




Aditya Arun
@adityaarun1.bsky.social
Reposted by Aditya Arun

"The Principles of Diffusion Models" by Chieh-Hsin Lai, Yang Song, Dongjun Kim, Yuki Mitsufuji, Stefano Ermon. arxiv.org/abs/2510.21890
It might not be the easiest intro to diffusion models, but this monograph is an amazing deep dive into the math behind them and all the nuances
It might not be the easiest intro to diffusion models, but this monograph is an amazing deep dive into the math behind them and all the nuances

The Principles of Diffusion Models
This monograph presents the core principles that have guided the development of diffusion models, tracing their origins and showing how diverse formulations arise from shared mathematical ideas. Diffu...
arxiv.org
October 28, 2025 at 8:35 AM
"The Principles of Diffusion Models" by Chieh-Hsin Lai, Yang Song, Dongjun Kim, Yuki Mitsufuji, Stefano Ermon. arxiv.org/abs/2510.21890
It might not be the easiest intro to diffusion models, but this monograph is an amazing deep dive into the math behind them and all the nuances
It might not be the easiest intro to diffusion models, but this monograph is an amazing deep dive into the math behind them and all the nuances
Reposted by Aditya Arun

Made some notes on the new DeepMind paper "Video models are zero-shot learners and reasoners" - it makes a convincing case that generative video models are to vision problems what LLMs were to NLP problems: single models that can solve a wide array of challenges simonwillison.net/2025/Sep/27/...

Video models are zero-shot learners and reasoners
Fascinating new paper from Google DeepMind which makes a very convincing case that their Veo 3 model - and generative video models in general - serve a similar role in …
simonwillison.net
September 28, 2025 at 12:29 AM
Made some notes on the new DeepMind paper "Video models are zero-shot learners and reasoners" - it makes a convincing case that generative video models are to vision problems what LLMs were to NLP problems: single models that can solve a wide array of challenges simonwillison.net/2025/Sep/27/...
Reposted by Aditya Arun

As AI agents face increasingly long and complex tasks, decomposing them into subtasks becomes increasingly appealing.
But how do we discover such temporal structure?
Hierarchical RL provides a natural formalism-yet many questions remain open.
Here's our overview of the field🧵
But how do we discover such temporal structure?
Hierarchical RL provides a natural formalism-yet many questions remain open.
Here's our overview of the field🧵
June 27, 2025 at 8:16 PM
As AI agents face increasingly long and complex tasks, decomposing them into subtasks becomes increasingly appealing.
But how do we discover such temporal structure?
Hierarchical RL provides a natural formalism-yet many questions remain open.
Here's our overview of the field🧵
But how do we discover such temporal structure?
Hierarchical RL provides a natural formalism-yet many questions remain open.
Here's our overview of the field🧵
Reposted by Aditya Arun

What is the probability of an image? What do the highest and lowest probability images look like? Do natural images lie on a low-dimensional manifold?
In a new preprint with Zahra Kadkhodaie and @eerosim.bsky.social, we develop a novel energy-based model in order to answer these questions: 🧵
In a new preprint with Zahra Kadkhodaie and @eerosim.bsky.social, we develop a novel energy-based model in order to answer these questions: 🧵

June 6, 2025 at 10:11 PM
What is the probability of an image? What do the highest and lowest probability images look like? Do natural images lie on a low-dimensional manifold?
In a new preprint with Zahra Kadkhodaie and @eerosim.bsky.social, we develop a novel energy-based model in order to answer these questions: 🧵
In a new preprint with Zahra Kadkhodaie and @eerosim.bsky.social, we develop a novel energy-based model in order to answer these questions: 🧵
Reposted by Aditya Arun



May 23, 2025 at 3:33 PM
Reposted by Aditya Arun

I have cleaned a bit my lecture notes on Optimal Transport for Machine Learners arxiv.org/abs/2505.06589

Optimal Transport for Machine Learners
Optimal Transport is a foundational mathematical theory that connects optimization, partial differential equations, and probability. It offers a powerful framework for comparing probability distributi...
arxiv.org
May 13, 2025 at 5:18 AM
I have cleaned a bit my lecture notes on Optimal Transport for Machine Learners arxiv.org/abs/2505.06589
Happy to be recognized among outstanding reviewers 🙂

Behind every great conference is a team of dedicated reviewers. Congratulations to this year’s #CVPR2025 Outstanding Reviewers!
cvpr.thecvf.com/Conferences/...
cvpr.thecvf.com/Conferences/...
May 10, 2025 at 3:16 PM
Happy to be recognized among outstanding reviewers 🙂
Reposted by Aditya Arun
Enjoying reading this. Clarifies some nice connections between scoring rules, probabilistic divergences, convex analysis, and so on. Should read it even more closely, to be honest!

May 1, 2025 at 10:22 PM
Enjoying reading this. Clarifies some nice connections between scoring rules, probabilistic divergences, convex analysis, and so on. Should read it even more closely, to be honest!
Reposted by Aditya Arun

Nice tutorial arxiv.org/abs/2503.21673

March 29, 2025 at 6:26 PM
Nice tutorial arxiv.org/abs/2503.21673
Reposted by Aditya Arun
"Inductive Moment Matching" by Linqi Zhou et al. I like the use of multiple particles to apply a loss similar to consistency models, but on distributions. Training is stable and gives high-quality generated images in very few sampling steps
📄 arxiv.org/abs/2503.07565
🌍 lumalabs.ai/news/inducti...
📄 arxiv.org/abs/2503.07565
🌍 lumalabs.ai/news/inducti...
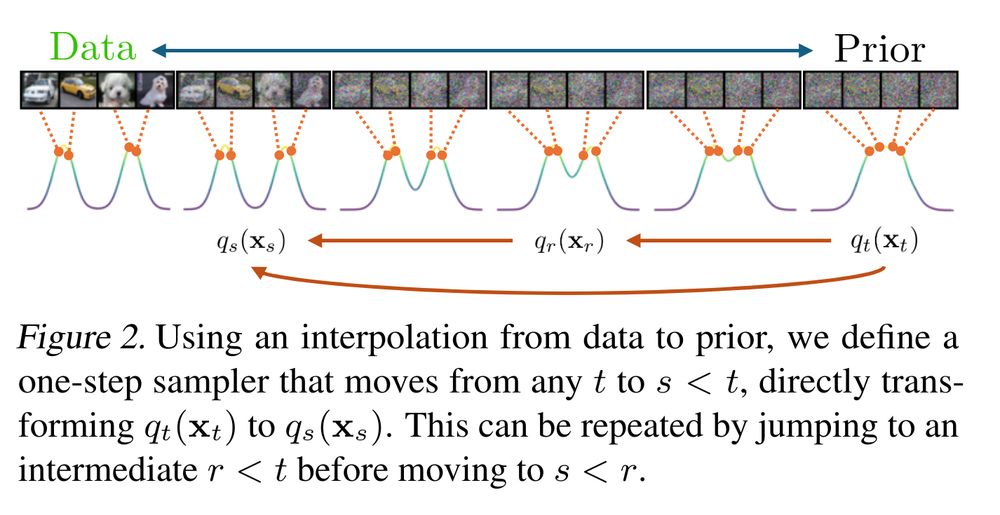
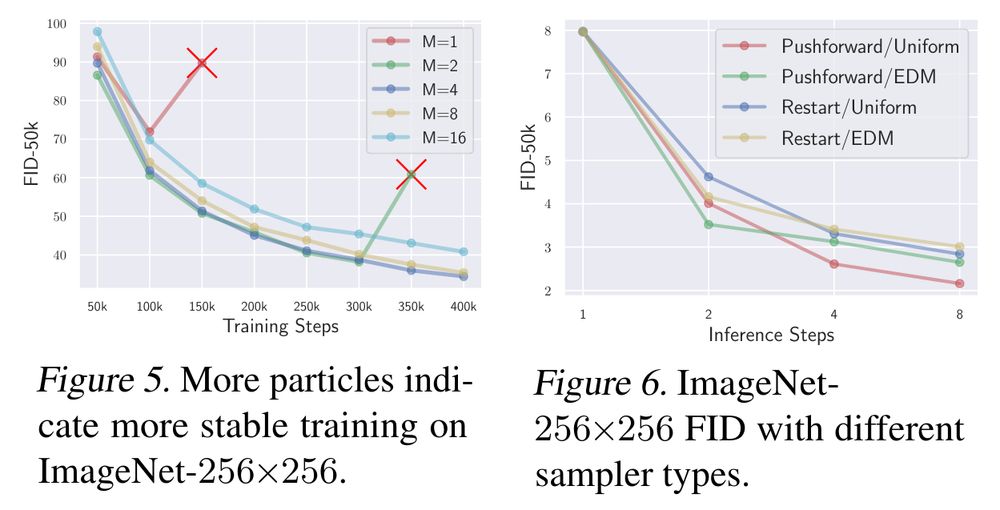

March 13, 2025 at 3:05 PM
"Inductive Moment Matching" by Linqi Zhou et al. I like the use of multiple particles to apply a loss similar to consistency models, but on distributions. Training is stable and gives high-quality generated images in very few sampling steps
📄 arxiv.org/abs/2503.07565
🌍 lumalabs.ai/news/inducti...
📄 arxiv.org/abs/2503.07565
🌍 lumalabs.ai/news/inducti...
Reposted by Aditya Arun

Smashing the endorse button as fast as I can
www.lesswrong.com/posts/oKAFFv...
www.lesswrong.com/posts/oKAFFv...

A Bear Case: My Predictions Regarding AI Progress — LessWrong
This isn't really a "timeline", as such – I don't know the timings – but this is my current, fairly optimistic take on where we're heading. …
www.lesswrong.com
March 9, 2025 at 9:09 PM
Smashing the endorse button as fast as I can
www.lesswrong.com/posts/oKAFFv...
www.lesswrong.com/posts/oKAFFv...
Reposted by Aditya Arun
Yet another short paper on randomness predictors (of which conformal predictors are a subclass) by Vovk, focusing on an inductive variant. arxiv.org/abs/2503.02803

March 6, 2025 at 6:01 AM
Yet another short paper on randomness predictors (of which conformal predictors are a subclass) by Vovk, focusing on an inductive variant. arxiv.org/abs/2503.02803
Reposted by Aditya Arun

I already advertised for this document when I posted it on arXiv, and later when it was published.
This week, with the agreement of the publisher, I uploaded the published version on arXiv.
Less typos, more references and additional sections including PAC-Bayes Bernstein.
arxiv.org/abs/2110.11216
This week, with the agreement of the publisher, I uploaded the published version on arXiv.
Less typos, more references and additional sections including PAC-Bayes Bernstein.
arxiv.org/abs/2110.11216

March 5, 2025 at 1:16 AM
I already advertised for this document when I posted it on arXiv, and later when it was published.
This week, with the agreement of the publisher, I uploaded the published version on arXiv.
Less typos, more references and additional sections including PAC-Bayes Bernstein.
arxiv.org/abs/2110.11216
This week, with the agreement of the publisher, I uploaded the published version on arXiv.
Less typos, more references and additional sections including PAC-Bayes Bernstein.
arxiv.org/abs/2110.11216
Reposted by Aditya Arun

1/n🚀If you’re working on generative image modeling, check out our latest work! We introduce EQ-VAE, a simple yet powerful regularization approach that makes latent representations equivariant to spatial transformations, leading to smoother latents and better generative models.👇

February 18, 2025 at 2:27 PM
1/n🚀If you’re working on generative image modeling, check out our latest work! We introduce EQ-VAE, a simple yet powerful regularization approach that makes latent representations equivariant to spatial transformations, leading to smoother latents and better generative models.👇
Reposted by Aditya Arun
Slides for a general introduction to the use of Optimal Transport methods in learning, with an emphasis on diffusion models, flow matching, training 2 layers neural networks and deep transformers. speakerdeck.com/gpeyre/optim...
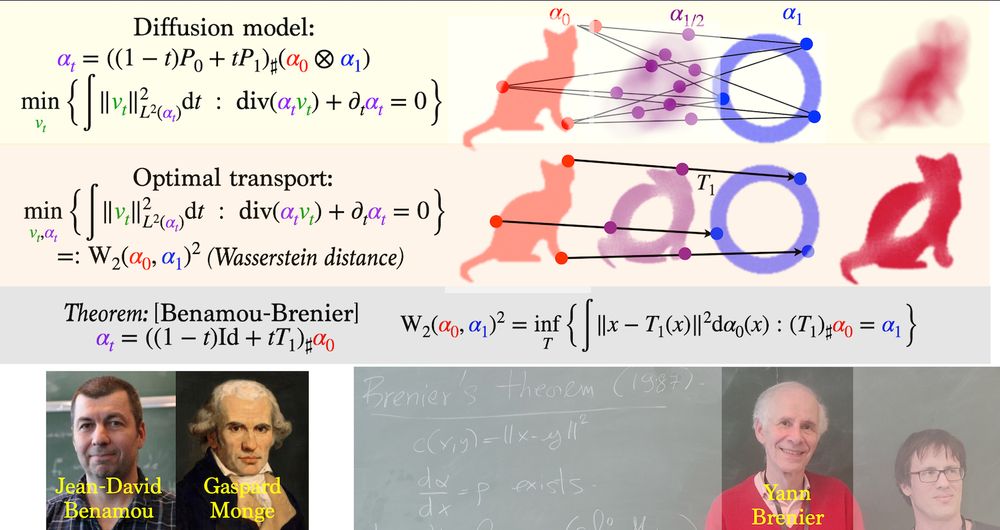
January 15, 2025 at 7:08 PM
Slides for a general introduction to the use of Optimal Transport methods in learning, with an emphasis on diffusion models, flow matching, training 2 layers neural networks and deep transformers. speakerdeck.com/gpeyre/optim...
Reposted by Aditya Arun

I don’t get the DeepSeek freak-out. Chinese orgs have been making models of all sorts that were on par with those of US orgs for a while now.
January 28, 2025 at 12:48 AM
I don’t get the DeepSeek freak-out. Chinese orgs have been making models of all sorts that were on par with those of US orgs for a while now.
Reposted by Aditya Arun
We uploaded yesterday on arXiv a paper on a variant of the "Mutual Information bound" taylored to analyze statistical estimators (MLE, Bayes and variational Bayes, etc).
I assume I should advertise for it after the holidays, but in case you are still online today:
arxiv.org/abs/2412.18539
I assume I should advertise for it after the holidays, but in case you are still online today:
arxiv.org/abs/2412.18539

Convergence of Statistical Estimators via Mutual Information Bounds
Recent advances in statistical learning theory have revealed profound connections between mutual information (MI) bounds, PAC-Bayesian theory, and Bayesian nonparametrics. This work introduces a novel...
arxiv.org
December 25, 2024 at 11:08 AM
We uploaded yesterday on arXiv a paper on a variant of the "Mutual Information bound" taylored to analyze statistical estimators (MLE, Bayes and variational Bayes, etc).
I assume I should advertise for it after the holidays, but in case you are still online today:
arxiv.org/abs/2412.18539
I assume I should advertise for it after the holidays, but in case you are still online today:
arxiv.org/abs/2412.18539
Reposted by Aditya Arun

100%
which reminded me of @ardemp.bsky.social rule #1 on how to science: Don’t be too busy
Being too busy (with noise) = less time to read papers, less time to think and to connect the dots, less time for creative work!
which reminded me of @ardemp.bsky.social rule #1 on how to science: Don’t be too busy
Being too busy (with noise) = less time to read papers, less time to think and to connect the dots, less time for creative work!

December 15, 2024 at 2:28 PM
100%
which reminded me of @ardemp.bsky.social rule #1 on how to science: Don’t be too busy
Being too busy (with noise) = less time to read papers, less time to think and to connect the dots, less time for creative work!
which reminded me of @ardemp.bsky.social rule #1 on how to science: Don’t be too busy
Being too busy (with noise) = less time to read papers, less time to think and to connect the dots, less time for creative work!
Reposted by Aditya Arun

Reinforcement Learning: An Overview
This manuscript gives a big-picture, up-to-date overview of the field of (deep) reinforcement learning and sequential decision making, covering value-based RL, policy-gradient methods, model-based methods, and various other topics.
arxiv.org/abs/2412.05265
This manuscript gives a big-picture, up-to-date overview of the field of (deep) reinforcement learning and sequential decision making, covering value-based RL, policy-gradient methods, model-based methods, and various other topics.
arxiv.org/abs/2412.05265

December 9, 2024 at 8:37 AM
Reinforcement Learning: An Overview
This manuscript gives a big-picture, up-to-date overview of the field of (deep) reinforcement learning and sequential decision making, covering value-based RL, policy-gradient methods, model-based methods, and various other topics.
arxiv.org/abs/2412.05265
This manuscript gives a big-picture, up-to-date overview of the field of (deep) reinforcement learning and sequential decision making, covering value-based RL, policy-gradient methods, model-based methods, and various other topics.
arxiv.org/abs/2412.05265
Reposted by Aditya Arun

I've been around the block a few times. When deep learning first became hot, many older colleagues bemoaned it as just tinkering + chain rule, and not intellectually satisfying. Then came SSL, equivariance, VAEs, GANs, neural ODEs, transformers, diffusion, etc. The richness was staggering.
🧵👇
🧵👇

Great post that captures the tension between classic ML approaches and modern deep learning while acknowledging the nuances of both.
“Working with LLMs doesn’t feel the same. It’s like fitting pieces into a pre-defined puzzle instead of building the puzzle itself.”
www.reddit.com/r/MachineLea...
“Working with LLMs doesn’t feel the same. It’s like fitting pieces into a pre-defined puzzle instead of building the puzzle itself.”
www.reddit.com/r/MachineLea...

From the MachineLearning community on Reddit
Explore this post and more from the MachineLearning community
www.reddit.com
December 6, 2024 at 5:06 PM
I've been around the block a few times. When deep learning first became hot, many older colleagues bemoaned it as just tinkering + chain rule, and not intellectually satisfying. Then came SSL, equivariance, VAEs, GANs, neural ODEs, transformers, diffusion, etc. The richness was staggering.
🧵👇
🧵👇
Reposted by Aditya Arun

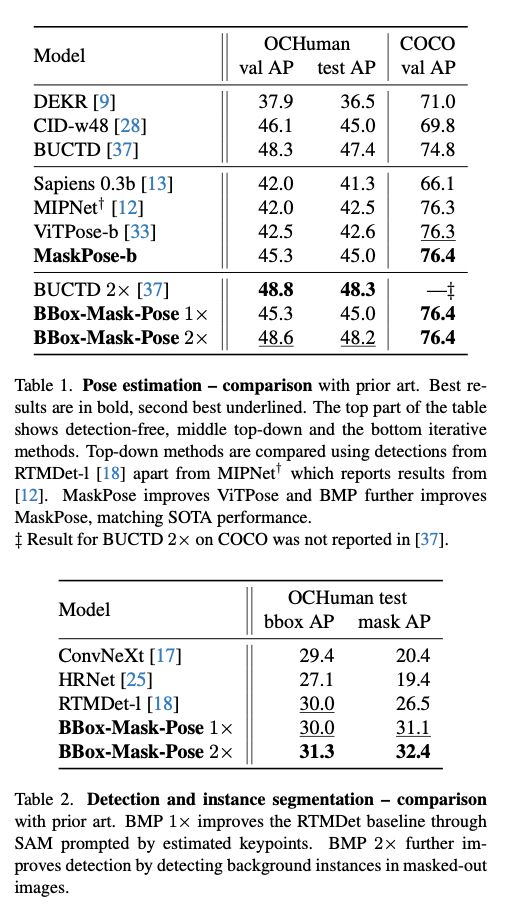
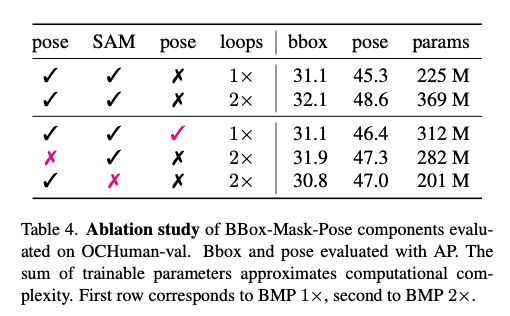
Detection, Pose Estimation and Segmentation for Multiple Bodies: Closing the Virtuous Circle
Miroslav Purkrabek, Jiri Matas
tl;dr: detect bbox -> mask -> estimate human pose -> mask them and repeat. SAM-enabled method :)
arxiv.org/abs/2412.01562
Miroslav Purkrabek, Jiri Matas
tl;dr: detect bbox -> mask -> estimate human pose -> mask them and repeat. SAM-enabled method :)
arxiv.org/abs/2412.01562
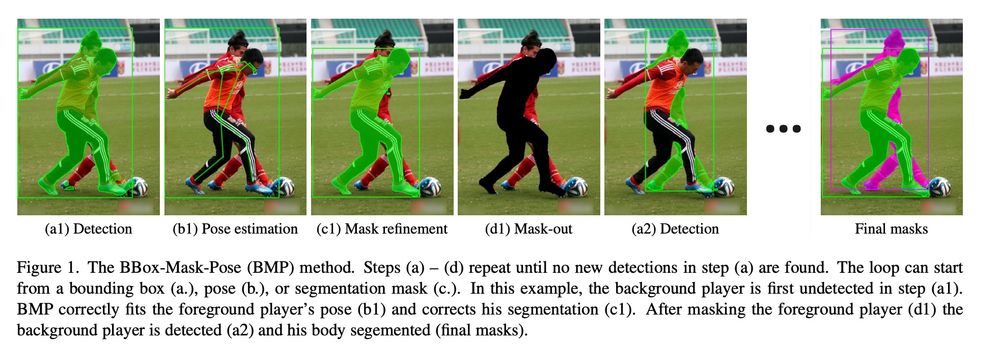

December 3, 2024 at 6:53 PM
Detection, Pose Estimation and Segmentation for Multiple Bodies: Closing the Virtuous Circle
Miroslav Purkrabek, Jiri Matas
tl;dr: detect bbox -> mask -> estimate human pose -> mask them and repeat. SAM-enabled method :)
arxiv.org/abs/2412.01562
Miroslav Purkrabek, Jiri Matas
tl;dr: detect bbox -> mask -> estimate human pose -> mask them and repeat. SAM-enabled method :)
arxiv.org/abs/2412.01562
Reposted by Aditya Arun

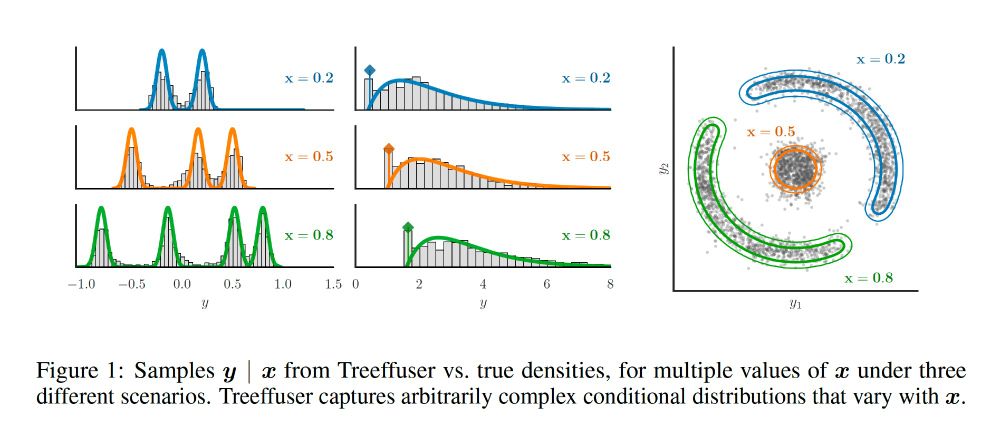
I am very excited to share our new Neurips 2024 paper + package, Treeffuser! 🌳 We combine gradient-boosted trees with diffusion models for fast, flexible probabilistic predictions and well-calibrated uncertainty.
paper: arxiv.org/abs/2406.07658
repo: github.com/blei-lab/tre...
🧵(1/8)
paper: arxiv.org/abs/2406.07658
repo: github.com/blei-lab/tre...
🧵(1/8)
December 2, 2024 at 9:48 PM
I am very excited to share our new Neurips 2024 paper + package, Treeffuser! 🌳 We combine gradient-boosted trees with diffusion models for fast, flexible probabilistic predictions and well-calibrated uncertainty.
paper: arxiv.org/abs/2406.07658
repo: github.com/blei-lab/tre...
🧵(1/8)
paper: arxiv.org/abs/2406.07658
repo: github.com/blei-lab/tre...
🧵(1/8)
Reposted by Aditya Arun

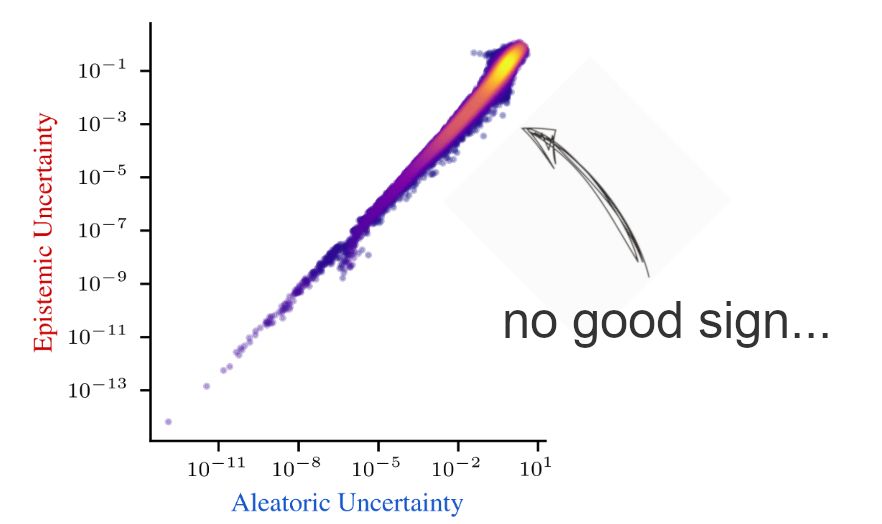
Proud to announce our NeurIPS spotlight, which was in the works for over a year now :) We dig into why decomposing aleatoric and epistemic uncertainty is hard, and what this means for the future of uncertainty quantification.
📖 arxiv.org/abs/2402.19460 🧵1/10
📖 arxiv.org/abs/2402.19460 🧵1/10
December 3, 2024 at 9:45 AM
Proud to announce our NeurIPS spotlight, which was in the works for over a year now :) We dig into why decomposing aleatoric and epistemic uncertainty is hard, and what this means for the future of uncertainty quantification.
📖 arxiv.org/abs/2402.19460 🧵1/10
📖 arxiv.org/abs/2402.19460 🧵1/10
Reposted by Aditya Arun
Optimal transport computes an interpolation between two distributions using an optimal coupling. Flow matching, on the other hand, uses a simpler “independent” coupling, which is the product of the marginals.
December 2, 2024 at 12:46 PM
Optimal transport computes an interpolation between two distributions using an optimal coupling. Flow matching, on the other hand, uses a simpler “independent” coupling, which is the product of the marginals.
Reposted by Aditya Arun

Our big_vision codebase is really good! And it's *the* reference for ViT, SigLIP, PaliGemma, JetFormer, ... including fine-tuning them.
However, it's criminally undocumented. I tried using it outside Google to fine-tune PaliGemma and SigLIP on GPUs, and wrote a tutorial: lb.eyer.be/a/bv_tuto.html
However, it's criminally undocumented. I tried using it outside Google to fine-tune PaliGemma and SigLIP on GPUs, and wrote a tutorial: lb.eyer.be/a/bv_tuto.html

December 3, 2024 at 12:18 AM
Our big_vision codebase is really good! And it's *the* reference for ViT, SigLIP, PaliGemma, JetFormer, ... including fine-tuning them.
However, it's criminally undocumented. I tried using it outside Google to fine-tune PaliGemma and SigLIP on GPUs, and wrote a tutorial: lb.eyer.be/a/bv_tuto.html
However, it's criminally undocumented. I tried using it outside Google to fine-tune PaliGemma and SigLIP on GPUs, and wrote a tutorial: lb.eyer.be/a/bv_tuto.html