




Sebastian Schuster
@sebschu.bsky.social
Computational semantics and pragmatics, interpretability and occasionally some psycholinguistics. he/him. 🦝
https://sebschu.com
https://sebschu.com
Reposted by Sebastian Schuster

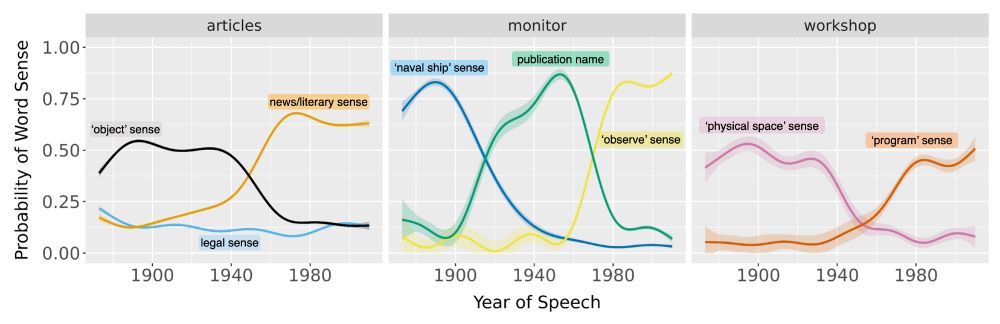
Our new paper in #PNAS (bit.ly/4fcWfma) presents a surprising finding—when words change meaning, older speakers rapidly adopt the new usage; inter-generational differences are often minor.
w/ Michelle Yang, @sivareddyg.bsky.social , @msonderegger.bsky.social and @dallascard.bsky.social👇(1/12)
w/ Michelle Yang, @sivareddyg.bsky.social , @msonderegger.bsky.social and @dallascard.bsky.social👇(1/12)
July 29, 2025 at 12:06 PM
Our new paper in #PNAS (bit.ly/4fcWfma) presents a surprising finding—when words change meaning, older speakers rapidly adopt the new usage; inter-generational differences are often minor.
w/ Michelle Yang, @sivareddyg.bsky.social , @msonderegger.bsky.social and @dallascard.bsky.social👇(1/12)
w/ Michelle Yang, @sivareddyg.bsky.social , @msonderegger.bsky.social and @dallascard.bsky.social👇(1/12)
Reposted by Sebastian Schuster

👾 Full-time research assistant position (1 year) with @sebschu.bsky.social and me! 👾
We're looking for someone to join the research agent evaluation team, starting Fall 2025. Application link to be available soon, but feel free to send us your CV and/or come talk to us at #ACL2025. 🧵
We're looking for someone to join the research agent evaluation team, starting Fall 2025. Application link to be available soon, but feel free to send us your CV and/or come talk to us at #ACL2025. 🧵
July 25, 2025 at 5:08 PM
👾 Full-time research assistant position (1 year) with @sebschu.bsky.social and me! 👾
We're looking for someone to join the research agent evaluation team, starting Fall 2025. Application link to be available soon, but feel free to send us your CV and/or come talk to us at #ACL2025. 🧵
We're looking for someone to join the research agent evaluation team, starting Fall 2025. Application link to be available soon, but feel free to send us your CV and/or come talk to us at #ACL2025. 🧵
Can coding agents autonomously implement AI research extensions?
We introduce RExBench, a benchmark that tests if a coding agent can implement a novel experiment based on existing research and code.
Finding: Most agents we tested had a low success rate, but there is promise!
We introduce RExBench, a benchmark that tests if a coding agent can implement a novel experiment based on existing research and code.
Finding: Most agents we tested had a low success rate, but there is promise!

July 2, 2025 at 3:40 PM
Can coding agents autonomously implement AI research extensions?
We introduce RExBench, a benchmark that tests if a coding agent can implement a novel experiment based on existing research and code.
Finding: Most agents we tested had a low success rate, but there is promise!
We introduce RExBench, a benchmark that tests if a coding agent can implement a novel experiment based on existing research and code.
Finding: Most agents we tested had a low success rate, but there is promise!