




Marc Lanctot
@sharky6000.bsky.social
Research Scientist at Google DeepMind, interested in multiagent reinforcement learning, game theory, games, and search/planning.
Lover of Linux 🐧, coffee ☕, and retro gaming. Big fan of open-source. #gohabsgo 🇨🇦
For more info: https://linktr.ee/sharky6000
Lover of Linux 🐧, coffee ☕, and retro gaming. Big fan of open-source. #gohabsgo 🇨🇦
For more info: https://linktr.ee/sharky6000
Pinned
Marc Lanctot
@sharky6000.bsky.social
· Oct 9

Hello all! 👋 🚨 New Preprint Alert! 🚨
Code World Models for General Game-Playing. ♟️🎲 ♣️♥️♠️♦️
I am pleased to announce our new paper, which provides an extremely sample-efficient way to create an agent that can perform well in multi-agent, partially-observed, symbolic environments!
🧵 1/N
Code World Models for General Game-Playing. ♟️🎲 ♣️♥️♠️♦️
I am pleased to announce our new paper, which provides an extremely sample-efficient way to create an agent that can perform well in multi-agent, partially-observed, symbolic environments!
🧵 1/N

Reposted by Marc Lanctot

9% of papers and 21% of reviews at ICLR 2026 are predicted to be AI generated. We live in interesting times. Caveat: I’m not familiar with the detection methods. But I could easily be persuaded that these are realistic numbers. www.pangram.com/blog/pangram...

Pangram Predicts 21% of ICLR Reviews are AI-Generated | Pangram Labs
Pangram performed an analysis of all papers and peer reviews submitted to ICLR, a major machine learning publication venue.
www.pangram.com
November 27, 2025 at 5:34 AM
9% of papers and 21% of reviews at ICLR 2026 are predicted to be AI generated. We live in interesting times. Caveat: I’m not familiar with the detection methods. But I could easily be persuaded that these are realistic numbers. www.pangram.com/blog/pangram...
Reposted by Marc Lanctot

Thrilled to present HyperMARL at #NeurIPS2025 in San Diego next week! 🚀 (Amos will present at
@euripsconf.bsky.social too.)
TL;DR: Coupling obs and agent IDs can hurt performance in MARL. Agent-conditioned hypernets cleanly decouple grads and enable specialisation.
📜: arxiv.org/abs/2412.04233
@euripsconf.bsky.social too.)
TL;DR: Coupling obs and agent IDs can hurt performance in MARL. Agent-conditioned hypernets cleanly decouple grads and enable specialisation.
📜: arxiv.org/abs/2412.04233

November 26, 2025 at 4:07 PM
Thrilled to present HyperMARL at #NeurIPS2025 in San Diego next week! 🚀 (Amos will present at
@euripsconf.bsky.social too.)
TL;DR: Coupling obs and agent IDs can hurt performance in MARL. Agent-conditioned hypernets cleanly decouple grads and enable specialisation.
📜: arxiv.org/abs/2412.04233
@euripsconf.bsky.social too.)
TL;DR: Coupling obs and agent IDs can hurt performance in MARL. Agent-conditioned hypernets cleanly decouple grads and enable specialisation.
📜: arxiv.org/abs/2412.04233
Also, value functions will soon be cool again! 👍 thank you pistar_0.6 .. and Ilya thinks they will be used more in the future 🙏
On emotions and value functions: youtu.be/aR20FWCCjAs?...
On emotions and value functions: youtu.be/aR20FWCCjAs?...

Ilya Sutskever – We're moving from the age of scaling to the age of research
YouTube video by Dwarkesh Patel
youtu.be
November 26, 2025 at 3:13 PM
Also, value functions will soon be cool again! 👍 thank you pistar_0.6 .. and Ilya thinks they will be used more in the future 🙏
On emotions and value functions: youtu.be/aR20FWCCjAs?...
On emotions and value functions: youtu.be/aR20FWCCjAs?...
What is the human analogy to pretraining? Learning up to the age of 15 where you have general knowledge but not economically productive? Or more like evolution, where it's a massive search over many years which produces a human lifetime instance?
youtu.be/aR20FWCCjAs?...
youtu.be/aR20FWCCjAs?...
Ilya Sutskever – We're moving from the age of scaling to the age of research
YouTube video by Dwarkesh Patel
youtu.be
November 26, 2025 at 3:08 PM
What is the human analogy to pretraining? Learning up to the age of 15 where you have general knowledge but not economically productive? Or more like evolution, where it's a massive search over many years which produces a human lifetime instance?
youtu.be/aR20FWCCjAs?...
youtu.be/aR20FWCCjAs?...
Ilya: "Suppose you have two students doing competitive programming. Student 1 collects all the possible type of questions, studies for thousands of hours conquering them all. Student 2 studies much less, maybe 100 hours. Both perform comparatively. Which one goes on to have a better career?"
November 26, 2025 at 11:04 AM
Ilya: "Suppose you have two students doing competitive programming. Student 1 collects all the possible type of questions, studies for thousands of hours conquering them all. Student 2 studies much less, maybe 100 hours. Both perform comparatively. Which one goes on to have a better career?"
Ilya: "One thing you could do-- and I think this is done inadvertently-- is take inspiration from the evaluation." then goes on to imply that overfitting to evals could explain lack of generalization.
Why the heck am I hearing this for the first time in late 2025?
Why the heck am I hearing this for the first time in late 2025?
November 26, 2025 at 3:26 AM
Ilya: "One thing you could do-- and I think this is done inadvertently-- is take inspiration from the evaluation." then goes on to imply that overfitting to evals could explain lack of generalization.
Why the heck am I hearing this for the first time in late 2025?
Why the heck am I hearing this for the first time in late 2025?
Reposted by Marc Lanctot

🎉 New work: “Learning Massively Multitask World Models for Continuous Control”
We introduce MMBench: a 200-task RL benchmark, and Newt: a language-conditioned multitask world model trained with large-scale online RL.
www.nicklashansen.com/NewtWM/
Code, checkpoints, dataset etc. are open-source!
We introduce MMBench: a 200-task RL benchmark, and Newt: a language-conditioned multitask world model trained with large-scale online RL.
www.nicklashansen.com/NewtWM/
Code, checkpoints, dataset etc. are open-source!
November 25, 2025 at 7:47 PM
🎉 New work: “Learning Massively Multitask World Models for Continuous Control”
We introduce MMBench: a 200-task RL benchmark, and Newt: a language-conditioned multitask world model trained with large-scale online RL.
www.nicklashansen.com/NewtWM/
Code, checkpoints, dataset etc. are open-source!
We introduce MMBench: a 200-task RL benchmark, and Newt: a language-conditioned multitask world model trained with large-scale online RL.
www.nicklashansen.com/NewtWM/
Code, checkpoints, dataset etc. are open-source!
Reposted by Marc Lanctot

🚀 Introducing TMLR Beyond PDF!
🎬 This is a new, HTML-based submission format for TMLR, that supports interactive figures and videos, along with the usual LaTeX and images.
🎉 Thanks to TMLR Editors in Chief: Hugo Larochelle, @gautamkamath.com, Naila Murray, Nihar B. Shah, and Laurent Charlin!
🎬 This is a new, HTML-based submission format for TMLR, that supports interactive figures and videos, along with the usual LaTeX and images.
🎉 Thanks to TMLR Editors in Chief: Hugo Larochelle, @gautamkamath.com, Naila Murray, Nihar B. Shah, and Laurent Charlin!
November 25, 2025 at 4:12 PM
🚀 Introducing TMLR Beyond PDF!
🎬 This is a new, HTML-based submission format for TMLR, that supports interactive figures and videos, along with the usual LaTeX and images.
🎉 Thanks to TMLR Editors in Chief: Hugo Larochelle, @gautamkamath.com, Naila Murray, Nihar B. Shah, and Laurent Charlin!
🎬 This is a new, HTML-based submission format for TMLR, that supports interactive figures and videos, along with the usual LaTeX and images.
🎉 Thanks to TMLR Editors in Chief: Hugo Larochelle, @gautamkamath.com, Naila Murray, Nihar B. Shah, and Laurent Charlin!
Reposted by Marc Lanctot

TMLR (@tmlrorg.bsky.social) is now proud to support interactive HTML-based submissions, going "Beyond PDF" -- check it out!
Thanks to Paul Vicol (@paulvicol.bsky.social) for his tireless work on this new option, as well as the OpenReview team.
Thanks to Paul Vicol (@paulvicol.bsky.social) for his tireless work on this new option, as well as the OpenReview team.
🚀 Introducing TMLR Beyond PDF!
🎬 This is a new, HTML-based submission format for TMLR, that supports interactive figures and videos, along with the usual LaTeX and images.
🎉 Thanks to TMLR Editors in Chief: Hugo Larochelle, @gautamkamath.com, Naila Murray, Nihar B. Shah, and Laurent Charlin!
🎬 This is a new, HTML-based submission format for TMLR, that supports interactive figures and videos, along with the usual LaTeX and images.
🎉 Thanks to TMLR Editors in Chief: Hugo Larochelle, @gautamkamath.com, Naila Murray, Nihar B. Shah, and Laurent Charlin!
November 25, 2025 at 4:14 PM
TMLR (@tmlrorg.bsky.social) is now proud to support interactive HTML-based submissions, going "Beyond PDF" -- check it out!
Thanks to Paul Vicol (@paulvicol.bsky.social) for his tireless work on this new option, as well as the OpenReview team.
Thanks to Paul Vicol (@paulvicol.bsky.social) for his tireless work on this new option, as well as the OpenReview team.
I've had this song on repeat for practically the whole weekend.
It brings me back to the good ol' days .. late 90's / early 2000s when I first go into EDM. I'd listen to this kind of stuff for hours.
Anybody see this song played live?
And I think it's a reference to.. 👇
youtu.be/degq0sxYlLI?...
It brings me back to the good ol' days .. late 90's / early 2000s when I first go into EDM. I'd listen to this kind of stuff for hours.
Anybody see this song played live?
And I think it's a reference to.. 👇
youtu.be/degq0sxYlLI?...

Midnight Runner
YouTube video by Pendulum - Topic
youtu.be
November 24, 2025 at 2:09 AM
I've had this song on repeat for practically the whole weekend.
It brings me back to the good ol' days .. late 90's / early 2000s when I first go into EDM. I'd listen to this kind of stuff for hours.
Anybody see this song played live?
And I think it's a reference to.. 👇
youtu.be/degq0sxYlLI?...
It brings me back to the good ol' days .. late 90's / early 2000s when I first go into EDM. I'd listen to this kind of stuff for hours.
Anybody see this song played live?
And I think it's a reference to.. 👇
youtu.be/degq0sxYlLI?...
Thought question: AI in your operating system.. a step too far, or bring it on? 🤔
November 23, 2025 at 11:36 PM
Thought question: AI in your operating system.. a step too far, or bring it on? 🤔
Reposted by Marc Lanctot

Pluribus on Apple TV is such a great show - infuriatingly difficult to recommend though since it's so easy to spoil the experience if you share too many details
Just watch it, it's great!
Just watch it, it's great!
November 22, 2025 at 5:29 AM
Pluribus on Apple TV is such a great show - infuriatingly difficult to recommend though since it's so easy to spoil the experience if you share too many details
Just watch it, it's great!
Just watch it, it's great!
Reposted by Marc Lanctot

Grand opening, grand closing.
X quietly disabled a new feature that showed which country an account was posting from when it revealed that lots of popular right wing MAGA accounts were being run from foreign countries like India and Nigeria.
X quietly disabled a new feature that showed which country an account was posting from when it revealed that lots of popular right wing MAGA accounts were being run from foreign countries like India and Nigeria.


November 22, 2025 at 9:05 PM
Grand opening, grand closing.
X quietly disabled a new feature that showed which country an account was posting from when it revealed that lots of popular right wing MAGA accounts were being run from foreign countries like India and Nigeria.
X quietly disabled a new feature that showed which country an account was posting from when it revealed that lots of popular right wing MAGA accounts were being run from foreign countries like India and Nigeria.
T'is the season 🥰🎄


November 22, 2025 at 12:09 AM
T'is the season 🥰🎄
Reposted by Marc Lanctot

The new Nano Banana Pro model (based on Gemini 3) is just incredible!!!
I always wanted to create a nice Gemma timeline for my presentations but I'm not that good with drawing tools
With just one prompt I managed to create something pretty cool!!
I always wanted to create a nice Gemma timeline for my presentations but I'm not that good with drawing tools
With just one prompt I managed to create something pretty cool!!
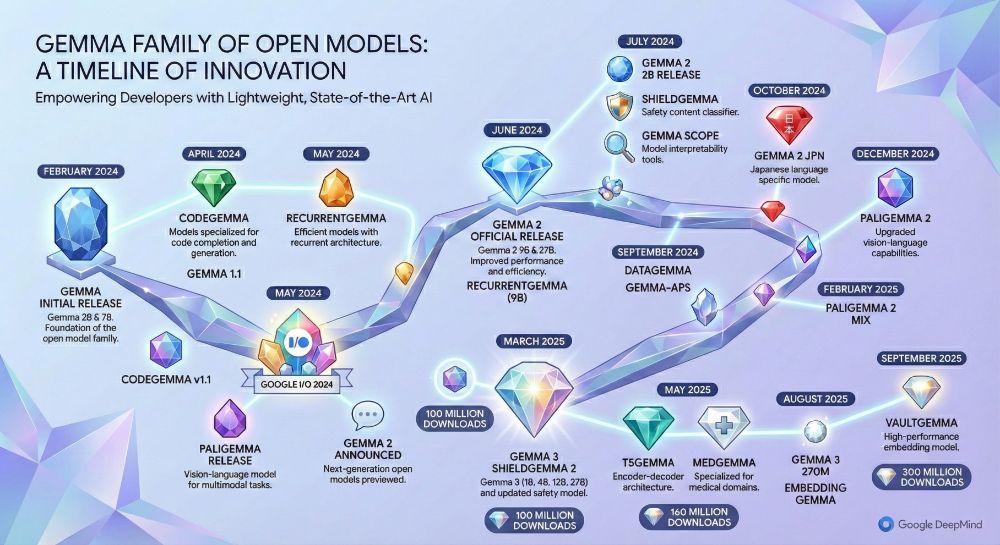
November 21, 2025 at 10:31 AM
The new Nano Banana Pro model (based on Gemini 3) is just incredible!!!
I always wanted to create a nice Gemma timeline for my presentations but I'm not that good with drawing tools
With just one prompt I managed to create something pretty cool!!
I always wanted to create a nice Gemma timeline for my presentations but I'm not that good with drawing tools
With just one prompt I managed to create something pretty cool!!
Reposted by Marc Lanctot

Once again astonished that Elon is building a propaganda machine in public, saying "hello, here is my propaganda machine", and the tech community continues to use it
November 21, 2025 at 12:06 AM
Once again astonished that Elon is building a propaganda machine in public, saying "hello, here is my propaganda machine", and the tech community continues to use it
Check this out! "Google Scholar Labs helps you answer research questions with AI" share.google/aKBsEebfos7c...

We’re introducing Google Scholar Labs to answer your research questions.
Today, we are introducing Google Scholar Labs, a new feature that explores how generative AI can transform the process of answering detailed scholarly research questions…
share.google
November 20, 2025 at 11:03 AM
Check this out! "Google Scholar Labs helps you answer research questions with AI" share.google/aKBsEebfos7c...
Reposted by Marc Lanctot

My lab is looking for new students who are very passionate about foundational models and planning/RL/robotics. Apply via Mila. I will also be at #NeurIPS to discuss research ideas and opportunities. See notes below for application advice.

November 19, 2025 at 3:10 PM
My lab is looking for new students who are very passionate about foundational models and planning/RL/robotics. Apply via Mila. I will also be at #NeurIPS to discuss research ideas and opportunities. See notes below for application advice.
Reposted by Marc Lanctot

I'm looking for two PhD student for Fall 2026. Both on multi-agent reinforcement learning (MARL).
- Theory of MARL: experience with theory and/or MARL
-Formal methods for MARL: experience with formal methods or MARL (interest in learning the other)
www.khoury.northeastern.edu/programs/com...
- Theory of MARL: experience with theory and/or MARL
-Formal methods for MARL: experience with formal methods or MARL (interest in learning the other)
www.khoury.northeastern.edu/programs/com...

PhD in Computer Science - Khoury College of Computer Sciences
The PhD in Computer Science program will prepare you with advanced knowledge, industry opportunities, and research experience to be a leader in the field.
www.khoury.northeastern.edu
November 19, 2025 at 2:30 PM
I'm looking for two PhD student for Fall 2026. Both on multi-agent reinforcement learning (MARL).
- Theory of MARL: experience with theory and/or MARL
-Formal methods for MARL: experience with formal methods or MARL (interest in learning the other)
www.khoury.northeastern.edu/programs/com...
- Theory of MARL: experience with theory and/or MARL
-Formal methods for MARL: experience with formal methods or MARL (interest in learning the other)
www.khoury.northeastern.edu/programs/com...
Reposted by Marc Lanctot

I’m really excited about our release of Gemini 3 today, the result of hard work by many, many people in the Gemini team and all across Google! 🎊
blog.google/products/gem...
Gemini 3 performs quite well on a wide range of benchmarks.
blog.google/products/gem...
Gemini 3 performs quite well on a wide range of benchmarks.

November 19, 2025 at 2:53 AM
I’m really excited about our release of Gemini 3 today, the result of hard work by many, many people in the Gemini team and all across Google! 🎊
blog.google/products/gem...
Gemini 3 performs quite well on a wide range of benchmarks.
blog.google/products/gem...
Gemini 3 performs quite well on a wide range of benchmarks.
Reposted by Marc Lanctot

Learn more about how Gemini 3 can help you learn, build and plan anything → goo.gle/4oUEkVu

A new era of intelligence with Gemini 3
Today we’re releasing Gemini 3 – our most intelligent model that helps you bring any idea to life.
goo.gle
November 18, 2025 at 4:53 PM
Learn more about how Gemini 3 can help you learn, build and plan anything → goo.gle/4oUEkVu
Reposted by Marc Lanctot


Reposted by Marc Lanctot


Reposted by Marc Lanctot

Gemini 3 is now available for developers ✨
Combined with its advanced understanding of the real world, Gemini 3 Pro is our most intelligent model for building complex apps.
goo.gle/43ADuV6
Combined with its advanced understanding of the real world, Gemini 3 Pro is our most intelligent model for building complex apps.
goo.gle/43ADuV6

Start building with Gemini 3
Gemini 3 is introducing advanced agentic coding capabilities, plus Google Antigravity, a new agentic development platform.
goo.gle
November 18, 2025 at 4:22 PM
Gemini 3 is now available for developers ✨
Combined with its advanced understanding of the real world, Gemini 3 Pro is our most intelligent model for building complex apps.
goo.gle/43ADuV6
Combined with its advanced understanding of the real world, Gemini 3 Pro is our most intelligent model for building complex apps.
goo.gle/43ADuV6