



Shoubin Yu
@shoubin.bsky.social
Ph.D. Student at UNC CS. Interested in multimodal video understanding&generation.
https://yui010206.github.io/
https://yui010206.github.io/
Reposted by Shoubin Yu

🚨 Introducing our @tmlrorg.bsky.social paper “Unlearning Sensitive Information in Multimodal LLMs: Benchmark and Attack-Defense Evaluation”
We present UnLOK-VQA, a benchmark to evaluate unlearning in vision-and-language models, where both images and text may encode sensitive or private information.
We present UnLOK-VQA, a benchmark to evaluate unlearning in vision-and-language models, where both images and text may encode sensitive or private information.

May 7, 2025 at 6:55 PM
🚨 Introducing our @tmlrorg.bsky.social paper “Unlearning Sensitive Information in Multimodal LLMs: Benchmark and Attack-Defense Evaluation”
We present UnLOK-VQA, a benchmark to evaluate unlearning in vision-and-language models, where both images and text may encode sensitive or private information.
We present UnLOK-VQA, a benchmark to evaluate unlearning in vision-and-language models, where both images and text may encode sensitive or private information.
Flying to SG 🇸🇬 to attend #ICLR2025.
Check out our 3 papers:
☕️CREMA: Video-language + any modality reasoning
🛡️SAFREE: A training-free concept guard for any visual diffusion models
🧭SRDF: Human-level VL-navigation via self-refined data loop
feel free to DM me to grab a coffee&citywalk together 😉
Check out our 3 papers:
☕️CREMA: Video-language + any modality reasoning
🛡️SAFREE: A training-free concept guard for any visual diffusion models
🧭SRDF: Human-level VL-navigation via self-refined data loop
feel free to DM me to grab a coffee&citywalk together 😉
In Singapore for #ICLR2025 this week to present papers + keynotes 👇, and looking forward to seeing everyone -- happy to chat about research, or faculty+postdoc+phd positions, or simply hanging out (feel free to ping)! 🙂
Also meet our awesome students/postdocs/collaborators presenting their work.
Also meet our awesome students/postdocs/collaborators presenting their work.

April 22, 2025 at 12:09 AM
Flying to SG 🇸🇬 to attend #ICLR2025.
Check out our 3 papers:
☕️CREMA: Video-language + any modality reasoning
🛡️SAFREE: A training-free concept guard for any visual diffusion models
🧭SRDF: Human-level VL-navigation via self-refined data loop
feel free to DM me to grab a coffee&citywalk together 😉
Check out our 3 papers:
☕️CREMA: Video-language + any modality reasoning
🛡️SAFREE: A training-free concept guard for any visual diffusion models
🧭SRDF: Human-level VL-navigation via self-refined data loop
feel free to DM me to grab a coffee&citywalk together 😉
Reposted by Shoubin Yu

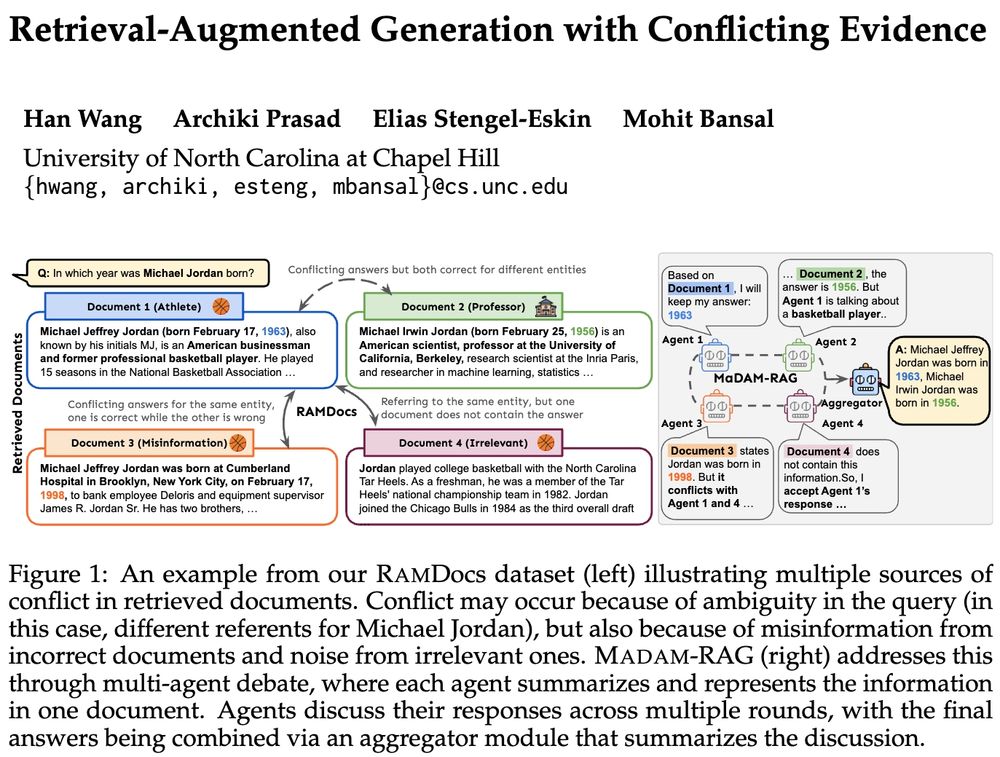
🚨Real-world retrieval is messy: queries are ambiguous or docs conflict & have incorrect/irrelevant info. How can we jointly address these problems?
➡️RAMDocs: challenging dataset w/ ambiguity, misinformation & noise
➡️MADAM-RAG: multi-agent framework, debates & aggregates evidence across sources
🧵⬇️
➡️RAMDocs: challenging dataset w/ ambiguity, misinformation & noise
➡️MADAM-RAG: multi-agent framework, debates & aggregates evidence across sources
🧵⬇️
April 18, 2025 at 5:06 PM
🚨Real-world retrieval is messy: queries are ambiguous or docs conflict & have incorrect/irrelevant info. How can we jointly address these problems?
➡️RAMDocs: challenging dataset w/ ambiguity, misinformation & noise
➡️MADAM-RAG: multi-agent framework, debates & aggregates evidence across sources
🧵⬇️
➡️RAMDocs: challenging dataset w/ ambiguity, misinformation & noise
➡️MADAM-RAG: multi-agent framework, debates & aggregates evidence across sources
🧵⬇️
Reposted by Shoubin Yu

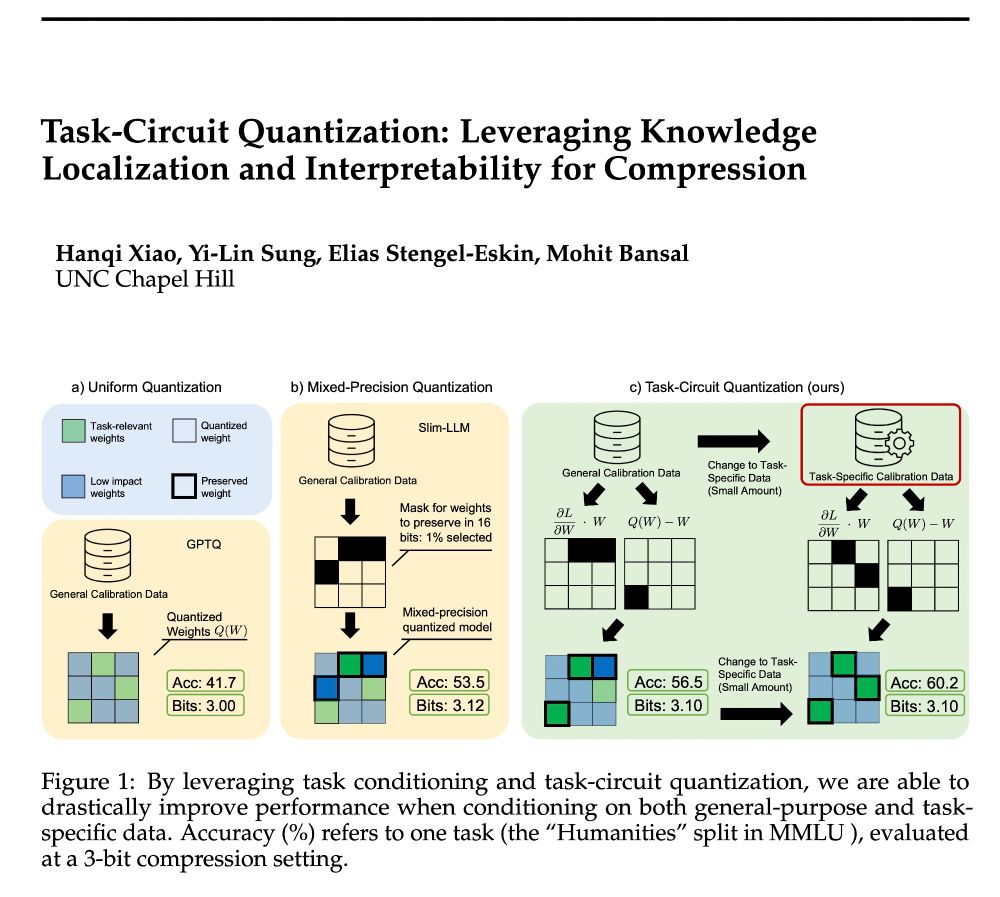
🚨Announcing TaCQ 🚨 a new mixed-precision quantization method that identifies critical weights to preserve. We integrate key ideas from circuit discovery, model editing, and input attribution to improve low-bit quant., w/ 96% 16-bit acc. at 3.1 avg bits (~6x compression)
📃 arxiv.org/abs/2504.07389
📃 arxiv.org/abs/2504.07389
April 12, 2025 at 2:19 PM
🚨Announcing TaCQ 🚨 a new mixed-precision quantization method that identifies critical weights to preserve. We integrate key ideas from circuit discovery, model editing, and input attribution to improve low-bit quant., w/ 96% 16-bit acc. at 3.1 avg bits (~6x compression)
📃 arxiv.org/abs/2504.07389
📃 arxiv.org/abs/2504.07389
Introducing VEGGIE 🥦—a unified, end-to-end, and versatile instructional video generative model.
VEGGIE supports 8 skills, from object addition/removal/changing, and stylization to concept grounding/reasoning. It exceeds SoTA and shows 0-shot multimodal instructional & in-context video editing.
VEGGIE supports 8 skills, from object addition/removal/changing, and stylization to concept grounding/reasoning. It exceeds SoTA and shows 0-shot multimodal instructional & in-context video editing.

March 19, 2025 at 6:56 PM
Introducing VEGGIE 🥦—a unified, end-to-end, and versatile instructional video generative model.
VEGGIE supports 8 skills, from object addition/removal/changing, and stylization to concept grounding/reasoning. It exceeds SoTA and shows 0-shot multimodal instructional & in-context video editing.
VEGGIE supports 8 skills, from object addition/removal/changing, and stylization to concept grounding/reasoning. It exceeds SoTA and shows 0-shot multimodal instructional & in-context video editing.
Reposted by Shoubin Yu

🎉 Congrats to the awesome students, postdocs, & collaborators for this exciting batch of #ICLR2025 and #NAACL2025 accepted papers (FYI some are on the academic/industry job market and a great catch 🙂), on diverse, important topics such as:
-- adaptive data generation environments/policies
...
🧵
-- adaptive data generation environments/policies
...
🧵

January 27, 2025 at 9:38 PM
🎉 Congrats to the awesome students, postdocs, & collaborators for this exciting batch of #ICLR2025 and #NAACL2025 accepted papers (FYI some are on the academic/industry job market and a great catch 🙂), on diverse, important topics such as:
-- adaptive data generation environments/policies
...
🧵
-- adaptive data generation environments/policies
...
🧵
Reposted by Shoubin Yu
🚨 We have postdoc openings at UNC 🙂
Exciting+diverse NLP/CV/ML topics**, freedom to create research agenda, competitive funding, very strong students, mentorship for grant writing, collabs w/ many faculty+universities+companies, superb quality of life/weather.
Please apply + help spread the word 🙏
Exciting+diverse NLP/CV/ML topics**, freedom to create research agenda, competitive funding, very strong students, mentorship for grant writing, collabs w/ many faculty+universities+companies, superb quality of life/weather.
Please apply + help spread the word 🙏

December 23, 2024 at 7:32 PM
🚨 We have postdoc openings at UNC 🙂
Exciting+diverse NLP/CV/ML topics**, freedom to create research agenda, competitive funding, very strong students, mentorship for grant writing, collabs w/ many faculty+universities+companies, superb quality of life/weather.
Please apply + help spread the word 🙏
Exciting+diverse NLP/CV/ML topics**, freedom to create research agenda, competitive funding, very strong students, mentorship for grant writing, collabs w/ many faculty+universities+companies, superb quality of life/weather.
Please apply + help spread the word 🙏
I was so lucky to work with Jaemin in my 1st year and learned a lot from him. I can confidently say he's not only a top mind in multimodal AI but also an incredible mentor&collaborator. He is insightful, hands-on, and genuinely knows how to guide and inspire junior students👇👏

🚨 I’m on the academic job market!
j-min.io
I work on ✨Multimodal AI✨, advancing reasoning in understanding & generation by:
1⃣ Making it scalable
2⃣ Making it faithful
3⃣ Evaluating + refining it
Completing my PhD at UNC (w/ @mohitbansal.bsky.social).
Happy to connect (will be at #NeurIPS2024)!
👇🧵
j-min.io
I work on ✨Multimodal AI✨, advancing reasoning in understanding & generation by:
1⃣ Making it scalable
2⃣ Making it faithful
3⃣ Evaluating + refining it
Completing my PhD at UNC (w/ @mohitbansal.bsky.social).
Happy to connect (will be at #NeurIPS2024)!
👇🧵

December 9, 2024 at 9:59 AM
I was so lucky to work with Jaemin in my 1st year and learned a lot from him. I can confidently say he's not only a top mind in multimodal AI but also an incredible mentor&collaborator. He is insightful, hands-on, and genuinely knows how to guide and inspire junior students👇👏
Reposted by Shoubin Yu
🚨 I am on the faculty job market this year 🚨
I will be presenting at #NeurIPS2024 and am happy to chat in-person or digitally!
I work on developing AI agents that can collaborate and communicate robustly with us and each other.
More at: esteng.github.io and in thread below
🧵👇
I will be presenting at #NeurIPS2024 and am happy to chat in-person or digitally!
I work on developing AI agents that can collaborate and communicate robustly with us and each other.
More at: esteng.github.io and in thread below
🧵👇

December 5, 2024 at 7:00 PM
🚨 I am on the faculty job market this year 🚨
I will be presenting at #NeurIPS2024 and am happy to chat in-person or digitally!
I work on developing AI agents that can collaborate and communicate robustly with us and each other.
More at: esteng.github.io and in thread below
🧵👇
I will be presenting at #NeurIPS2024 and am happy to chat in-person or digitally!
I work on developing AI agents that can collaborate and communicate robustly with us and each other.
More at: esteng.github.io and in thread below
🧵👇
Reposted by Shoubin Yu
Looking forward to giving this Distinguished Lecture at StonyBrook next week & meeting the several awesome NLP + CV folks there - thanks Niranjan + all for the kind invitation 🙂
PS. Excited to give a new talk on "Planning Agents for Collaborative Reasoning and Multimodal Generation" ➡️➡️
🧵👇
PS. Excited to give a new talk on "Planning Agents for Collaborative Reasoning and Multimodal Generation" ➡️➡️
🧵👇

Excited to host the wonderful @mohitbansal.bsky.social as part of Stony Brook CS Distinguished Lecture Series on Dec 6th. Looking forward to hearing about his team's fantastic work on Planning Agents for Collaborative Reasoning and Multimodal Generation. More here: tinyurl.com/jkmex3e9

December 3, 2024 at 4:07 PM
Looking forward to giving this Distinguished Lecture at StonyBrook next week & meeting the several awesome NLP + CV folks there - thanks Niranjan + all for the kind invitation 🙂
PS. Excited to give a new talk on "Planning Agents for Collaborative Reasoning and Multimodal Generation" ➡️➡️
🧵👇
PS. Excited to give a new talk on "Planning Agents for Collaborative Reasoning and Multimodal Generation" ➡️➡️
🧵👇
Reposted by Shoubin Yu

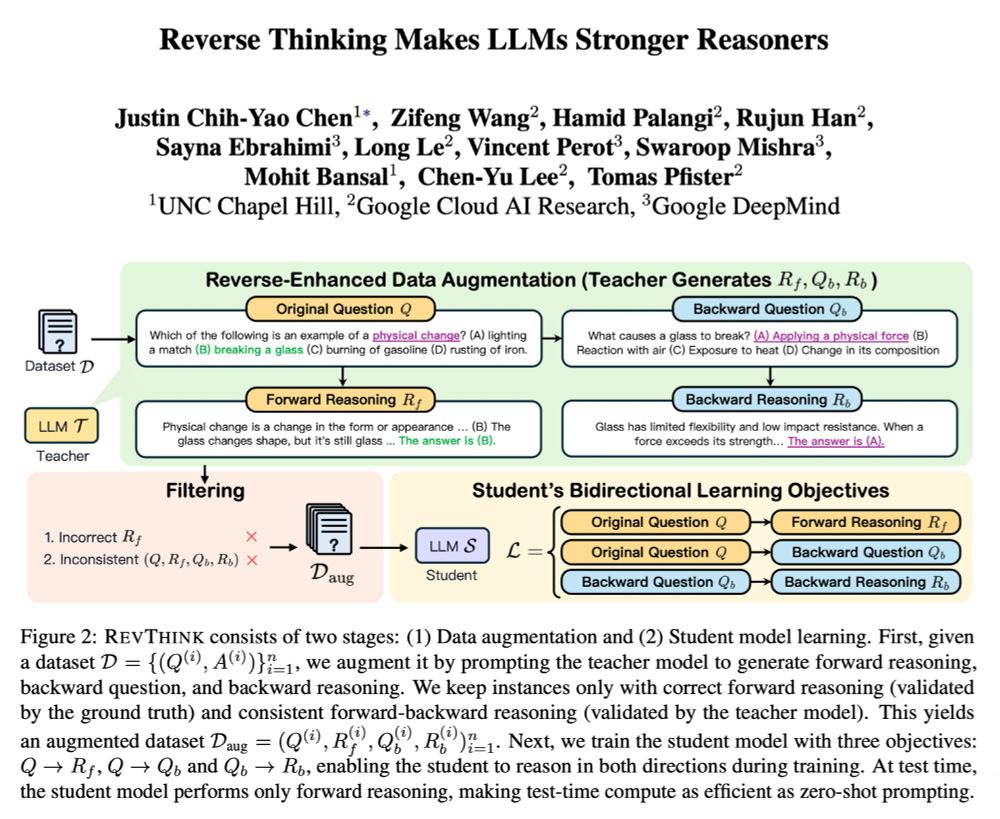
🚨 Reverse Thinking Makes LLMs Stronger Reasoners
We can often reason from a problem to a solution and also in reverse to enhance our overall reasoning. RevThink shows that LLMs can also benefit from reverse thinking 👉 13.53% gains + sample efficiency + strong generalization (on 4 OOD datasets)!
We can often reason from a problem to a solution and also in reverse to enhance our overall reasoning. RevThink shows that LLMs can also benefit from reverse thinking 👉 13.53% gains + sample efficiency + strong generalization (on 4 OOD datasets)!
December 2, 2024 at 7:29 PM
🚨 Reverse Thinking Makes LLMs Stronger Reasoners
We can often reason from a problem to a solution and also in reverse to enhance our overall reasoning. RevThink shows that LLMs can also benefit from reverse thinking 👉 13.53% gains + sample efficiency + strong generalization (on 4 OOD datasets)!
We can often reason from a problem to a solution and also in reverse to enhance our overall reasoning. RevThink shows that LLMs can also benefit from reverse thinking 👉 13.53% gains + sample efficiency + strong generalization (on 4 OOD datasets)!