



Onno Eberhard
@onnoeberhard.com
PhD Student in Tübingen (MPI-IS & Uni Tü), interested in reinforcement learning. Freedom is a pure idea. https://onnoeberhard.com/
Reposted by Onno Eberhard

Exciting workshop for RL enthusiasts in Mannheim! 👇
Workshop on Reinforcement Learning 2026, taking place on 𝐅𝐞𝐛𝐫𝐮𝐚𝐫𝐲 𝟔, 𝟐𝟎𝟐𝟔, at the 𝐔𝐧𝐢𝐯𝐞𝐫𝐬𝐢𝐭𝐲 𝐨𝐟 𝐌𝐚𝐧𝐧𝐡𝐞𝐢𝐦, Germany.
Participation in the workshop is 𝐟𝐫𝐞𝐞 𝐨𝐟 𝐜𝐡𝐚𝐫𝐠𝐞!
Check the program and register: www.wim.uni-mannheim.de/doering/conf...
Workshop on Reinforcement Learning 2026, taking place on 𝐅𝐞𝐛𝐫𝐮𝐚𝐫𝐲 𝟔, 𝟐𝟎𝟐𝟔, at the 𝐔𝐧𝐢𝐯𝐞𝐫𝐬𝐢𝐭𝐲 𝐨𝐟 𝐌𝐚𝐧𝐧𝐡𝐞𝐢𝐦, Germany.
Participation in the workshop is 𝐟𝐫𝐞𝐞 𝐨𝐟 𝐜𝐡𝐚𝐫𝐠𝐞!
Check the program and register: www.wim.uni-mannheim.de/doering/conf...

November 25, 2025 at 1:51 PM
Exciting workshop for RL enthusiasts in Mannheim! 👇
Workshop on Reinforcement Learning 2026, taking place on 𝐅𝐞𝐛𝐫𝐮𝐚𝐫𝐲 𝟔, 𝟐𝟎𝟐𝟔, at the 𝐔𝐧𝐢𝐯𝐞𝐫𝐬𝐢𝐭𝐲 𝐨𝐟 𝐌𝐚𝐧𝐧𝐡𝐞𝐢𝐦, Germany.
Participation in the workshop is 𝐟𝐫𝐞𝐞 𝐨𝐟 𝐜𝐡𝐚𝐫𝐠𝐞!
Check the program and register: www.wim.uni-mannheim.de/doering/conf...
Workshop on Reinforcement Learning 2026, taking place on 𝐅𝐞𝐛𝐫𝐮𝐚𝐫𝐲 𝟔, 𝟐𝟎𝟐𝟔, at the 𝐔𝐧𝐢𝐯𝐞𝐫𝐬𝐢𝐭𝐲 𝐨𝐟 𝐌𝐚𝐧𝐧𝐡𝐞𝐢𝐦, Germany.
Participation in the workshop is 𝐟𝐫𝐞𝐞 𝐨𝐟 𝐜𝐡𝐚𝐫𝐠𝐞!
Check the program and register: www.wim.uni-mannheim.de/doering/conf...
Reposted by Onno Eberhard

Nicolo Cesa-Bianchi and Matteo Papini are putting together a great unconference workshop at the @ellis.eu day at @euripsconf.bsky.social
If you want to talk about RL, causality, bandits, online learning, join us there on December 2nd
sites.google.com/view/ilir-wo...
If you want to talk about RL, causality, bandits, online learning, join us there on December 2nd
sites.google.com/view/ilir-wo...

ILIR Workshop, Dec 2, 2025
This workshop covers current research topics in reinforcement learning and causality, and in particular questions at the interface of these research areas. Of particular interest this year are also qu...
sites.google.com
October 16, 2025 at 10:04 PM
Nicolo Cesa-Bianchi and Matteo Papini are putting together a great unconference workshop at the @ellis.eu day at @euripsconf.bsky.social
If you want to talk about RL, causality, bandits, online learning, join us there on December 2nd
sites.google.com/view/ilir-wo...
If you want to talk about RL, causality, bandits, online learning, join us there on December 2nd
sites.google.com/view/ilir-wo...
Reposted by Onno Eberhard

I had such a great time helping organize EWRL 2025 with an amazing team 🎉
Loved being part of it and meeting so many passionate reinforcement learning enthusiasts!
@ewrl18.bsky.social
Loved being part of it and meeting so many passionate reinforcement learning enthusiasts!
@ewrl18.bsky.social

September 22, 2025 at 3:21 PM
I had such a great time helping organize EWRL 2025 with an amazing team 🎉
Loved being part of it and meeting so many passionate reinforcement learning enthusiasts!
@ewrl18.bsky.social
Loved being part of it and meeting so many passionate reinforcement learning enthusiasts!
@ewrl18.bsky.social
Reposted by Onno Eberhard

Truly chuffed for our fearless food physicists @mpipks.bsky.social + collabs from AT @istaresearch.bsky.social, IT & ES who won this year’s Ig Nobel - the #NobelPrize of hearts❤️for cracking the science of perfect pasta !🍝Kudos to all for intrepidly consuming lots of cheese in the name of science!😋

The Secret to a Smooth Pasta Sauce Wins Ig Nobel Prize
Italian researchers studied how the ingredients of the traditional Roman dish cacio e pepe emulsify into a creamy sauce, winning the 2025 Physics Ig Nobel Prize.
www.the-scientist.com
September 19, 2025 at 12:40 PM
Truly chuffed for our fearless food physicists @mpipks.bsky.social + collabs from AT @istaresearch.bsky.social, IT & ES who won this year’s Ig Nobel - the #NobelPrize of hearts❤️for cracking the science of perfect pasta !🍝Kudos to all for intrepidly consuming lots of cheese in the name of science!😋
I wrote a short post on our newest ICML paper addressed at people who are not experts in machine learning. Check it out!

In our latest blog post, @onnoeberhard.com writes about work presented at #ICML2025 on partially observable reinforcement learning which introduces an alternative memory framework - “memory traces”.
aihub.org/2025/09/12/m...
aihub.org/2025/09/12/m...

Memory traces in reinforcement learning - ΑΙhub
aihub.org
September 12, 2025 at 3:19 PM
I wrote a short post on our newest ICML paper addressed at people who are not experts in machine learning. Check it out!
A cute little animation: a critically damped harmonic oscillator becomes unstable with integral control if the gain is too high. Here, at K_i = 2, a Hopf bifurcation occurs: two poles of the transfer function enter the right-hand s-plane and the closed-loop system becomes unstable.
September 9, 2025 at 2:34 PM
A cute little animation: a critically damped harmonic oscillator becomes unstable with integral control if the gain is too high. Here, at K_i = 2, a Hopf bifurcation occurs: two poles of the transfer function enter the right-hand s-plane and the closed-loop system becomes unstable.
Reposted by Onno Eberhard
📣Registration for EWRL is now open📣
Register now 👇 and join us in Tübingen for 3 days (17th-19th September) full of inspiring talks, posters and many social activities to push the boundaries of the RL community!
Register now 👇 and join us in Tübingen for 3 days (17th-19th September) full of inspiring talks, posters and many social activities to push the boundaries of the RL community!
PheedLoop
PheedLoop: Hybrid, In-Person & Virtual Event Software
site.pheedloop.com
August 13, 2025 at 5:02 PM
📣Registration for EWRL is now open📣
Register now 👇 and join us in Tübingen for 3 days (17th-19th September) full of inspiring talks, posters and many social activities to push the boundaries of the RL community!
Register now 👇 and join us in Tübingen for 3 days (17th-19th September) full of inspiring talks, posters and many social activities to push the boundaries of the RL community!
Reposted by Onno Eberhard

I am going to present the poster during the next poster session. 11am Wed.
Poster W #707
Poster W #707

✨Introducing SENSEI✨ We bring semantically meaningful exploration to model-based RL using VLMs.
With intrinsic rewards for novel yet useful behaviors, SENSEI showcases strong exploration in MiniHack, Pokémon Red & Robodesk.
Accepted at ICML 2025🎉
Joint work with @cgumbsch.bsky.social
🧵
With intrinsic rewards for novel yet useful behaviors, SENSEI showcases strong exploration in MiniHack, Pokémon Red & Robodesk.
Accepted at ICML 2025🎉
Joint work with @cgumbsch.bsky.social
🧵
July 16, 2025 at 4:00 PM
I am going to present the poster during the next poster session. 11am Wed.
Poster W #707
Poster W #707
Reposted by Onno Eberhard

I really, really like this paper and as an open question, would love to see it tested on more memory benchmarks
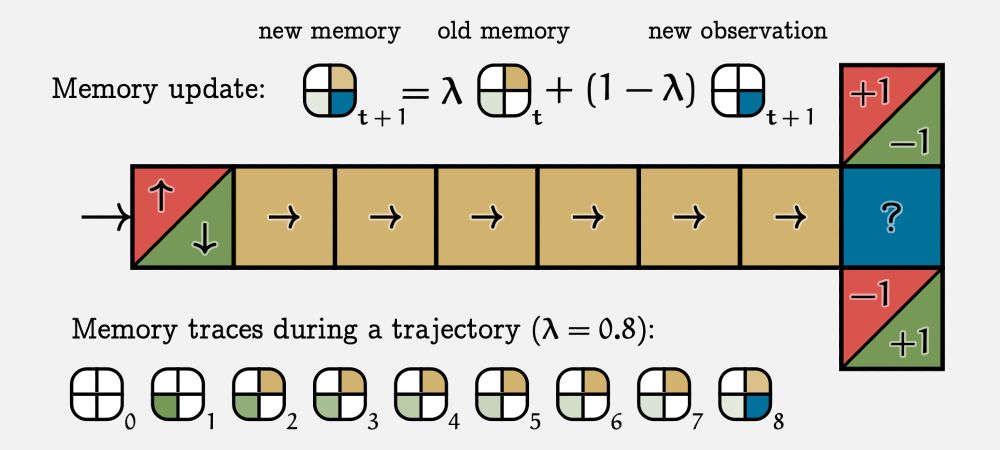
I am in Vancouver at ICML, and tomorrow I will present our newest paper "Partially Observable Reinforcement Learning with Memory Traces". We argue that eligibility traces are more effective than sliding windows as a memory mechanism for RL in POMDPs. 🧵
July 16, 2025 at 6:55 AM
I really, really like this paper and as an open question, would love to see it tested on more memory benchmarks
Reposted by Onno Eberhard
Onno and I will be presenting our poster at # W1005 tomorrow (Wed) morning.
He made a great thread about it, come chat with us about POMDP theory :)
He made a great thread about it, come chat with us about POMDP theory :)
I am in Vancouver at ICML, and tomorrow I will present our newest paper "Partially Observable Reinforcement Learning with Memory Traces". We argue that eligibility traces are more effective than sliding windows as a memory mechanism for RL in POMDPs. 🧵
July 16, 2025 at 3:45 AM
Onno and I will be presenting our poster at # W1005 tomorrow (Wed) morning.
He made a great thread about it, come chat with us about POMDP theory :)
He made a great thread about it, come chat with us about POMDP theory :)
I am in Vancouver at ICML, and tomorrow I will present our newest paper "Partially Observable Reinforcement Learning with Memory Traces". We argue that eligibility traces are more effective than sliding windows as a memory mechanism for RL in POMDPs. 🧵
July 16, 2025 at 1:35 AM
I am in Vancouver at ICML, and tomorrow I will present our newest paper "Partially Observable Reinforcement Learning with Memory Traces". We argue that eligibility traces are more effective than sliding windows as a memory mechanism for RL in POMDPs. 🧵
Great talk by @claireve.bsky.social about our joint work on memory traces this morning. Come join me at poster 94 if you want to know more! #RLDM2025

June 13, 2025 at 2:23 PM
Great talk by @claireve.bsky.social about our joint work on memory traces this morning. Come join me at poster 94 if you want to know more! #RLDM2025
Reposted by Onno Eberhard
This is a joint work with @onnoeberhard.com and Michael Mühlebach, and the poster will be presented by Onno tonight at #RLDM, and later in July at @icmlconf.bsky.social
June 13, 2025 at 9:41 AM
This is a joint work with @onnoeberhard.com and Michael Mühlebach, and the poster will be presented by Onno tonight at #RLDM, and later in July at @icmlconf.bsky.social
Reposted by Onno Eberhard
This morning at #RLDM I talked about Memory Traces, a simple representation for POMDPs that’s probably good at remembering old observations.
arxiv.org/abs/2503.15200
arxiv.org/abs/2503.15200

June 13, 2025 at 9:39 AM
This morning at #RLDM I talked about Memory Traces, a simple representation for POMDPs that’s probably good at remembering old observations.
arxiv.org/abs/2503.15200
arxiv.org/abs/2503.15200
Reposted by Onno Eberhard
Our work on Open Loop RL will be presented by @onnoeberhard.com at L4DC this week. He made a very nice summary thread ⬇️
I'm flying to Michigan today to present our new paper "A Pontryagin Perspective on Reinforcement Learning" at L4DC, where it has been nominated for the Best Paper Award! We ask the question: is it possible to learn an open-loop controller via RL? 🧵

June 4, 2025 at 7:23 PM
Our work on Open Loop RL will be presented by @onnoeberhard.com at L4DC this week. He made a very nice summary thread ⬇️
Reposted by Onno Eberhard
Super interesting work, take a look! 👀
I'm flying to Michigan today to present our new paper "A Pontryagin Perspective on Reinforcement Learning" at L4DC, where it has been nominated for the Best Paper Award! We ask the question: is it possible to learn an open-loop controller via RL? 🧵
June 4, 2025 at 8:13 AM
Super interesting work, take a look! 👀
I'm flying to Michigan today to present our new paper "A Pontryagin Perspective on Reinforcement Learning" at L4DC, where it has been nominated for the Best Paper Award! We ask the question: is it possible to learn an open-loop controller via RL? 🧵
June 4, 2025 at 8:06 AM
I'm flying to Michigan today to present our new paper "A Pontryagin Perspective on Reinforcement Learning" at L4DC, where it has been nominated for the Best Paper Award! We ask the question: is it possible to learn an open-loop controller via RL? 🧵
Reposted by Onno Eberhard
🎤 Meet the speakers!
Marcus Hutter (www.hutter1.net) is a Senior Researcher at DeepMind and Honorary Professor at ANU. His research focuses on the information-theoretic foundations of inductive reasoning and reinforcement learning.
⌛Still time to submit your paper or contributed talk proposal!
Marcus Hutter (www.hutter1.net) is a Senior Researcher at DeepMind and Honorary Professor at ANU. His research focuses on the information-theoretic foundations of inductive reasoning and reinforcement learning.
⌛Still time to submit your paper or contributed talk proposal!

May 30, 2025 at 8:24 AM
🎤 Meet the speakers!
Marcus Hutter (www.hutter1.net) is a Senior Researcher at DeepMind and Honorary Professor at ANU. His research focuses on the information-theoretic foundations of inductive reasoning and reinforcement learning.
⌛Still time to submit your paper or contributed talk proposal!
Marcus Hutter (www.hutter1.net) is a Senior Researcher at DeepMind and Honorary Professor at ANU. His research focuses on the information-theoretic foundations of inductive reasoning and reinforcement learning.
⌛Still time to submit your paper or contributed talk proposal!
Reposted by Onno Eberhard
🎤 Meet the speakers!
Peter Dayan (www.mpg.de/12309370/bio...) is Director of the MPI for Biological Cybernetics and a pioneer in neuroscience and AI.
His work focuses on brain decision-making, the role of neuromodulators and neuronal malfunctions in psychiatric diseases .
🕙 Still time to submit!
Peter Dayan (www.mpg.de/12309370/bio...) is Director of the MPI for Biological Cybernetics and a pioneer in neuroscience and AI.
His work focuses on brain decision-making, the role of neuromodulators and neuronal malfunctions in psychiatric diseases .
🕙 Still time to submit!

May 28, 2025 at 10:00 AM
🎤 Meet the speakers!
Peter Dayan (www.mpg.de/12309370/bio...) is Director of the MPI for Biological Cybernetics and a pioneer in neuroscience and AI.
His work focuses on brain decision-making, the role of neuromodulators and neuronal malfunctions in psychiatric diseases .
🕙 Still time to submit!
Peter Dayan (www.mpg.de/12309370/bio...) is Director of the MPI for Biological Cybernetics and a pioneer in neuroscience and AI.
His work focuses on brain decision-making, the role of neuromodulators and neuronal malfunctions in psychiatric diseases .
🕙 Still time to submit!
Reposted by Onno Eberhard
📢 Deadline extended!
Submit your work to EWRL — now accepting papers until June 3rd AoE.
This year, we're also offering a fast track for papers accepted at other conferences ⚡
Check the website for all the details: euro-workshop-on-reinforcement-learning.github.io/ewrl18/
Submit your work to EWRL — now accepting papers until June 3rd AoE.
This year, we're also offering a fast track for papers accepted at other conferences ⚡
Check the website for all the details: euro-workshop-on-reinforcement-learning.github.io/ewrl18/

May 26, 2025 at 2:47 PM
📢 Deadline extended!
Submit your work to EWRL — now accepting papers until June 3rd AoE.
This year, we're also offering a fast track for papers accepted at other conferences ⚡
Check the website for all the details: euro-workshop-on-reinforcement-learning.github.io/ewrl18/
Submit your work to EWRL — now accepting papers until June 3rd AoE.
This year, we're also offering a fast track for papers accepted at other conferences ⚡
Check the website for all the details: euro-workshop-on-reinforcement-learning.github.io/ewrl18/
Reposted by Onno Eberhard
News!⚡
We’re pleased to announce a new Call for Contributed Talks to bring novel and diverse viewpoints to EWRL2025.
Early-career researchers are especially encouraged to submit proposals and share their work with the community.
Full details: euro-workshop-on-reinforcement-learning.github.io/ewrl18/
We’re pleased to announce a new Call for Contributed Talks to bring novel and diverse viewpoints to EWRL2025.
Early-career researchers are especially encouraged to submit proposals and share their work with the community.
Full details: euro-workshop-on-reinforcement-learning.github.io/ewrl18/

May 23, 2025 at 8:04 AM
News!⚡
We’re pleased to announce a new Call for Contributed Talks to bring novel and diverse viewpoints to EWRL2025.
Early-career researchers are especially encouraged to submit proposals and share their work with the community.
Full details: euro-workshop-on-reinforcement-learning.github.io/ewrl18/
We’re pleased to announce a new Call for Contributed Talks to bring novel and diverse viewpoints to EWRL2025.
Early-career researchers are especially encouraged to submit proposals and share their work with the community.
Full details: euro-workshop-on-reinforcement-learning.github.io/ewrl18/
Reposted by Onno Eberhard
Still a few days left to submit! ⌛ Don’t miss out!
Check the website for all the details: euro-workshop-on-reinforcement-learning.github.io/ewrl18/
Check the website for all the details: euro-workshop-on-reinforcement-learning.github.io/ewrl18/

May 19, 2025 at 10:03 AM
Still a few days left to submit! ⌛ Don’t miss out!
Check the website for all the details: euro-workshop-on-reinforcement-learning.github.io/ewrl18/
Check the website for all the details: euro-workshop-on-reinforcement-learning.github.io/ewrl18/
EWRL has been my favorite conference experience so far. Very excited that we are organizing it in Tübingen this year!
Mark your calendars, EWRL is coming to Tübingen! 📅
When? September 17-19, 2025.
More news to come soon, stay tuned!
When? September 17-19, 2025.
More news to come soon, stay tuned!

April 15, 2025 at 11:05 AM
EWRL has been my favorite conference experience so far. Very excited that we are organizing it in Tübingen this year!
Reposted by Onno Eberhard
Mark your calendars, EWRL is coming to Tübingen! 📅
When? September 17-19, 2025.
More news to come soon, stay tuned!
When? September 17-19, 2025.
More news to come soon, stay tuned!
April 8, 2025 at 8:33 AM
Mark your calendars, EWRL is coming to Tübingen! 📅
When? September 17-19, 2025.
More news to come soon, stay tuned!
When? September 17-19, 2025.
More news to come soon, stay tuned!
Truly inspiring work.

Are you tired of context-switching between coding models in @pytorch.org and paper writing on @overleaf.com?
Well, I’ve got the fix for you, Neuralatex! An ML library written in pure Latex!
neuralatex.com
To appear in Sigbovik (subject to rigorous review process)
Well, I’ve got the fix for you, Neuralatex! An ML library written in pure Latex!
neuralatex.com
To appear in Sigbovik (subject to rigorous review process)
Neuralatex: A machine learning library written in pure LATEX
Neuralatex: A machine learning library written in pure LATEX
neuralatex.com
April 1, 2025 at 4:36 PM
Truly inspiring work.