



Ksenia Se / Turing Post
@turingpost.bsky.social
Founder of the newsletter that explores AI & ML (https://www.turingpost.com)
- AI 101 series
- ML techniques
- AI Unicorns profiles
- Global dynamics
- ML History
- AI/ML Flashcards
Haven't decided yet which handle to maintain: this or @kseniase
- AI 101 series
- ML techniques
- AI Unicorns profiles
- Global dynamics
- ML History
- AI/ML Flashcards
Haven't decided yet which handle to maintain: this or @kseniase
Reading about scaling laws recently I came by the interesting point:
Focus on a balance between models' size and performance is more important that aiming for larger models
Tsinghua University and ModelBest Inc propose the idea of “capacity density” to measure how efficiently a model uses its size
Focus on a balance between models' size and performance is more important that aiming for larger models
Tsinghua University and ModelBest Inc propose the idea of “capacity density” to measure how efficiently a model uses its size
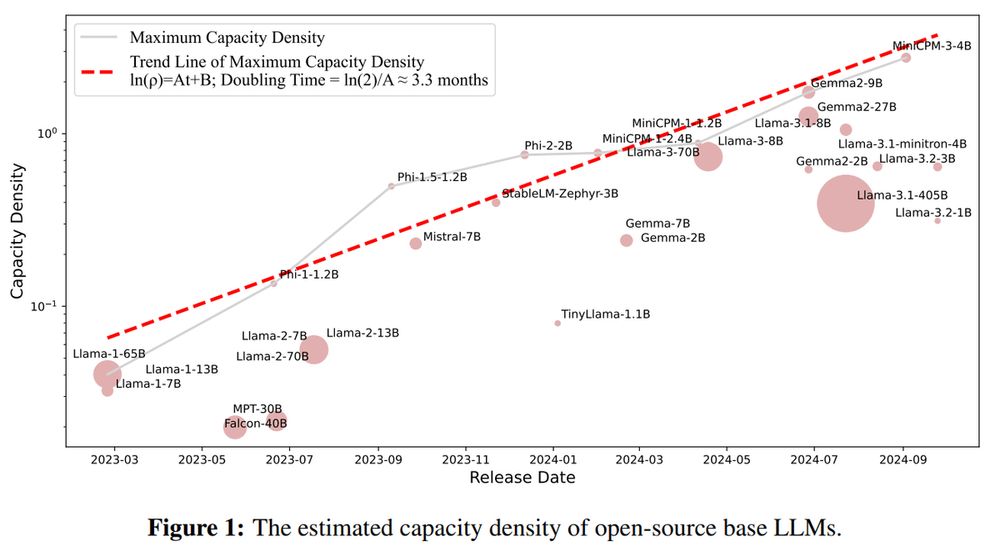
December 11, 2024 at 11:40 AM
Reading about scaling laws recently I came by the interesting point:
Focus on a balance between models' size and performance is more important that aiming for larger models
Tsinghua University and ModelBest Inc propose the idea of “capacity density” to measure how efficiently a model uses its size
Focus on a balance between models' size and performance is more important that aiming for larger models
Tsinghua University and ModelBest Inc propose the idea of “capacity density” to measure how efficiently a model uses its size
An incredible shift is happening in spatial intelligence!
Here are 2 latest revolutional World Models, which create interactive 3D environments:
1. GoogleDeepMind's Genie 2
2. AI system from World Labs, co-founded by Fei-Fei Li
Explore more below 👇
Here are 2 latest revolutional World Models, which create interactive 3D environments:
1. GoogleDeepMind's Genie 2
2. AI system from World Labs, co-founded by Fei-Fei Li
Explore more below 👇
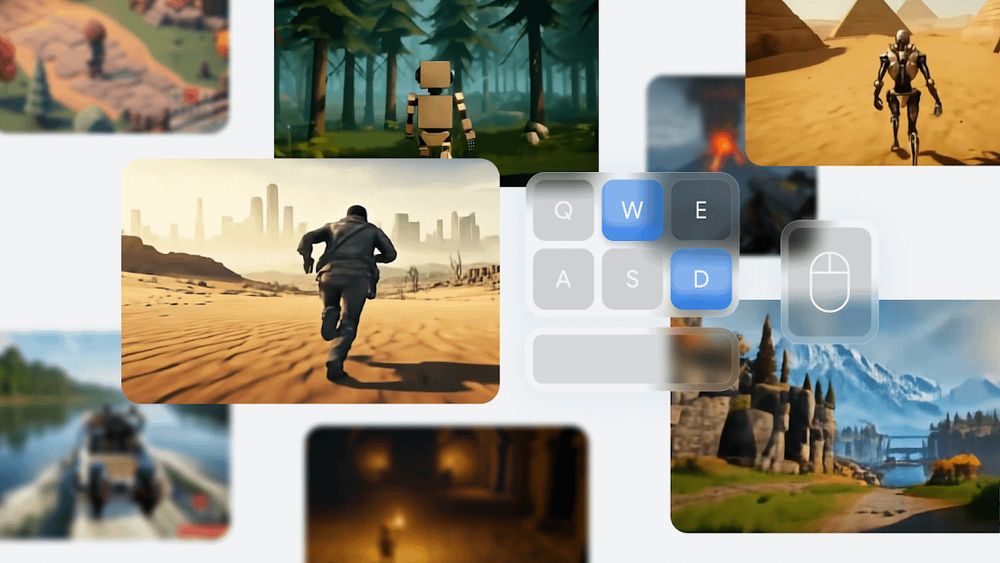
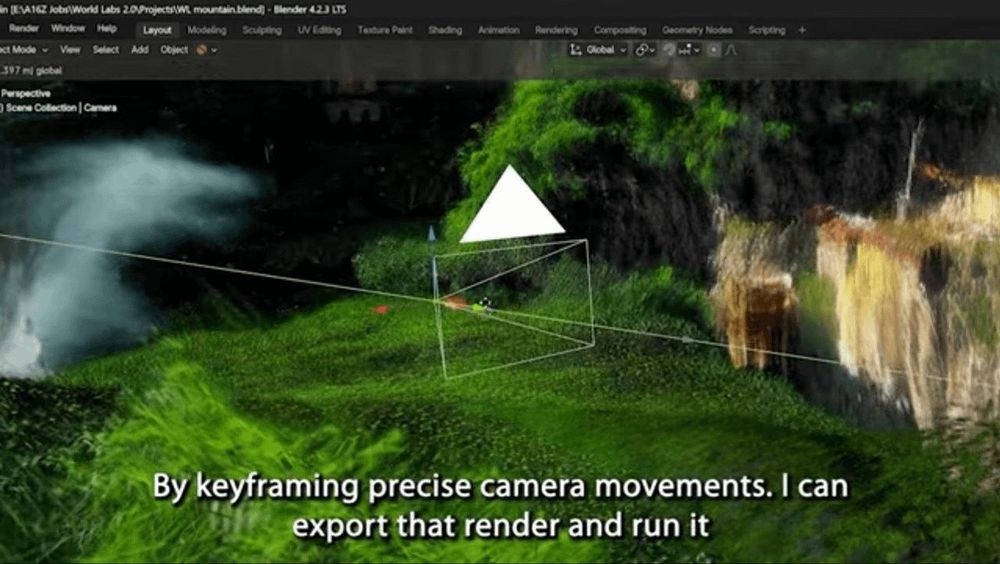
December 10, 2024 at 10:47 PM
An incredible shift is happening in spatial intelligence!
Here are 2 latest revolutional World Models, which create interactive 3D environments:
1. GoogleDeepMind's Genie 2
2. AI system from World Labs, co-founded by Fei-Fei Li
Explore more below 👇
Here are 2 latest revolutional World Models, which create interactive 3D environments:
1. GoogleDeepMind's Genie 2
2. AI system from World Labs, co-founded by Fei-Fei Li
Explore more below 👇
What is Flow Matching?
Flow Matching (FM) is used in top generative models, like Flux, F5-TTS, E2-TTS, and MovieGen with state-pf-the-art results. Some experts even say that FM might surpass diffusion models👇
Flow Matching (FM) is used in top generative models, like Flux, F5-TTS, E2-TTS, and MovieGen with state-pf-the-art results. Some experts even say that FM might surpass diffusion models👇
December 5, 2024 at 1:06 AM
What is Flow Matching?
Flow Matching (FM) is used in top generative models, like Flux, F5-TTS, E2-TTS, and MovieGen with state-pf-the-art results. Some experts even say that FM might surpass diffusion models👇
Flow Matching (FM) is used in top generative models, like Flux, F5-TTS, E2-TTS, and MovieGen with state-pf-the-art results. Some experts even say that FM might surpass diffusion models👇
Amazing models of the week:
• Alibaba’s QwQ-32B
• OLMo 2 by Allen AI
• ShowUI by Show Lab, NUS, Microsoft
• Adobe's MultiFoley
• INTELLECT-1 by Prime Intellect
🧵
• Alibaba’s QwQ-32B
• OLMo 2 by Allen AI
• ShowUI by Show Lab, NUS, Microsoft
• Adobe's MultiFoley
• INTELLECT-1 by Prime Intellect
🧵

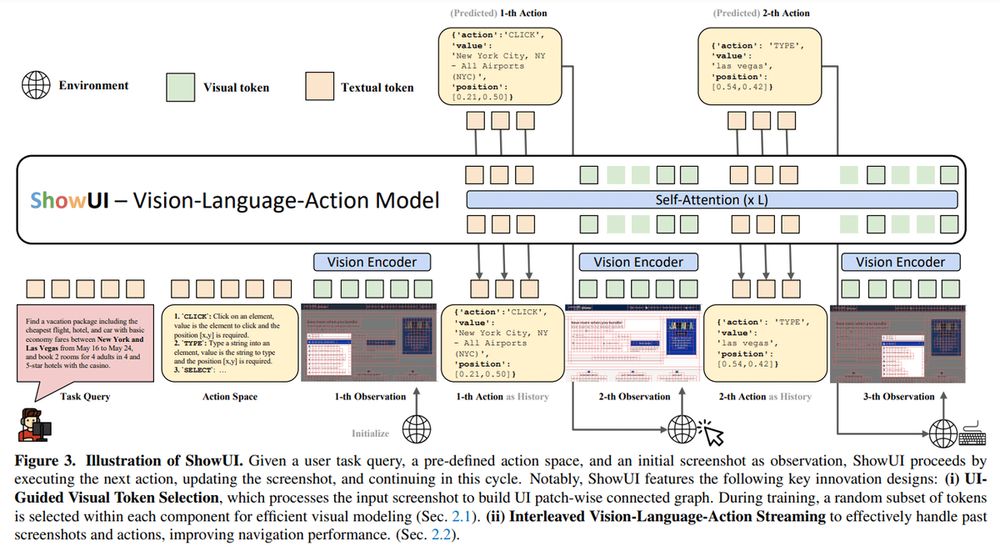
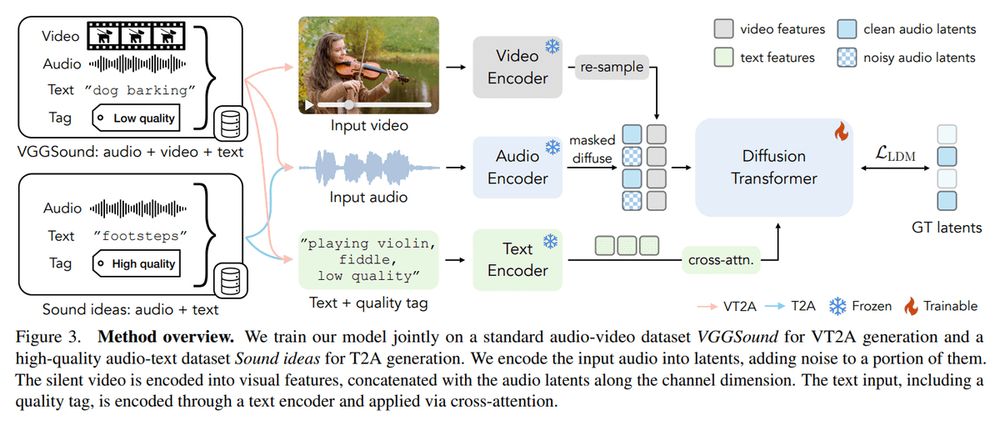
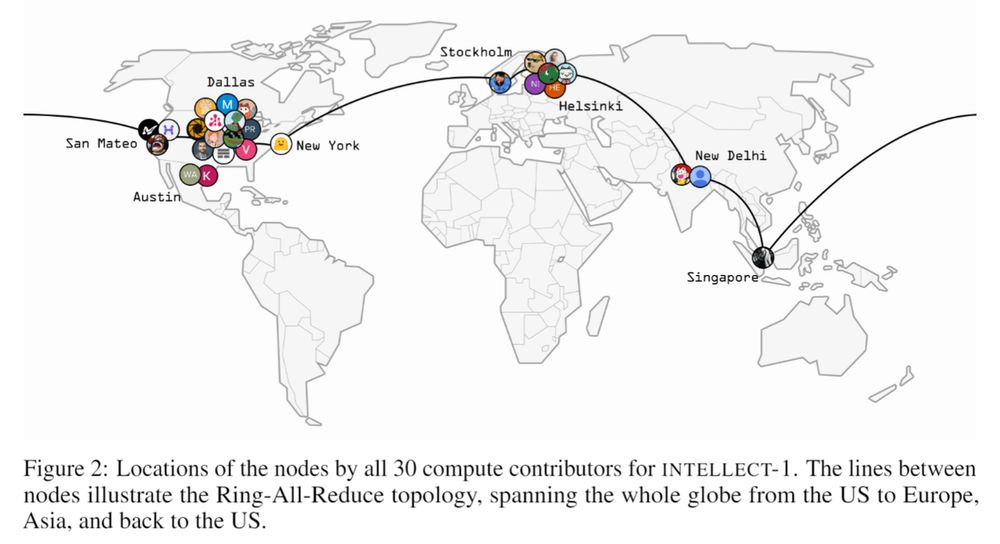
December 5, 2024 at 12:30 AM
Amazing models of the week:
• Alibaba’s QwQ-32B
• OLMo 2 by Allen AI
• ShowUI by Show Lab, NUS, Microsoft
• Adobe's MultiFoley
• INTELLECT-1 by Prime Intellect
🧵
• Alibaba’s QwQ-32B
• OLMo 2 by Allen AI
• ShowUI by Show Lab, NUS, Microsoft
• Adobe's MultiFoley
• INTELLECT-1 by Prime Intellect
🧵
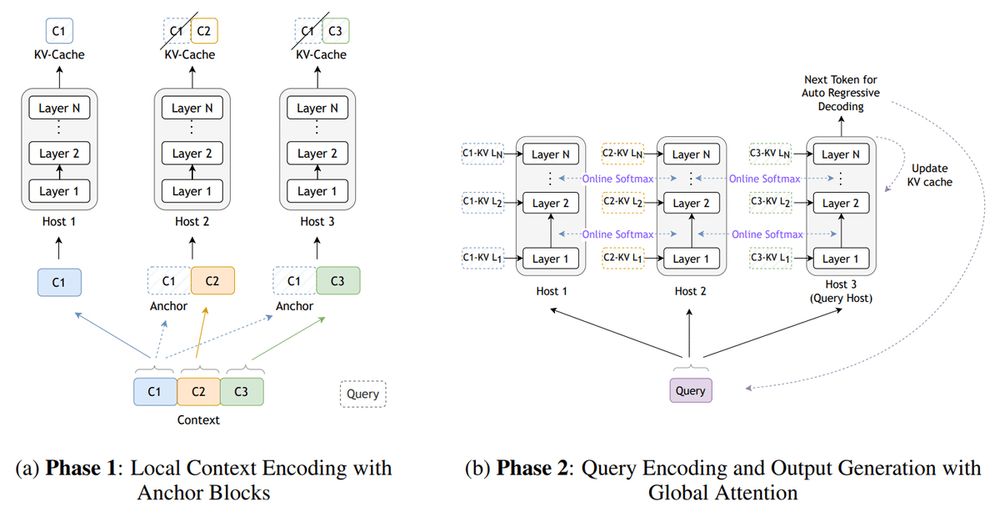
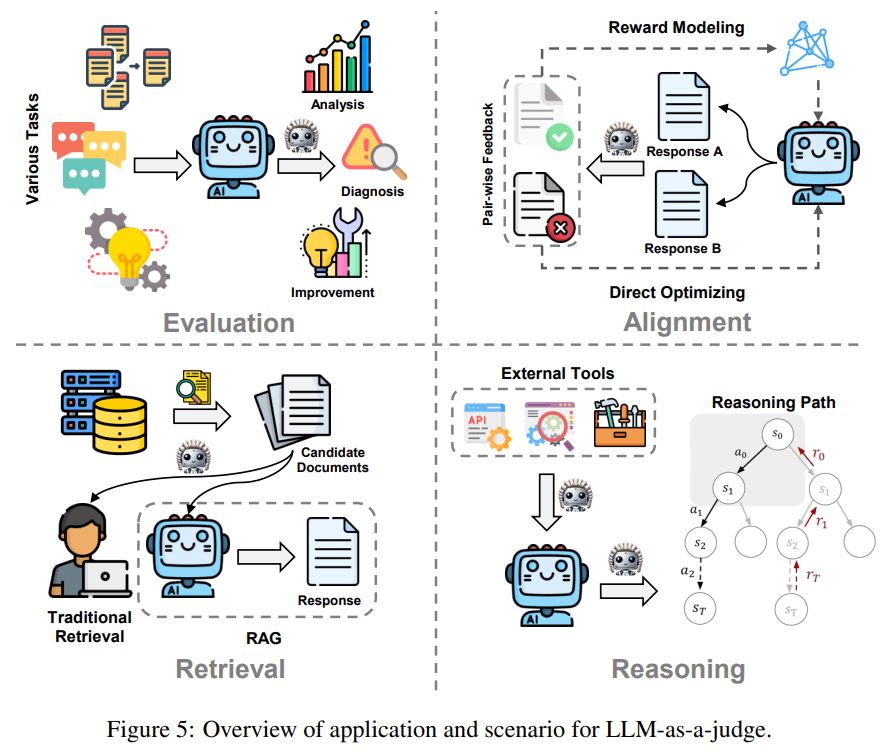
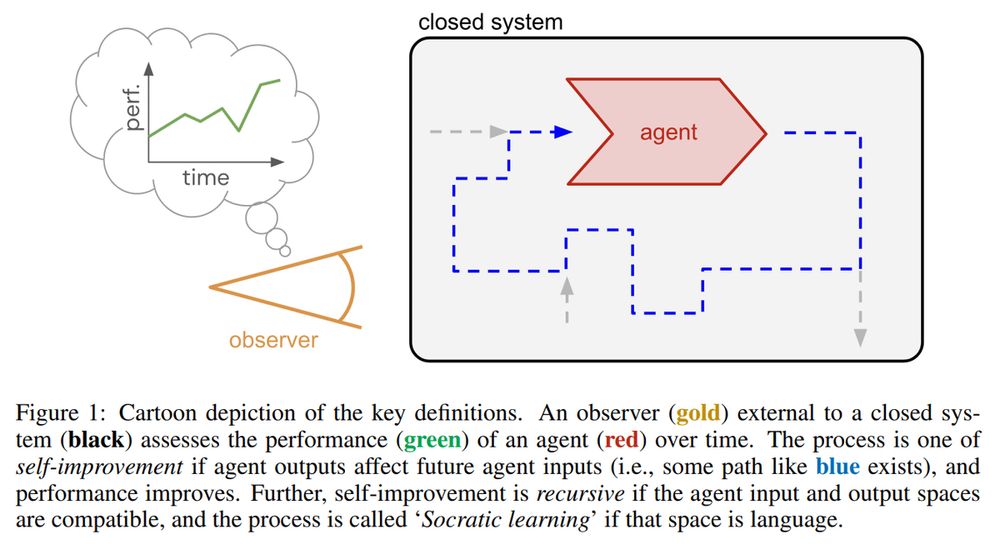
Top 5 researches of the week:
• Natural Language Reinforcement Learning
• Star Attention, NVIDIA
• Opportunities and Challenges of LLM-as-a-judge
• MH-MoE: Multi-Head Mixture-of-Experts, @msftresearch.bsky.social
• Boundless Socratic Learning with Language Games, Google DeepMind
🧵
• Natural Language Reinforcement Learning
• Star Attention, NVIDIA
• Opportunities and Challenges of LLM-as-a-judge
• MH-MoE: Multi-Head Mixture-of-Experts, @msftresearch.bsky.social
• Boundless Socratic Learning with Language Games, Google DeepMind
🧵
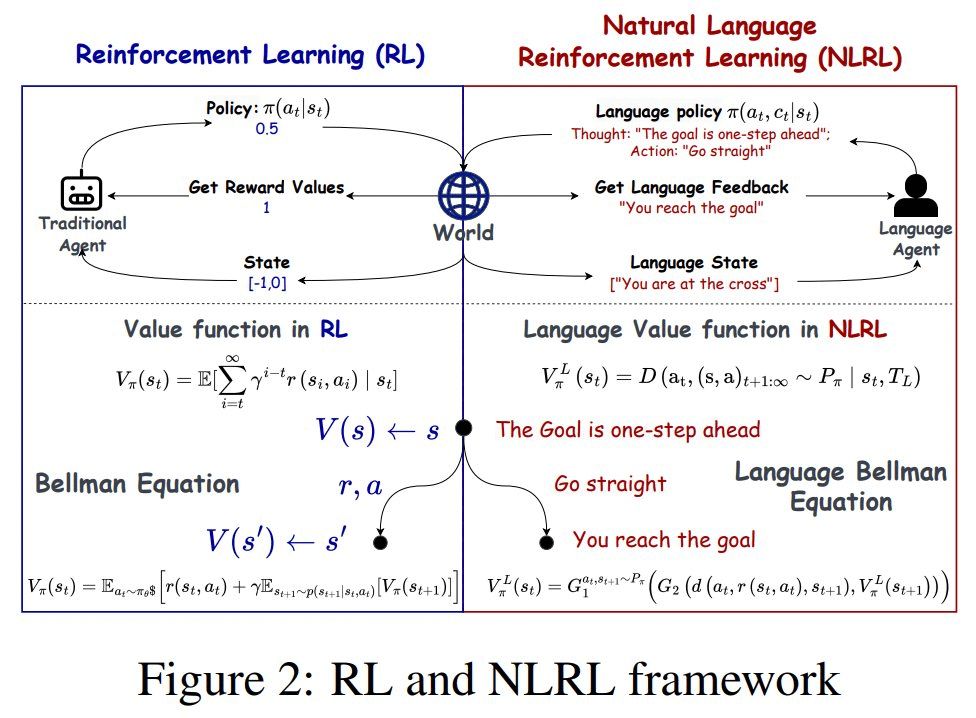
December 2, 2024 at 11:15 PM
Top 5 researches of the week:
• Natural Language Reinforcement Learning
• Star Attention, NVIDIA
• Opportunities and Challenges of LLM-as-a-judge
• MH-MoE: Multi-Head Mixture-of-Experts, @msftresearch.bsky.social
• Boundless Socratic Learning with Language Games, Google DeepMind
🧵
• Natural Language Reinforcement Learning
• Star Attention, NVIDIA
• Opportunities and Challenges of LLM-as-a-judge
• MH-MoE: Multi-Head Mixture-of-Experts, @msftresearch.bsky.social
• Boundless Socratic Learning with Language Games, Google DeepMind
🧵
LLM-brained GUI agents are a way to interact with GUIs in a much more flexible and human-like way.
They blend LLMs' capabilities with software interaction to work with websites, mobile apps, and desktop software, simplifying complex tasks.
A new survey on LLM-brained GUI agents was published👇
They blend LLMs' capabilities with software interaction to work with websites, mobile apps, and desktop software, simplifying complex tasks.
A new survey on LLM-brained GUI agents was published👇

December 2, 2024 at 12:15 PM
LLM-brained GUI agents are a way to interact with GUIs in a much more flexible and human-like way.
They blend LLMs' capabilities with software interaction to work with websites, mobile apps, and desktop software, simplifying complex tasks.
A new survey on LLM-brained GUI agents was published👇
They blend LLMs' capabilities with software interaction to work with websites, mobile apps, and desktop software, simplifying complex tasks.
A new survey on LLM-brained GUI agents was published👇
Top 10 GitHub Repositories to master ML, AI and Data Science:
• 100 Days of ML Code
• Data Science For Beginners
• Awesome Data Science
• Data Science Masters
• Homemade Machine Learning
• 500+ AI Projects List with Code
• Awesome Artificial Intelligence
...
Check out for more👇
• 100 Days of ML Code
• Data Science For Beginners
• Awesome Data Science
• Data Science Masters
• Homemade Machine Learning
• 500+ AI Projects List with Code
• Awesome Artificial Intelligence
...
Check out for more👇

December 1, 2024 at 6:55 PM
Top 10 GitHub Repositories to master ML, AI and Data Science:
• 100 Days of ML Code
• Data Science For Beginners
• Awesome Data Science
• Data Science Masters
• Homemade Machine Learning
• 500+ AI Projects List with Code
• Awesome Artificial Intelligence
...
Check out for more👇
• 100 Days of ML Code
• Data Science For Beginners
• Awesome Data Science
• Data Science Masters
• Homemade Machine Learning
• 500+ AI Projects List with Code
• Awesome Artificial Intelligence
...
Check out for more👇
This new approach to In-Context Learning (ICL) is very interesting:
The idea of HiAR-ICL (High-level Automated Reasoning in ICL) is to teaches the model abstract thinking patterns, using atomic reasoning actions and thought cards. It doesn't rely only on examples and prompts like in ICL
Details👇
The idea of HiAR-ICL (High-level Automated Reasoning in ICL) is to teaches the model abstract thinking patterns, using atomic reasoning actions and thought cards. It doesn't rely only on examples and prompts like in ICL
Details👇

November 30, 2024 at 11:52 PM
This new approach to In-Context Learning (ICL) is very interesting:
The idea of HiAR-ICL (High-level Automated Reasoning in ICL) is to teaches the model abstract thinking patterns, using atomic reasoning actions and thought cards. It doesn't rely only on examples and prompts like in ICL
Details👇
The idea of HiAR-ICL (High-level Automated Reasoning in ICL) is to teaches the model abstract thinking patterns, using atomic reasoning actions and thought cards. It doesn't rely only on examples and prompts like in ICL
Details👇
Baichuan Intelligence: A GenAI unicorn this Thanksgiving weekend!
Baichuan emphasizes slow thinking, long-term strategy, and practical innovation. Led by Wang Xiaochuan, it envisions a "symbiotic future" with math as its guide.
Explore Baichuan's unique path, strategy, and AI innovations:
Baichuan emphasizes slow thinking, long-term strategy, and practical innovation. Led by Wang Xiaochuan, it envisions a "symbiotic future" with math as its guide.
Explore Baichuan's unique path, strategy, and AI innovations:

Baichuan Intelligence: The AI Tiger Focused on Math and Healthcare
How Slower Thinking Could Lead to Bigger Results
www.turingpost.com
November 30, 2024 at 7:27 PM
Baichuan Intelligence: A GenAI unicorn this Thanksgiving weekend!
Baichuan emphasizes slow thinking, long-term strategy, and practical innovation. Led by Wang Xiaochuan, it envisions a "symbiotic future" with math as its guide.
Explore Baichuan's unique path, strategy, and AI innovations:
Baichuan emphasizes slow thinking, long-term strategy, and practical innovation. Led by Wang Xiaochuan, it envisions a "symbiotic future" with math as its guide.
Explore Baichuan's unique path, strategy, and AI innovations:
What is Self-Supervised Learning?
Whether you are a professional or a beginner in Machine Learning, we made our flashcards to be easy to digest and help everyone refresh key ML concepts.
Here's Self-Supervised Learning, a technique used to train ML models👇
Whether you are a professional or a beginner in Machine Learning, we made our flashcards to be easy to digest and help everyone refresh key ML concepts.
Here's Self-Supervised Learning, a technique used to train ML models👇


November 29, 2024 at 11:08 PM
What is Self-Supervised Learning?
Whether you are a professional or a beginner in Machine Learning, we made our flashcards to be easy to digest and help everyone refresh key ML concepts.
Here's Self-Supervised Learning, a technique used to train ML models👇
Whether you are a professional or a beginner in Machine Learning, we made our flashcards to be easy to digest and help everyone refresh key ML concepts.
Here's Self-Supervised Learning, a technique used to train ML models👇
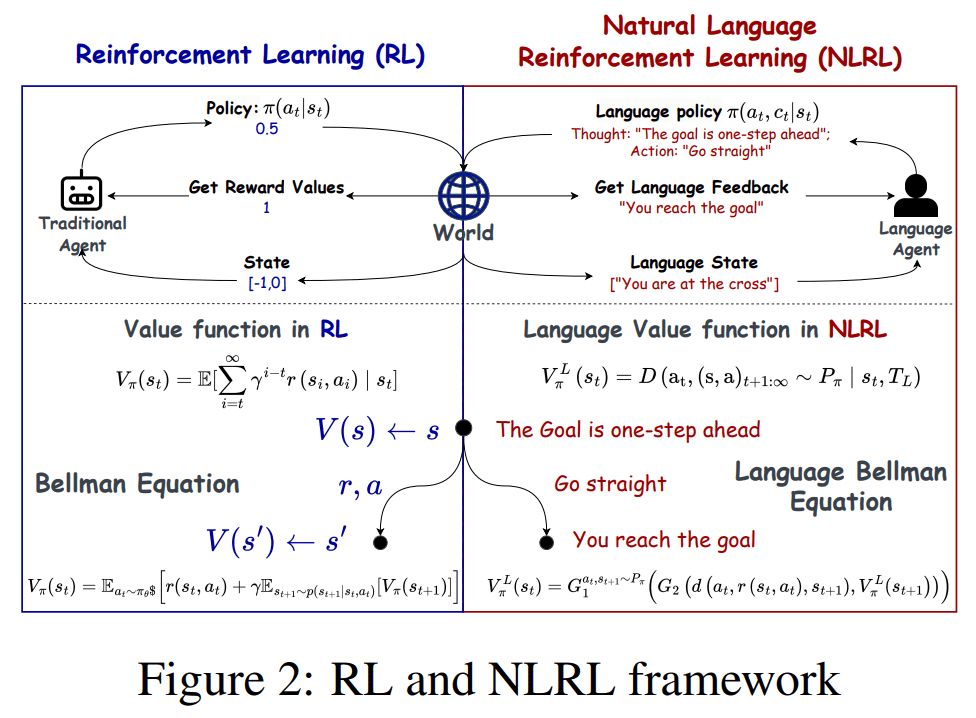
Natural Language Reinforcement Learning (NLRL) redefines Reinforcement Learning (RL).
NLRL's main idea:
The core parts of RL like goals, strategies, and evaluation methods are reimagined using natural language instead of rigid math.
Let's explore this approach more precisely🧵
NLRL's main idea:
The core parts of RL like goals, strategies, and evaluation methods are reimagined using natural language instead of rigid math.
Let's explore this approach more precisely🧵
November 29, 2024 at 3:06 PM
Natural Language Reinforcement Learning (NLRL) redefines Reinforcement Learning (RL).
NLRL's main idea:
The core parts of RL like goals, strategies, and evaluation methods are reimagined using natural language instead of rigid math.
Let's explore this approach more precisely🧵
NLRL's main idea:
The core parts of RL like goals, strategies, and evaluation methods are reimagined using natural language instead of rigid math.
Let's explore this approach more precisely🧵
A quick reminder of what AI agents are built of:
1. Profiling: Keeps the agent aligned with its purpose.
2. Knowledge: Provides domain-specific expertise.
Find other components below👇
P.S.: As an example, here's LangChain’s Harrison Chase's agent framework.
1. Profiling: Keeps the agent aligned with its purpose.
2. Knowledge: Provides domain-specific expertise.
Find other components below👇
P.S.: As an example, here's LangChain’s Harrison Chase's agent framework.

November 29, 2024 at 12:25 PM
A quick reminder of what AI agents are built of:
1. Profiling: Keeps the agent aligned with its purpose.
2. Knowledge: Provides domain-specific expertise.
Find other components below👇
P.S.: As an example, here's LangChain’s Harrison Chase's agent framework.
1. Profiling: Keeps the agent aligned with its purpose.
2. Knowledge: Provides domain-specific expertise.
Find other components below👇
P.S.: As an example, here's LangChain’s Harrison Chase's agent framework.
AI should be for everyone, right? :)
Here are 6 FREE AI courses for beginners:
• Introduction to Artificial Intelligence
• Artificial Intelligence for Beginners
• AI For Everyone
• Machine Learning for Beginners
• Introduction to Data Science Specialization
• Data Science for Beginners
Links👇
Here are 6 FREE AI courses for beginners:
• Introduction to Artificial Intelligence
• Artificial Intelligence for Beginners
• AI For Everyone
• Machine Learning for Beginners
• Introduction to Data Science Specialization
• Data Science for Beginners
Links👇


November 28, 2024 at 10:15 PM
AI should be for everyone, right? :)
Here are 6 FREE AI courses for beginners:
• Introduction to Artificial Intelligence
• Artificial Intelligence for Beginners
• AI For Everyone
• Machine Learning for Beginners
• Introduction to Data Science Specialization
• Data Science for Beginners
Links👇
Here are 6 FREE AI courses for beginners:
• Introduction to Artificial Intelligence
• Artificial Intelligence for Beginners
• AI For Everyone
• Machine Learning for Beginners
• Introduction to Data Science Specialization
• Data Science for Beginners
Links👇
Does LLaVA-o1 VLM challenge OpenAI's o1 model?
Here's what enhances LLaVA-o1's complex multimodal reasoning:
- Reasoning in 4 stages
- Effective inference-time scaling - Stage-level beam search
- Special dataset with step-by-step reasoning examples
👇
Here's what enhances LLaVA-o1's complex multimodal reasoning:
- Reasoning in 4 stages
- Effective inference-time scaling - Stage-level beam search
- Special dataset with step-by-step reasoning examples
👇


November 28, 2024 at 1:06 PM
Does LLaVA-o1 VLM challenge OpenAI's o1 model?
Here's what enhances LLaVA-o1's complex multimodal reasoning:
- Reasoning in 4 stages
- Effective inference-time scaling - Stage-level beam search
- Special dataset with step-by-step reasoning examples
👇
Here's what enhances LLaVA-o1's complex multimodal reasoning:
- Reasoning in 4 stages
- Effective inference-time scaling - Stage-level beam search
- Special dataset with step-by-step reasoning examples
👇
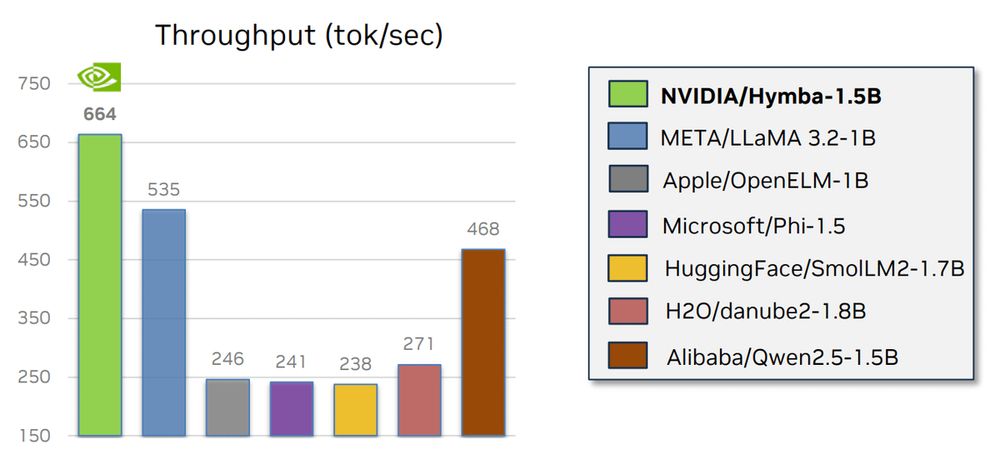
NVIDIA's Hymba small model is a great combo of 2 concepts:
- Transformer attention to help the model remember details.
- State Space Models (SSMs) to efficiently summarize context.
This model is also a treasure trove of interesting features.
Here are the details:
- Transformer attention to help the model remember details.
- State Space Models (SSMs) to efficiently summarize context.
This model is also a treasure trove of interesting features.
Here are the details:

November 28, 2024 at 12:38 AM
NVIDIA's Hymba small model is a great combo of 2 concepts:
- Transformer attention to help the model remember details.
- State Space Models (SSMs) to efficiently summarize context.
This model is also a treasure trove of interesting features.
Here are the details:
- Transformer attention to help the model remember details.
- State Space Models (SSMs) to efficiently summarize context.
This model is also a treasure trove of interesting features.
Here are the details:
The freshest AI/ML researches of the week
▪️ Multimodal Autoregressive Pre-training of Large Vision Encoders
▪️ Enhancing the Reasoning Ability of Multimodal Large Language Models via Mixed Preference Optimization
▪️ SAMURAI
▪️ Natural Language Reinforcement Learning
and 4 more!
🧵
▪️ Multimodal Autoregressive Pre-training of Large Vision Encoders
▪️ Enhancing the Reasoning Ability of Multimodal Large Language Models via Mixed Preference Optimization
▪️ SAMURAI
▪️ Natural Language Reinforcement Learning
and 4 more!
🧵

November 28, 2024 at 12:22 AM
The freshest AI/ML researches of the week
▪️ Multimodal Autoregressive Pre-training of Large Vision Encoders
▪️ Enhancing the Reasoning Ability of Multimodal Large Language Models via Mixed Preference Optimization
▪️ SAMURAI
▪️ Natural Language Reinforcement Learning
and 4 more!
🧵
▪️ Multimodal Autoregressive Pre-training of Large Vision Encoders
▪️ Enhancing the Reasoning Ability of Multimodal Large Language Models via Mixed Preference Optimization
▪️ SAMURAI
▪️ Natural Language Reinforcement Learning
and 4 more!
🧵
10 terms in Agentic Workflows everybody needs to know!
Has been working on Agentic Workflows Series recently. Here is my Glossary for you ;)
Agentic Workflows – Fancy term for letting AI handle your to-do list – with the constant fear that it creates its own.
Has been working on Agentic Workflows Series recently. Here is my Glossary for you ;)
Agentic Workflows – Fancy term for letting AI handle your to-do list – with the constant fear that it creates its own.
November 27, 2024 at 3:03 PM
10 terms in Agentic Workflows everybody needs to know!
Has been working on Agentic Workflows Series recently. Here is my Glossary for you ;)
Agentic Workflows – Fancy term for letting AI handle your to-do list – with the constant fear that it creates its own.
Has been working on Agentic Workflows Series recently. Here is my Glossary for you ;)
Agentic Workflows – Fancy term for letting AI handle your to-do list – with the constant fear that it creates its own.
The newest meaningful small models and research on embeddings:
• Hymba: NVIDIA’s hybrid-head architecture merges transformer attention with state space models (SSMs). It outperforms larger models like Llama-3.2-3B with less memory use and higher throughput.
🧵
• Hymba: NVIDIA’s hybrid-head architecture merges transformer attention with state space models (SSMs). It outperforms larger models like Llama-3.2-3B with less memory use and higher throughput.
🧵
November 27, 2024 at 12:26 AM
The newest meaningful small models and research on embeddings:
• Hymba: NVIDIA’s hybrid-head architecture merges transformer attention with state space models (SSMs). It outperforms larger models like Llama-3.2-3B with less memory use and higher throughput.
🧵
• Hymba: NVIDIA’s hybrid-head architecture merges transformer attention with state space models (SSMs). It outperforms larger models like Llama-3.2-3B with less memory use and higher throughput.
🧵
Let's start with top 5 researches of the week.
They are all about models:
• Tülu 3
• Marco-o1
• DeepSeek-R1-Lite
• Bi-Mamba
• Pixtral Large
🧵
They are all about models:
• Tülu 3
• Marco-o1
• DeepSeek-R1-Lite
• Bi-Mamba
• Pixtral Large
🧵



November 26, 2024 at 2:47 PM
Let's start with top 5 researches of the week.
They are all about models:
• Tülu 3
• Marco-o1
• DeepSeek-R1-Lite
• Bi-Mamba
• Pixtral Large
🧵
They are all about models:
• Tülu 3
• Marco-o1
• DeepSeek-R1-Lite
• Bi-Mamba
• Pixtral Large
🧵
Hello @bsky.app!
I'm sharing newsletters exploring AI & ML
- Weekly trends
- LLM/FM insights
- Unicorn spotlights
- Global dynamics
- History
Joins to get fresh news and interesting materials about AI! turingpost.com
I'm sharing newsletters exploring AI & ML
- Weekly trends
- LLM/FM insights
- Unicorn spotlights
- Global dynamics
- History
Joins to get fresh news and interesting materials about AI! turingpost.com

Turing Post
Saves you a lot of research time, plus gives a flashback to ML history and insights into the future. Stay ahead alongside over 73,000 professionals from top AI labs, ML startups, and enterprises
turingpost.com
November 26, 2024 at 2:36 PM
Hello @bsky.app!
I'm sharing newsletters exploring AI & ML
- Weekly trends
- LLM/FM insights
- Unicorn spotlights
- Global dynamics
- History
Joins to get fresh news and interesting materials about AI! turingpost.com
I'm sharing newsletters exploring AI & ML
- Weekly trends
- LLM/FM insights
- Unicorn spotlights
- Global dynamics
- History
Joins to get fresh news and interesting materials about AI! turingpost.com