
Aditi Mavalankar
@aditimavalankar.bsky.social
1K followers
120 following
14 posts
Research Scientist at DeepMind working on Gemini Thinking
Posts
Media
Videos
Starter Packs
Reposted by Aditi Mavalankar




Reposted by Aditi Mavalankar

Abhinav Moudgil
@amoudgl.bsky.social
· Jun 15
Reposted by Aditi Mavalankar

Reposted by Aditi Mavalankar
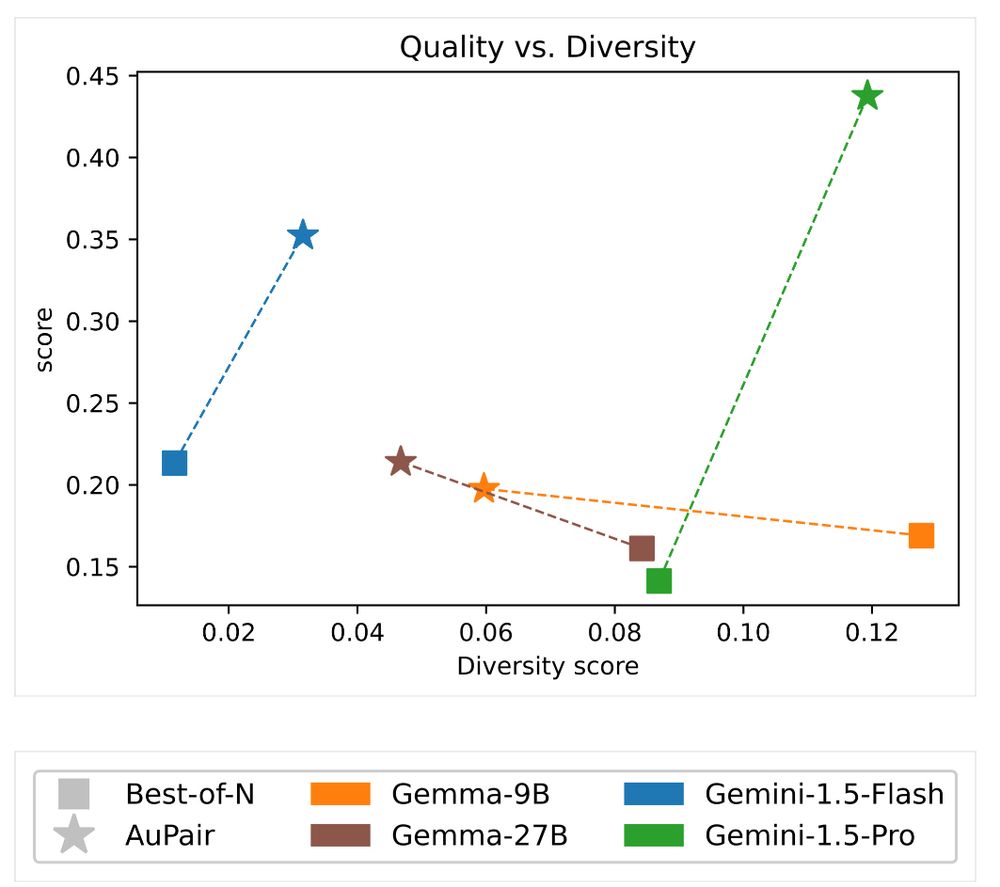
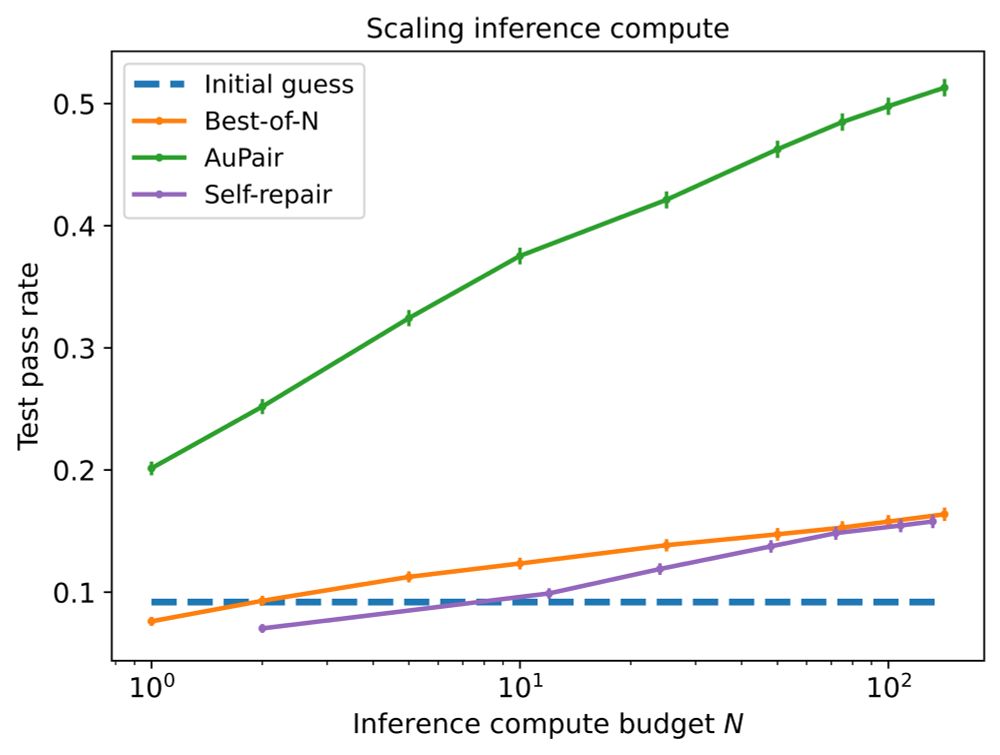
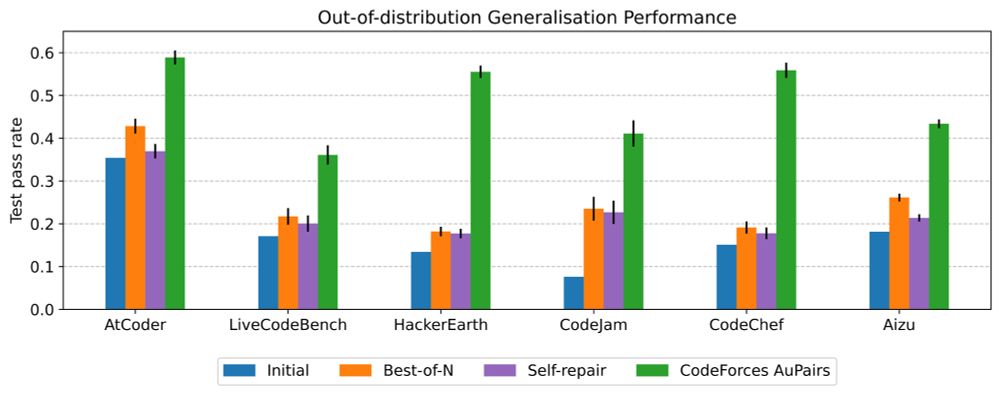
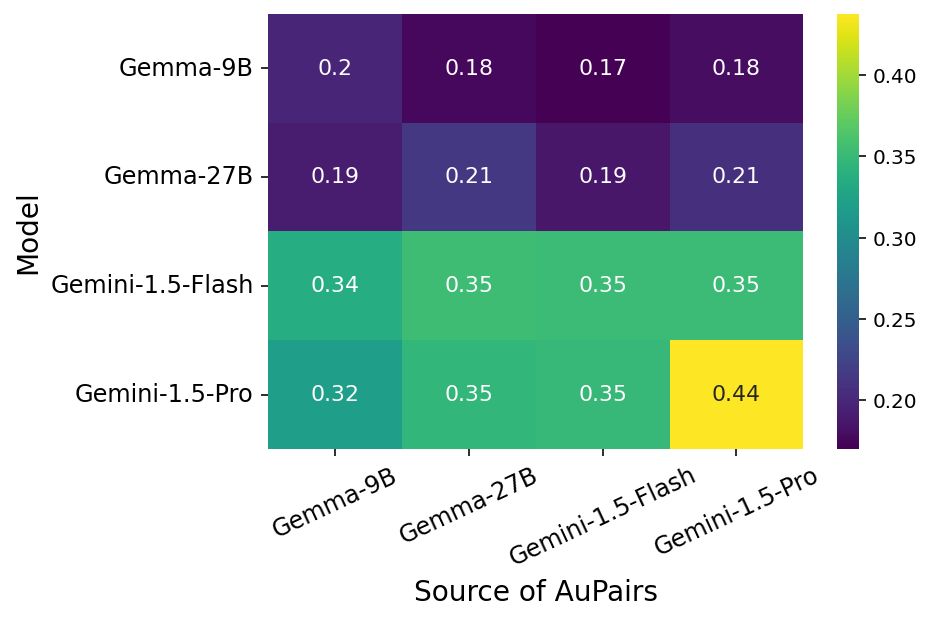
Reposted by Aditi Mavalankar
Tom Schaul
@schaul.bsky.social
· Nov 28

Boundless Socratic Learning with Language Games
An agent trained within a closed system can master any desired capability, as long as the following three conditions hold: (a) it receives sufficiently informative and aligned feedback, (b) its covera...
arxiv.org