



Parishad BehnamGhader
@parishadbehnam.bsky.social
PhD student at McGill University and Mila — Quebec AI Institute
Reposted by Parishad BehnamGhader

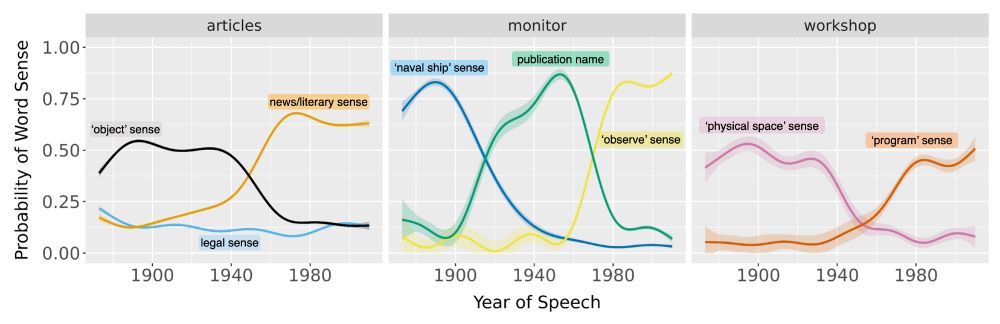
Our new paper in #PNAS (bit.ly/4fcWfma) presents a surprising finding—when words change meaning, older speakers rapidly adopt the new usage; inter-generational differences are often minor.
w/ Michelle Yang, @sivareddyg.bsky.social , @msonderegger.bsky.social and @dallascard.bsky.social👇(1/12)
w/ Michelle Yang, @sivareddyg.bsky.social , @msonderegger.bsky.social and @dallascard.bsky.social👇(1/12)
July 29, 2025 at 12:06 PM
Our new paper in #PNAS (bit.ly/4fcWfma) presents a surprising finding—when words change meaning, older speakers rapidly adopt the new usage; inter-generational differences are often minor.
w/ Michelle Yang, @sivareddyg.bsky.social , @msonderegger.bsky.social and @dallascard.bsky.social👇(1/12)
w/ Michelle Yang, @sivareddyg.bsky.social , @msonderegger.bsky.social and @dallascard.bsky.social👇(1/12)
Reposted by Parishad BehnamGhader

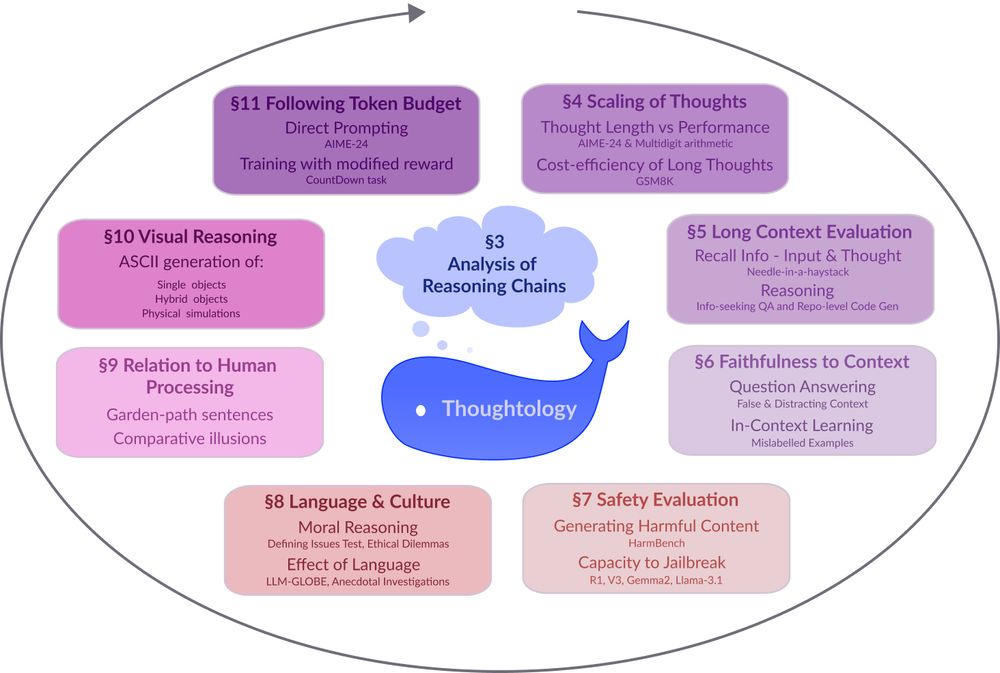
Models like DeepSeek-R1 🐋 mark a fundamental shift in how LLMs approach complex problems. In our preprint on R1 Thoughtology, we study R1’s reasoning chains across a variety of tasks; investigating its capabilities, limitations, and behaviour.
🔗: mcgill-nlp.github.io/thoughtology/
🔗: mcgill-nlp.github.io/thoughtology/
April 1, 2025 at 8:07 PM
Models like DeepSeek-R1 🐋 mark a fundamental shift in how LLMs approach complex problems. In our preprint on R1 Thoughtology, we study R1’s reasoning chains across a variety of tasks; investigating its capabilities, limitations, and behaviour.
🔗: mcgill-nlp.github.io/thoughtology/
🔗: mcgill-nlp.github.io/thoughtology/
Instruction-following retrievers can efficiently and accurately search for harmful and sensitive information on the internet! 🌐💣
Retrievers need to be aligned too! 🚨🚨🚨
Work done with the wonderful Nick and @sivareddyg.bsky.social
🔗 mcgill-nlp.github.io/malicious-ir/
Thread: 🧵👇
Retrievers need to be aligned too! 🚨🚨🚨
Work done with the wonderful Nick and @sivareddyg.bsky.social
🔗 mcgill-nlp.github.io/malicious-ir/
Thread: 🧵👇
Exploiting Instruction-Following Retrievers for Malicious Information Retrieval
Parishad BehnamGhader, Nicholas Meade, Siva Reddy
mcgill-nlp.github.io
March 12, 2025 at 4:15 PM
Instruction-following retrievers can efficiently and accurately search for harmful and sensitive information on the internet! 🌐💣
Retrievers need to be aligned too! 🚨🚨🚨
Work done with the wonderful Nick and @sivareddyg.bsky.social
🔗 mcgill-nlp.github.io/malicious-ir/
Thread: 🧵👇
Retrievers need to be aligned too! 🚨🚨🚨
Work done with the wonderful Nick and @sivareddyg.bsky.social
🔗 mcgill-nlp.github.io/malicious-ir/
Thread: 🧵👇
Reposted by Parishad BehnamGhader

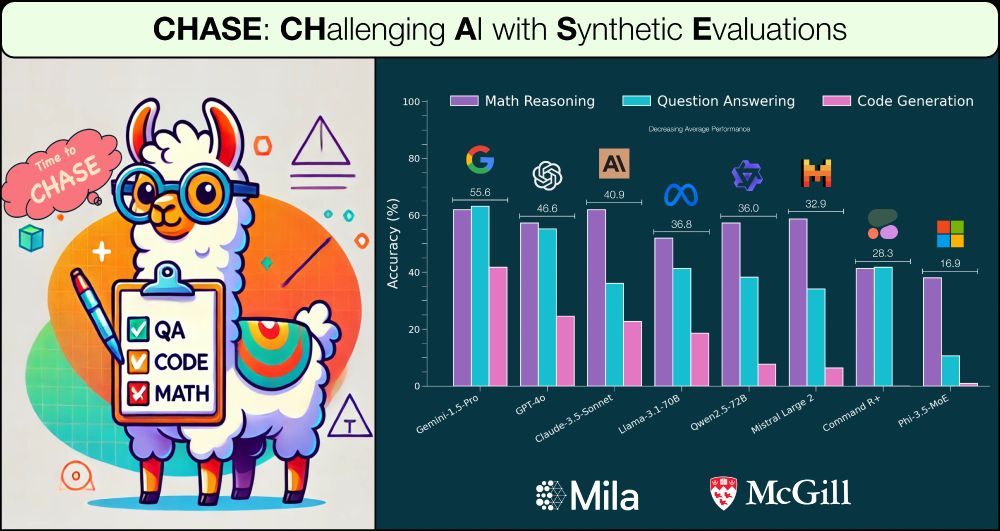
Presenting ✨ 𝐂𝐇𝐀𝐒𝐄: 𝐆𝐞𝐧𝐞𝐫𝐚𝐭𝐢𝐧𝐠 𝐜𝐡𝐚𝐥𝐥𝐞𝐧𝐠𝐢𝐧𝐠 𝐬𝐲𝐧𝐭𝐡𝐞𝐭𝐢𝐜 𝐝𝐚𝐭𝐚 𝐟𝐨𝐫 𝐞𝐯𝐚𝐥𝐮𝐚𝐭𝐢𝐨𝐧 ✨
Work w/ fantastic advisors Dima Bahdanau and @sivareddyg.bsky.social
Thread 🧵:
Work w/ fantastic advisors Dima Bahdanau and @sivareddyg.bsky.social
Thread 🧵:
February 21, 2025 at 4:29 PM
Presenting ✨ 𝐂𝐇𝐀𝐒𝐄: 𝐆𝐞𝐧𝐞𝐫𝐚𝐭𝐢𝐧𝐠 𝐜𝐡𝐚𝐥𝐥𝐞𝐧𝐠𝐢𝐧𝐠 𝐬𝐲𝐧𝐭𝐡𝐞𝐭𝐢𝐜 𝐝𝐚𝐭𝐚 𝐟𝐨𝐫 𝐞𝐯𝐚𝐥𝐮𝐚𝐭𝐢𝐨𝐧 ✨
Work w/ fantastic advisors Dima Bahdanau and @sivareddyg.bsky.social
Thread 🧵:
Work w/ fantastic advisors Dima Bahdanau and @sivareddyg.bsky.social
Thread 🧵: