
Posts
Media
Videos
Starter Packs

yuluqin.bsky.social
@yuluqin.bsky.social
· Jul 22

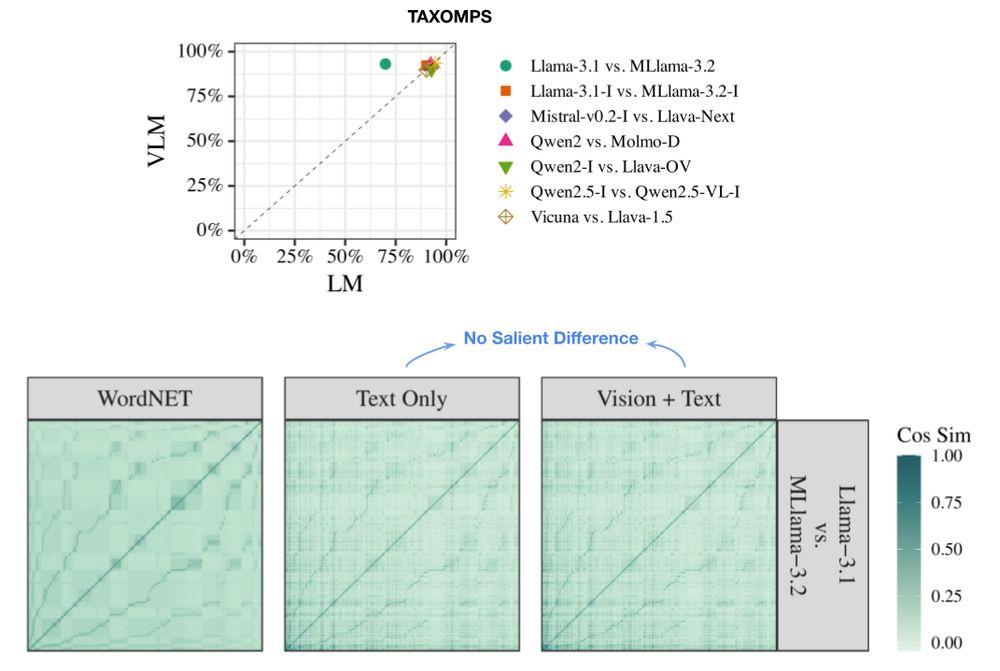
Vision-and-Language Training Helps Deploy Taxonomic Knowledge but Does Not Fundamentally Alter It
Does vision-and-language (VL) training change the linguistic representations of language models in meaningful ways? Most results in the literature have shown inconsistent or marginal differences, both...
www.arxiv.org



yuluqin.bsky.social
@yuluqin.bsky.social
· Jul 22



yuluqin.bsky.social
@yuluqin.bsky.social
· Jul 22