



Somnath Basu Roy Chowdhury
@somnathbrc.bsky.social
𝐇𝐨𝐰 𝐜𝐚𝐧 𝐰𝐞 𝐩𝐞𝐫𝐟𝐞𝐜𝐭𝐥𝐲 𝐞𝐫𝐚𝐬𝐞 𝐜𝐨𝐧𝐜𝐞𝐩𝐭𝐬 𝐟𝐫𝐨𝐦 𝐋𝐋𝐌𝐬?
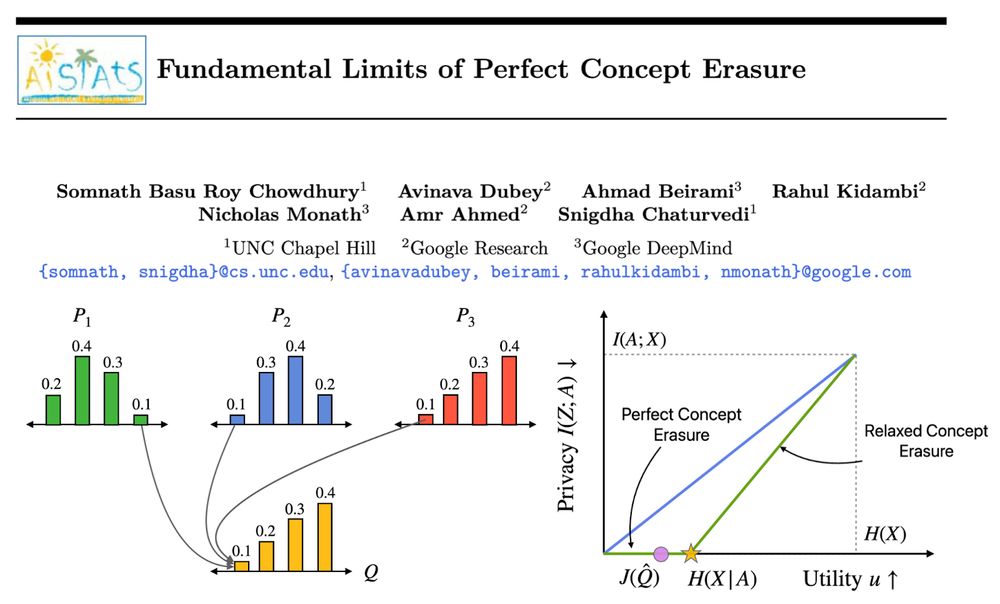
Our method, Perfect Erasure Functions (PEF), erases concepts perfectly from LLM representations. We analytically derive PEF w/o parameter estimation. PEFs achieve pareto optimal erasure-utility tradeoff backed w/ theoretical guarantees. #AISTATS2025 🧵
Our method, Perfect Erasure Functions (PEF), erases concepts perfectly from LLM representations. We analytically derive PEF w/o parameter estimation. PEFs achieve pareto optimal erasure-utility tradeoff backed w/ theoretical guarantees. #AISTATS2025 🧵
April 2, 2025 at 4:03 PM
𝐇𝐨𝐰 𝐜𝐚𝐧 𝐰𝐞 𝐩𝐞𝐫𝐟𝐞𝐜𝐭𝐥𝐲 𝐞𝐫𝐚𝐬𝐞 𝐜𝐨𝐧𝐜𝐞𝐩𝐭𝐬 𝐟𝐫𝐨𝐦 𝐋𝐋𝐌𝐬?
Our method, Perfect Erasure Functions (PEF), erases concepts perfectly from LLM representations. We analytically derive PEF w/o parameter estimation. PEFs achieve pareto optimal erasure-utility tradeoff backed w/ theoretical guarantees. #AISTATS2025 🧵
Our method, Perfect Erasure Functions (PEF), erases concepts perfectly from LLM representations. We analytically derive PEF w/o parameter estimation. PEFs achieve pareto optimal erasure-utility tradeoff backed w/ theoretical guarantees. #AISTATS2025 🧵
🚨I’m traveling to #NeurIPS2024 next week to present these papers.
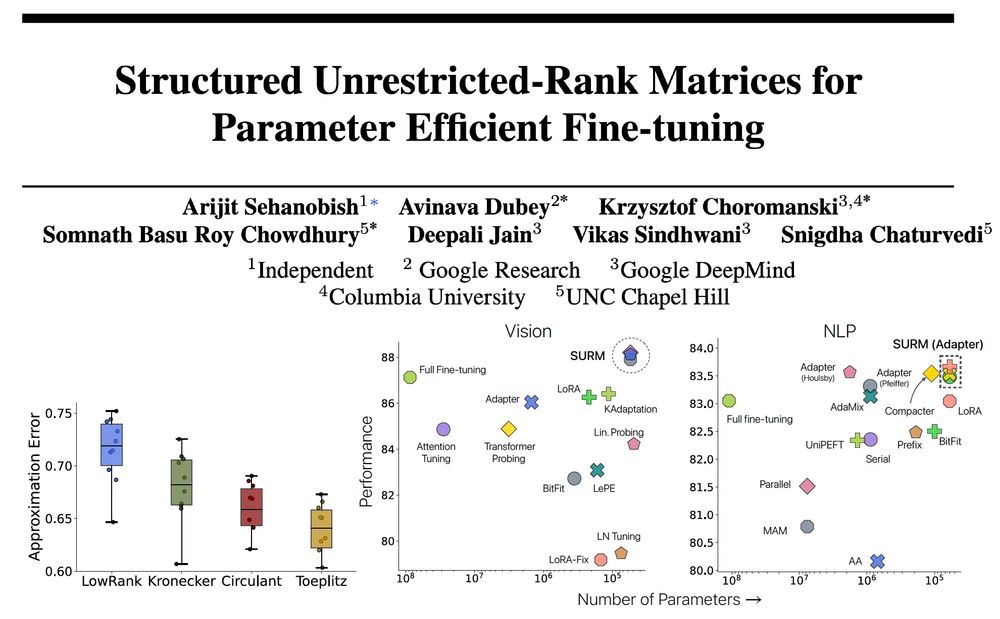
(1/3) 𝐒𝐭𝐫𝐮𝐜𝐭𝐮𝐫𝐞𝐝 𝐔𝐧𝐫𝐞𝐬𝐭𝐫𝐢𝐜𝐭𝐞𝐝-𝐑𝐚𝐧𝐤 𝐌𝐚𝐭𝐫𝐢𝐜𝐞𝐬 𝐟𝐨𝐫 𝐏𝐄𝐅𝐓
A new PEFT method replacing low-rank matrices (LoRA) with more expressive structured matrices
arxiv.org/abs/2406.17740
(1/3) 𝐒𝐭𝐫𝐮𝐜𝐭𝐮𝐫𝐞𝐝 𝐔𝐧𝐫𝐞𝐬𝐭𝐫𝐢𝐜𝐭𝐞𝐝-𝐑𝐚𝐧𝐤 𝐌𝐚𝐭𝐫𝐢𝐜𝐞𝐬 𝐟𝐨𝐫 𝐏𝐄𝐅𝐓
A new PEFT method replacing low-rank matrices (LoRA) with more expressive structured matrices
arxiv.org/abs/2406.17740
December 6, 2024 at 7:24 PM
🚨I’m traveling to #NeurIPS2024 next week to present these papers.
(1/3) 𝐒𝐭𝐫𝐮𝐜𝐭𝐮𝐫𝐞𝐝 𝐔𝐧𝐫𝐞𝐬𝐭𝐫𝐢𝐜𝐭𝐞𝐝-𝐑𝐚𝐧𝐤 𝐌𝐚𝐭𝐫𝐢𝐜𝐞𝐬 𝐟𝐨𝐫 𝐏𝐄𝐅𝐓
A new PEFT method replacing low-rank matrices (LoRA) with more expressive structured matrices
arxiv.org/abs/2406.17740
(1/3) 𝐒𝐭𝐫𝐮𝐜𝐭𝐮𝐫𝐞𝐝 𝐔𝐧𝐫𝐞𝐬𝐭𝐫𝐢𝐜𝐭𝐞𝐝-𝐑𝐚𝐧𝐤 𝐌𝐚𝐭𝐫𝐢𝐜𝐞𝐬 𝐟𝐨𝐫 𝐏𝐄𝐅𝐓
A new PEFT method replacing low-rank matrices (LoRA) with more expressive structured matrices
arxiv.org/abs/2406.17740