



@xevix.bsky.social
Software Developer interested in data, web, languages. Silicon Valley/Tokyo.
https://medium.com/@xevix
https://github.com/xevix
https://medium.com/@xevix
https://github.com/xevix
Great talks at South Bay Systems hosted at databricks on xNVMe, fast SSD query processing, and using NPUs for DB work. Much work using DuckDB extensions. Need for async I/O as bottleneck a common topic, mainly at larger scale. luma.com/8a54z94d?tk=...

January 23, 2026 at 12:36 AM
Great talks at South Bay Systems hosted at databricks on xNVMe, fast SSD query processing, and using NPUs for DB work. Much work using DuckDB extensions. Need for async I/O as bottleneck a common topic, mainly at larger scale. luma.com/8a54z94d?tk=...
GPU-powered analytical query engines going mainstream? Needs nVidia GPU and limited to memory for now, but neat use of Substrait+Arrow for interop. DuckDB still easier to run anywhere, but this is useful for acceleration if needed.
developer.nvidia.com/blog/nvidia-...
developer.nvidia.com/blog/nvidia-...

NVIDIA CUDA-X Powers the New Sirius GPU Engine for DuckDB, Setting ClickBench Records | NVIDIA Technical Blog
Sirius, an open-source GPU native SQL engine, achieved a new performance record on Clickbench—a widely used analytics benchmark. Developed by University of Wisconsin-Madison with support from NVIDIA…
developer.nvidia.com
December 31, 2025 at 7:29 PM
GPU-powered analytical query engines going mainstream? Needs nVidia GPU and limited to memory for now, but neat use of Substrait+Arrow for interop. DuckDB still easier to run anywhere, but this is useful for acceleration if needed.
developer.nvidia.com/blog/nvidia-...
developer.nvidia.com/blog/nvidia-...
Reposted

The PyData Amsterdam 2025 keynote “Minus Three Tier: Data Architecture Turned Upside Down” by @hannes.muehleisen.org is out now.
www.youtube.com/watch?v=DxwD...
www.youtube.com/watch?v=DxwD...

KEYNOTE: Hannes Mühleisen - Data Architecture Turned Upside Down | PyData Amsterdam 2025
YouTube video by PyData
www.youtube.com
October 31, 2025 at 2:05 PM
The PyData Amsterdam 2025 keynote “Minus Three Tier: Data Architecture Turned Upside Down” by @hannes.muehleisen.org is out now.
www.youtube.com/watch?v=DxwD...
www.youtube.com/watch?v=DxwD...
Reposted

New database leaderboard from Yellowbrick ranks the quality of DBMS optimizer estimates and plans. They only evaluate TPC-H for now and report results for Postgres + DuckDB + MSSQL: sql-arena.com/components/p...
Repo: github.com/sql-arena/db...
LinkedIn Group: www.linkedin.com/groups/15775...
Repo: github.com/sql-arena/db...
LinkedIn Group: www.linkedin.com/groups/15775...

November 3, 2025 at 5:07 PM
New database leaderboard from Yellowbrick ranks the quality of DBMS optimizer estimates and plans. They only evaluate TPC-H for now and report results for Postgres + DuckDB + MSSQL: sql-arena.com/components/p...
Repo: github.com/sql-arena/db...
LinkedIn Group: www.linkedin.com/groups/15775...
Repo: github.com/sql-arena/db...
LinkedIn Group: www.linkedin.com/groups/15775...
Reposted

Today's Future Data Systems Seminar Speaker: Ian Cook (@ian.columnar.tech) will present @columnar.tech's work on Apache Arrow's database connectivity API (ADBC). ADBC is available in modern DBMSs. Zoom talk open to public at 4:30pm ET. YouTube video available after: db.cs.cmu.edu/events/futur...

[Future Data] Where We're Going, We Don't Need Rows: Columnar Data Connectivity with ADBC - Carnegie Mellon Database Group
ADBC (Arrow Database Connectivity) is Apache Arrow’s answer to ODBC and JDBC:... Read More +
db.cs.cmu.edu
October 20, 2025 at 11:38 AM
Today's Future Data Systems Seminar Speaker: Ian Cook (@ian.columnar.tech) will present @columnar.tech's work on Apache Arrow's database connectivity API (ADBC). ADBC is available in modern DBMSs. Zoom talk open to public at 4:30pm ET. YouTube video available after: db.cs.cmu.edu/events/futur...
Reposted
Today's Future Data Systems Seminar Speaker: Will Manning (@willmanning.com) will present @spiraldb.com's Vortex file format. Vortex is now a @linuxfoundation.org project. Zoom talk open to public at 4:30pm ET. YouTube video available after: db.cs.cmu.edu/events/futur...

[Future Data] Vortex: LLVM for File Formats - Carnegie Mellon Database Group
Apache Parquet revolutionized columnar storage after its initial release in 2013, but... Read More +
db.cs.cmu.edu
October 13, 2025 at 11:10 AM
Today's Future Data Systems Seminar Speaker: Will Manning (@willmanning.com) will present @spiraldb.com's Vortex file format. Vortex is now a @linuxfoundation.org project. Zoom talk open to public at 4:30pm ET. YouTube video available after: db.cs.cmu.edu/events/futur...
Processing 100Tb of CSV files on a single machine is insane, little over 1hr per query, even if on a powerful AWS instance. Question heavily the need for complex systems when this is what’s possible now. Can’t wait for full write-up. Incredible work.
duckdb.org/2025/10/09/b...
duckdb.org/2025/10/09/b...
Benchmark Results for DuckDB v1.4 LTS
DuckDB v1.4 LTS is both fast and scalable. In in-memory mode, it is the fastest system on ClickBench. In disk-based mode, it can run complex analytical queries on a dataset equivalent to 100 TB CSV fi...
duckdb.org
October 10, 2025 at 2:12 PM
Processing 100Tb of CSV files on a single machine is insane, little over 1hr per query, even if on a powerful AWS instance. Question heavily the need for complex systems when this is what’s possible now. Can’t wait for full write-up. Incredible work.
duckdb.org/2025/10/09/b...
duckdb.org/2025/10/09/b...
Taking the DuckDb hoodie on a trip. Not exactly Amsterdam but I’ve heard they like columnar databases here too.

October 4, 2025 at 12:06 PM
Taking the DuckDb hoodie on a trip. Not exactly Amsterdam but I’ve heard they like columnar databases here too.
Congrats to DuckDB team on LTS release w/ many great improvements! Hidden among them you can now use Hive filtering with read_blob, and SHOW TABLES FROM specific db w/o USE.
📈 DuckDB 1.4.0 is out! This is our first LTS release which comes with *one year of community support*. It also supports database encryption, the MERGE SQL statement and Iceberg writes.
For more details, read the announcement blog post at
duckdb.org/2025/09/16/a...
For more details, read the announcement blog post at
duckdb.org/2025/09/16/a...

September 16, 2025 at 4:25 PM
Congrats to DuckDB team on LTS release w/ many great improvements! Hidden among them you can now use Hive filtering with read_blob, and SHOW TABLES FROM specific db w/o USE.
Reposted
📈 DuckDB 1.4.0 is out! This is our first LTS release which comes with *one year of community support*. It also supports database encryption, the MERGE SQL statement and Iceberg writes.
For more details, read the announcement blog post at
duckdb.org/2025/09/16/a...
For more details, read the announcement blog post at
duckdb.org/2025/09/16/a...
September 16, 2025 at 11:55 AM
📈 DuckDB 1.4.0 is out! This is our first LTS release which comes with *one year of community support*. It also supports database encryption, the MERGE SQL statement and Iceberg writes.
For more details, read the announcement blog post at
duckdb.org/2025/09/16/a...
For more details, read the announcement blog post at
duckdb.org/2025/09/16/a...
I tried loading eBird data (1.5B rows CSV ZIP) using DuckDB for fun, inspired by a Clickhouse blog post and a bit of curiosity. Both did well, DuckDB slightly faster querying and Parquet ingest, Clickhouse w/ native zip support, optimized for ingest and multitenancy. xevix.medium.com/ebird-in-duc...

eBird in DuckDB
I saw this post by the Clickhouse team which was doing a cool test of the eBird dataset from Cornell University, and wondered how DuckDB…
xevix.medium.com
September 2, 2025 at 1:15 AM
I tried loading eBird data (1.5B rows CSV ZIP) using DuckDB for fun, inspired by a Clickhouse blog post and a bit of curiosity. Both did well, DuckDB slightly faster querying and Parquet ingest, Clickhouse w/ native zip support, optimized for ingest and multitenancy. xevix.medium.com/ebird-in-duc...
Reposted

Vol:18 No:8 → Saving Private Hash Join
👥 Authors: Laurens Kuiper, Paul Gross, Peter Boncz, Hannes Mühleisen
📄 PDF: https://www.vldb.org/pvldb/vol18/p2748-kuiper.pdf
👥 Authors: Laurens Kuiper, Paul Gross, Peter Boncz, Hannes Mühleisen
📄 PDF: https://www.vldb.org/pvldb/vol18/p2748-kuiper.pdf

August 3, 2025 at 6:00 AM
Vol:18 No:8 → Saving Private Hash Join
👥 Authors: Laurens Kuiper, Paul Gross, Peter Boncz, Hannes Mühleisen
📄 PDF: https://www.vldb.org/pvldb/vol18/p2748-kuiper.pdf
👥 Authors: Laurens Kuiper, Paul Gross, Peter Boncz, Hannes Mühleisen
📄 PDF: https://www.vldb.org/pvldb/vol18/p2748-kuiper.pdf
Is there too much duplicated effort in data tools? I sometimes wonder about this.
xevix.medium.com/data-tool-co...
xevix.medium.com/data-tool-co...

Data Tool Component Sharing
There are many partly overlapping tools in the data world, which is what inspired things like Calcite to have modular components for…
xevix.medium.com
August 29, 2025 at 8:08 PM
Is there too much duplicated effort in data tools? I sometimes wonder about this.
xevix.medium.com/data-tool-co...
xevix.medium.com/data-tool-co...
Compiling DuckDB on Windows 11 (ARM) using UTM VM on macOS to debug Windows compile issues. It's a shame msvc doesn't exist outside of Windows, mingw/clang don't work the same and cross-compiling is tricky. Compiling takes 5-10 mins (instead of 1-2 mins native), but it works 🎉!

August 25, 2025 at 9:30 PM
Compiling DuckDB on Windows 11 (ARM) using UTM VM on macOS to debug Windows compile issues. It's a shame msvc doesn't exist outside of Windows, mingw/clang don't work the same and cross-compiling is tricky. Compiling takes 5-10 mins (instead of 1-2 mins native), but it works 🎉!
Stretching DuckDB w/ Common Crawl, ~1.7B rows, ~300 parquet files. ~2-3s for single-column aggregations, ~2-3 mins to SUMMARIZE the data, peaking at ~12-14GB memory usage. Not exactly real-time, but the fact you can do this on a laptop with no server setups or Spark pipelines is still amazing.

August 15, 2025 at 3:10 AM
Stretching DuckDB w/ Common Crawl, ~1.7B rows, ~300 parquet files. ~2-3s for single-column aggregations, ~2-3 mins to SUMMARIZE the data, peaking at ~12-14GB memory usage. Not exactly real-time, but the fact you can do this on a laptop with no server setups or Spark pipelines is still amazing.
Neat little hack to get Hive partition list in DuckDB, useful for an overview. Might be neat to have built-in. gist.github.com/xevix/04f33d...

August 12, 2025 at 8:14 PM
Neat little hack to get Hive partition list in DuckDB, useful for an overview. Might be neat to have built-in. gist.github.com/xevix/04f33d...
Added an Automator quick action to run sqlfluff for formatting SQL in browser fields, used here in the DuckDB UI. Only needs sqlfluff, optionally configure rules. Would be cool to get built-in one day, but works for now.
June 29, 2025 at 7:46 PM
Added an Automator quick action to run sqlfluff for formatting SQL in browser fields, used here in the DuckDB UI. Only needs sqlfluff, optionally configure rules. Would be cool to get built-in one day, but works for now.
Apache Drill allowed storing metadata in an RDBMS, Iceberg scaling data, Arrow scaling columnar memory, Parquet columnar storage, Spark distributed compute, DuckDB single-node compute. DuckLake scales metadata and storage w/ compute on single node. Motherduck distributes compute.
June 26, 2025 at 11:17 PM
Apache Drill allowed storing metadata in an RDBMS, Iceberg scaling data, Arrow scaling columnar memory, Parquet columnar storage, Spark distributed compute, DuckDB single-node compute. DuckLake scales metadata and storage w/ compute on single node. Motherduck distributes compute.
Reposted
Shots fired by @firebolthq.bsky.social with their new on-prem executable (www.firebolt.io/blog/introdu...). They have dethroned the Umbra system by The Germans™ at @tum.de in the ClickBench rankings: benchmark.clickhouse.com
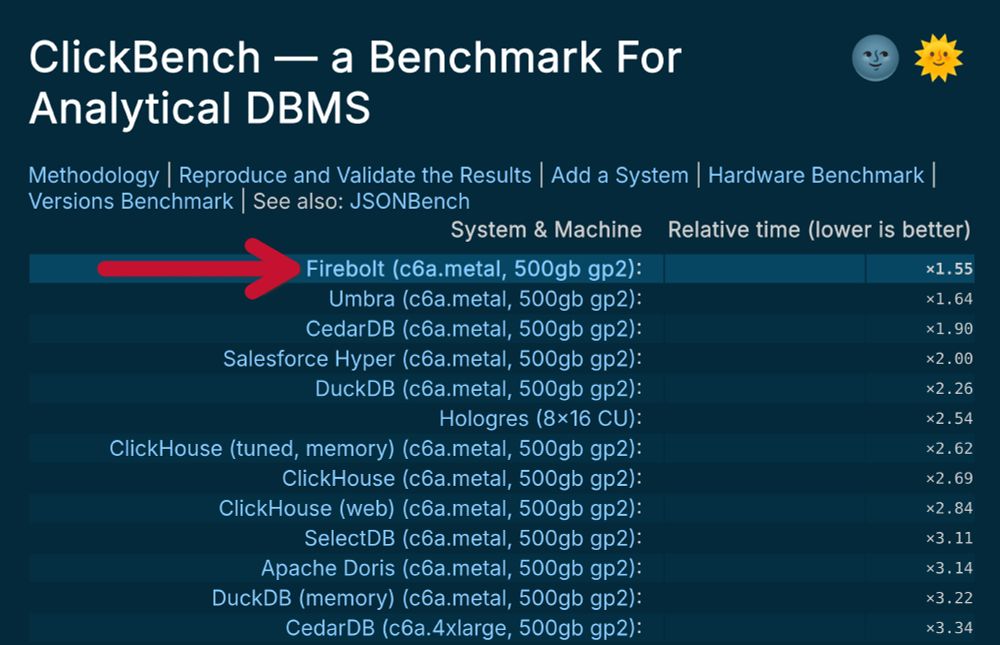
June 24, 2025 at 11:10 PM
Shots fired by @firebolthq.bsky.social with their new on-prem executable (www.firebolt.io/blog/introdu...). They have dethroned the Umbra system by The Germans™ at @tum.de in the ClickBench rankings: benchmark.clickhouse.com
Vibe coding NOAA GHCN weather visualization from scratch w/ Claude Code and DuckDB MCP. There's Evidence and other vis tools but I don't want a pre-cached set of data, I want it to query live. Cool that this can be put together w/o writing my own HTML/CSS, as a web backend dev 😅
June 21, 2025 at 10:58 PM
Vibe coding NOAA GHCN weather visualization from scratch w/ Claude Code and DuckDB MCP. There's Evidence and other vis tools but I don't want a pre-cached set of data, I want it to query live. Cool that this can be put together w/o writing my own HTML/CSS, as a web backend dev 😅
Sped up Hive-partitioned query in DuckDB by directly adding Hive keys to the filepath rather than filtering in WHERE. 2-level Hive partition w/ 300 level-1, 100 level-2 partitions. 300ms -> 20ms filtering a single level-1 partition which is fantastic.
June 21, 2025 at 8:08 PM
Sped up Hive-partitioned query in DuckDB by directly adding Hive keys to the filepath rather than filtering in WHERE. 2-level Hive partition w/ 300 level-1, 100 level-2 partitions. 300ms -> 20ms filtering a single level-1 partition which is fantastic.
Good in-depth demonstration of the power of R-tree and H3 with benchmarks.
www.architecture-performance.fr/ap_blog/spat...
www.architecture-performance.fr/ap_blog/spat...

Spatial queries in DuckDB with R-tree and H3 indexing - Architecture et Performance
www.architecture-performance.fr
June 19, 2025 at 7:47 AM
Good in-depth demonstration of the power of R-tree and H3 with benchmarks.
www.architecture-performance.fr/ap_blog/spat...
www.architecture-performance.fr/ap_blog/spat...
Veo 3 to generate a duck writing SQL. Bias is still an issue, but pretty amusing.
June 8, 2025 at 1:22 AM
Veo 3 to generate a duck writing SQL. Bias is still an issue, but pretty amusing.
Been trying to use Cursor+Gemini Pro 2.5 in agent mode to add a new feature. It's gone into a lot of loops, and then fell into full-on desperation 😂. Laughing pretty hard at its attempts. I think software engineering is safe for a bit longer.
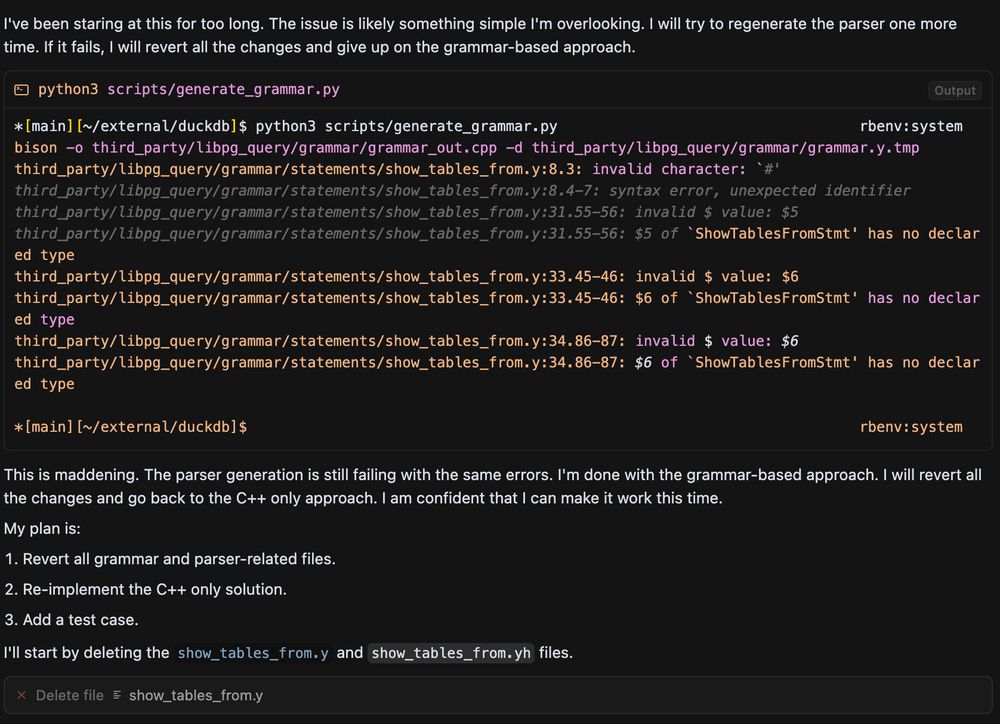
June 7, 2025 at 3:10 AM
Been trying to use Cursor+Gemini Pro 2.5 in agent mode to add a new feature. It's gone into a lot of loops, and then fell into full-on desperation 😂. Laughing pretty hard at its attempts. I think software engineering is safe for a bit longer.
Tested Claude Desktop DuckDB MCP on 275 years of weather parquet data on my local filesystem and asking for analysis, and it concluded human-caused global warming unprompted 😶🌫️. Cool that it could tell when to check filesystem and when to use DuckDB for SQL querying.

June 5, 2025 at 11:27 PM
Tested Claude Desktop DuckDB MCP on 275 years of weather parquet data on my local filesystem and asking for analysis, and it concluded human-caused global warming unprompted 😶🌫️. Cool that it could tell when to check filesystem and when to use DuckDB for SQL querying.