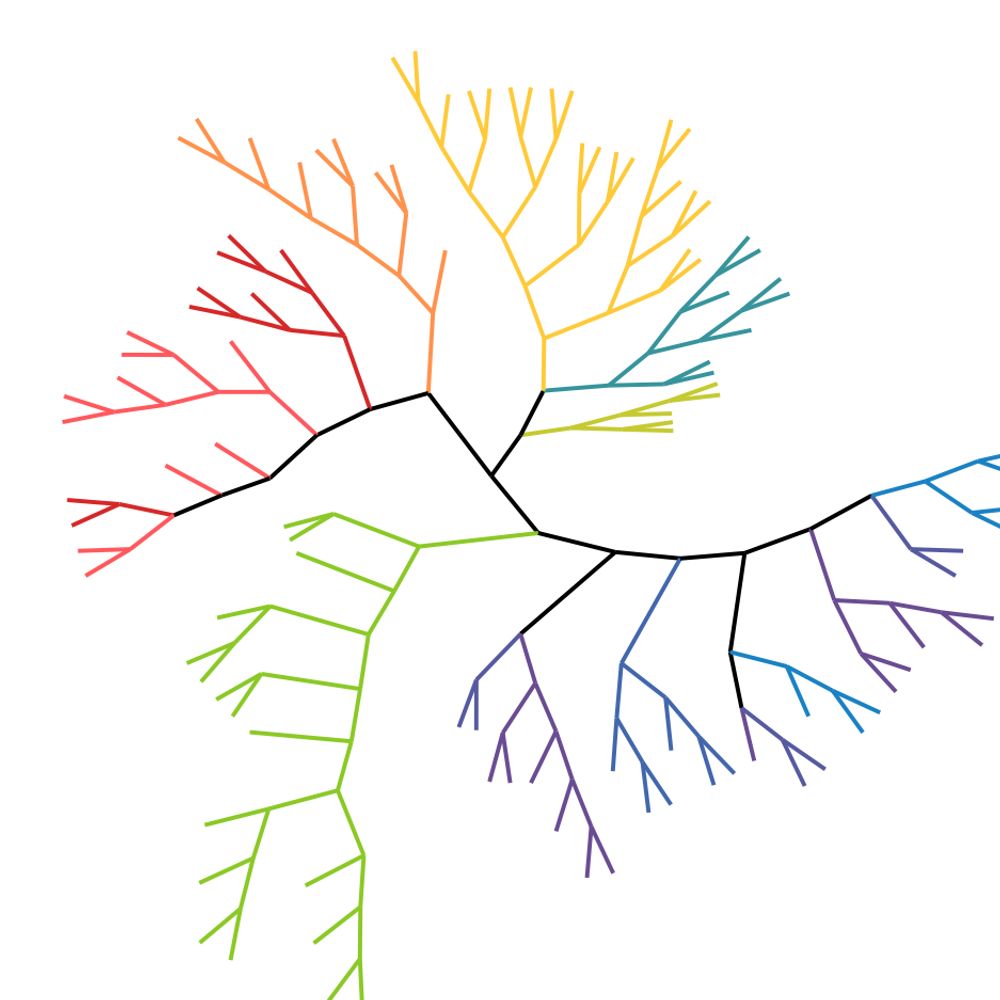
🔥Our paper PhyloLM got accepted at ICLR 2025 !🔥
In this work we show how easy it can be to infer relationship between LLMs by constructing trees and to predict their performances and behavior at a very low cost with @stepalminteri.bsky.social and @pyoudeyer.bsky.social ! Here is a brief recap ⬇️
In this work we show how easy it can be to infer relationship between LLMs by constructing trees and to predict their performances and behavior at a very low cost with @stepalminteri.bsky.social and @pyoudeyer.bsky.social ! Here is a brief recap ⬇️
Reposted by Nicolas Yax

New (revised) preprint with @thecharleywu.bsky.social
We rethink how to assess machine consciousness: not by code or circuitry, but by behavioral inference—as in cognitive science.
Extraordinary claims still need extraordinary evidence.
👉 osf.io/preprints/ps...
#AI #Consciousness #LLM
We rethink how to assess machine consciousness: not by code or circuitry, but by behavioral inference—as in cognitive science.
Extraordinary claims still need extraordinary evidence.
👉 osf.io/preprints/ps...
#AI #Consciousness #LLM

October 8, 2025 at 9:02 AM
New (revised) preprint with @thecharleywu.bsky.social
We rethink how to assess machine consciousness: not by code or circuitry, but by behavioral inference—as in cognitive science.
Extraordinary claims still need extraordinary evidence.
👉 osf.io/preprints/ps...
#AI #Consciousness #LLM
We rethink how to assess machine consciousness: not by code or circuitry, but by behavioral inference—as in cognitive science.
Extraordinary claims still need extraordinary evidence.
👉 osf.io/preprints/ps...
#AI #Consciousness #LLM
Reposted by Nicolas Yax
🧠 New paper in Open Mind!
We show that LLM-based reinforcement learning agents encode relative reward values like humans, even when suboptimal and display a positivity bias.
Work led by William Hayes w/ @nicolasyax.bsky.social
doi.org/10.1162/opmi...
#AI #LLM #RL
We show that LLM-based reinforcement learning agents encode relative reward values like humans, even when suboptimal and display a positivity bias.
Work led by William Hayes w/ @nicolasyax.bsky.social
doi.org/10.1162/opmi...
#AI #LLM #RL

Relative Value Encoding in Large Language Models: A Multi-Task, Multi-Model Investigation
Abtract. In-context learning enables large language models (LLMs) to perform a variety of tasks, including solving reinforcement learning (RL) problems. Given their potential use as (autonomous) decis...
doi.org
May 26, 2025 at 6:15 PM
🧠 New paper in Open Mind!
We show that LLM-based reinforcement learning agents encode relative reward values like humans, even when suboptimal and display a positivity bias.
Work led by William Hayes w/ @nicolasyax.bsky.social
doi.org/10.1162/opmi...
#AI #LLM #RL
We show that LLM-based reinforcement learning agents encode relative reward values like humans, even when suboptimal and display a positivity bias.
Work led by William Hayes w/ @nicolasyax.bsky.social
doi.org/10.1162/opmi...
#AI #LLM #RL
Reposted by Nicolas Yax

Preprint update, co-led with @akjagadish.bsky.social, with @marvinmathony.bsky.social, Tobias Ludwig and @ericschulz.bsky.social!

Generating Computational Cognitive Models using Large Language Models
Computational cognitive models, which formalize theories of cognition, enable researchers to quantify cognitive processes and arbitrate between competing theories by fitting models to behavioral data....
arxiv.org
May 26, 2025 at 10:08 AM
Preprint update, co-led with @akjagadish.bsky.social, with @marvinmathony.bsky.social, Tobias Ludwig and @ericschulz.bsky.social!
Curious about LLM interpretability and understanding ? We borrowed concepts from genetics to map language models, predict their capabilities, and even uncovered surprising insights about their training !
Come see my poster at #ICLR2025 3pm Hall 2B #505 !
Come see my poster at #ICLR2025 3pm Hall 2B #505 !

April 26, 2025 at 2:03 AM
Curious about LLM interpretability and understanding ? We borrowed concepts from genetics to map language models, predict their capabilities, and even uncovered surprising insights about their training !
Come see my poster at #ICLR2025 3pm Hall 2B #505 !
Come see my poster at #ICLR2025 3pm Hall 2B #505 !
🔥Our paper PhyloLM got accepted at ICLR 2025 !🔥
In this work we show how easy it can be to infer relationship between LLMs by constructing trees and to predict their performances and behavior at a very low cost with @stepalminteri.bsky.social and @pyoudeyer.bsky.social ! Here is a brief recap ⬇️
In this work we show how easy it can be to infer relationship between LLMs by constructing trees and to predict their performances and behavior at a very low cost with @stepalminteri.bsky.social and @pyoudeyer.bsky.social ! Here is a brief recap ⬇️
April 24, 2025 at 1:15 PM
🔥Our paper PhyloLM got accepted at ICLR 2025 !🔥
In this work we show how easy it can be to infer relationship between LLMs by constructing trees and to predict their performances and behavior at a very low cost with @stepalminteri.bsky.social and @pyoudeyer.bsky.social ! Here is a brief recap ⬇️
In this work we show how easy it can be to infer relationship between LLMs by constructing trees and to predict their performances and behavior at a very low cost with @stepalminteri.bsky.social and @pyoudeyer.bsky.social ! Here is a brief recap ⬇️
Reposted by Nicolas Yax

🚀 Introducing 🧭MAGELLAN—our new metacognitive framework for LLM agents! It predicts its own learning progress (LP) in vast natural language goal spaces, enabling efficient exploration of complex domains.🌍✨Learn more: 🔗 arxiv.org/abs/2502.07709 #OpenEndedLearning #LLM #RL

MAGELLAN: Metacognitive predictions of learning progress guide...
Open-ended learning agents must efficiently prioritize goals in vast possibility spaces, focusing on those that maximize learning progress (LP). When such autotelic exploration is achieved by LLM...
arxiv.org
March 24, 2025 at 3:09 PM
🚀 Introducing 🧭MAGELLAN—our new metacognitive framework for LLM agents! It predicts its own learning progress (LP) in vast natural language goal spaces, enabling efficient exploration of complex domains.🌍✨Learn more: 🔗 arxiv.org/abs/2502.07709 #OpenEndedLearning #LLM #RL
Reposted by Nicolas Yax

we are recruiting interns for a few projects with @pyoudeyer
in bordeaux
> studying llm-mediated cultural evolution with @nisioti_eleni
@Jeremy__Perez
> balancing exploration and exploitation with autotelic rl with @ClementRomac
details and links in 🧵
please share!
in bordeaux
> studying llm-mediated cultural evolution with @nisioti_eleni
@Jeremy__Perez
> balancing exploration and exploitation with autotelic rl with @ClementRomac
details and links in 🧵
please share!
November 27, 2024 at 5:43 PM
we are recruiting interns for a few projects with @pyoudeyer
in bordeaux
> studying llm-mediated cultural evolution with @nisioti_eleni
@Jeremy__Perez
> balancing exploration and exploitation with autotelic rl with @ClementRomac
details and links in 🧵
please share!
in bordeaux
> studying llm-mediated cultural evolution with @nisioti_eleni
@Jeremy__Perez
> balancing exploration and exploitation with autotelic rl with @ClementRomac
details and links in 🧵
please share!
Reposted by Nicolas Yax

Putting some Flow Lenia here too
November 22, 2024 at 9:51 AM
Putting some Flow Lenia here too
Reposted by Nicolas Yax
1/⚡️Looking for a fast and simple Transformer baseline for your RL environment in JAX ?
Sharing my implementation of transformerXL-PPO: github.com/Reytuag/tran...
The implementation is the first to attain the 3rd floor and obtain advanced achievements in the challenging Craftax
Sharing my implementation of transformerXL-PPO: github.com/Reytuag/tran...
The implementation is the first to attain the 3rd floor and obtain advanced achievements in the challenging Craftax
November 22, 2024 at 10:16 AM
1/⚡️Looking for a fast and simple Transformer baseline for your RL environment in JAX ?
Sharing my implementation of transformerXL-PPO: github.com/Reytuag/tran...
The implementation is the first to attain the 3rd floor and obtain advanced achievements in the challenging Craftax
Sharing my implementation of transformerXL-PPO: github.com/Reytuag/tran...
The implementation is the first to attain the 3rd floor and obtain advanced achievements in the challenging Craftax
🚨New preprint🚨
When testing LLMs with questions, how can we know they did not see the answer in their training? In this new paper we propose a simple out of the box and fast method to spot contamination on short texts with @stepalminteri.bsky.social and Pierre-Yves Oudeyer !
When testing LLMs with questions, how can we know they did not see the answer in their training? In this new paper we propose a simple out of the box and fast method to spot contamination on short texts with @stepalminteri.bsky.social and Pierre-Yves Oudeyer !


November 15, 2024 at 1:48 PM
🚨New preprint🚨
When testing LLMs with questions, how can we know they did not see the answer in their training? In this new paper we propose a simple out of the box and fast method to spot contamination on short texts with @stepalminteri.bsky.social and Pierre-Yves Oudeyer !
When testing LLMs with questions, how can we know they did not see the answer in their training? In this new paper we propose a simple out of the box and fast method to spot contamination on short texts with @stepalminteri.bsky.social and Pierre-Yves Oudeyer !