




Adrian Hill
@adrianhill.de
PhD student at @bifold.berlin, Machine Learning Group, TU Berlin.
Automatic Differentiation, Explainable AI and #JuliaLang.
Open source person: adrianhill.de/projects
Automatic Differentiation, Explainable AI and #JuliaLang.
Open source person: adrianhill.de/projects
„Making things easy breaks systems that use difficulty as signaling“ @zey.bsky.social @neuripsconf.bsky.social

December 3, 2025 at 11:10 PM
„Making things easy breaks systems that use difficulty as signaling“ @zey.bsky.social @neuripsconf.bsky.social
I'm excited to see whether our idea translates to general MC integration over Jacobians and gradients outside of XAI. Please don't hesitate to talk to us if you have ideas for applications!

December 3, 2025 at 7:36 PM
I'm excited to see whether our idea translates to general MC integration over Jacobians and gradients outside of XAI. Please don't hesitate to talk to us if you have ideas for applications!
Our proposed SmoothDiff method (see first post) offers a bias-variance tradeoff: By neglecting cross-covariances, both sample efficiency and computational speed are improved over naive Monte Carlo integration.

December 3, 2025 at 7:36 PM
Our proposed SmoothDiff method (see first post) offers a bias-variance tradeoff: By neglecting cross-covariances, both sample efficiency and computational speed are improved over naive Monte Carlo integration.
To reduce the influence of white noise, we want to apply a Gaussian convolution (in feature space) as a low-pass filter.
Unfortunately, this convolution is computationally infeasible in high dimensions. Naive Monte Carlo approximation results in the popular SmoothGrad method.
Unfortunately, this convolution is computationally infeasible in high dimensions. Naive Monte Carlo approximation results in the popular SmoothGrad method.

December 3, 2025 at 7:36 PM
To reduce the influence of white noise, we want to apply a Gaussian convolution (in feature space) as a low-pass filter.
Unfortunately, this convolution is computationally infeasible in high dimensions. Naive Monte Carlo approximation results in the popular SmoothGrad method.
Unfortunately, this convolution is computationally infeasible in high dimensions. Naive Monte Carlo approximation results in the popular SmoothGrad method.
Input feature attributions are a popular tool to explain ML models, increasing their trustworthiness. In this work, we are interested in the gradient of a given output w.r.t. its input features.
Unfortunately, gradients of deep NN resemble white noise, rendering them uninformative:
Unfortunately, gradients of deep NN resemble white noise, rendering them uninformative:

December 3, 2025 at 7:36 PM
Input feature attributions are a popular tool to explain ML models, increasing their trustworthiness. In this work, we are interested in the gradient of a given output w.r.t. its input features.
Unfortunately, gradients of deep NN resemble white noise, rendering them uninformative:
Unfortunately, gradients of deep NN resemble white noise, rendering them uninformative:
Join us today from 4:30 to 7:30 PM @neuripsconf.bsky.social Hall C,D,E #1006 for our poster on SmoothDiff, a novel XAI method leveraging automatic differentiation.
🧵1/6
🧵1/6

December 3, 2025 at 7:36 PM
Join us today from 4:30 to 7:30 PM @neuripsconf.bsky.social Hall C,D,E #1006 for our poster on SmoothDiff, a novel XAI method leveraging automatic differentiation.
🧵1/6
🧵1/6
Working on a poster in Typst again. But this time from scratch without any package dependency. 💪
![Proof of concept for a Typst poster with a two-column layout and the entire code that produces it:
```typst
// Poster Template
#set page("a0", flipped: true,
columns: 2,
margin: 3cm,
background: rect(fill: blue, width: 100%, height: 100%),
)
#set columns(gutter: 2cm)
#set par(spacing: 2cm)
#set text(font: "Helvetica", size: 90pt)
#set rect(width: 100%, inset: 1cm, fill: white)
// Content
#place(top, scope: "parent", float: true, clearance: 2cm,
rect(height: 8cm)[Title],
)
#rect(height: 1fr)[Panel 1]
#rect(height: 1fr)[Panel 2]
#rect(height: 1fr)[Panel 3]
#colbreak()
#rect(height: 3fr)[Panel 4]
#rect(height: 2fr)[Panel 5]
#place(bottom, scope: "parent", float: true, clearance: 2cm,
rect(height: 5cm)[Footer],
)
```](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:itr23nhumbwtts2cwfcoj747/bafkreiak5x5jbtq634oinzjb4dwolnjw6xyfxoavdfdk5gqa7lmjojn2ye@jpeg)
November 3, 2025 at 8:52 PM
Working on a poster in Typst again. But this time from scratch without any package dependency. 💪



The perfect use case for UnicodePlots.jl!
github.com/JuliaPlots/U...
github.com/JuliaPlots/U...

July 28, 2025 at 10:29 AM
The perfect use case for UnicodePlots.jl!
github.com/JuliaPlots/U...
github.com/JuliaPlots/U...
According to the Typst team, PDF submissions should be allowed, I hope this is correct:
info.arxiv.org/help/submit_...
info.arxiv.org/help/submit_...

May 14, 2025 at 5:56 PM
According to the Typst team, PDF submissions should be allowed, I hope this is correct:
info.arxiv.org/help/submit_...
info.arxiv.org/help/submit_...
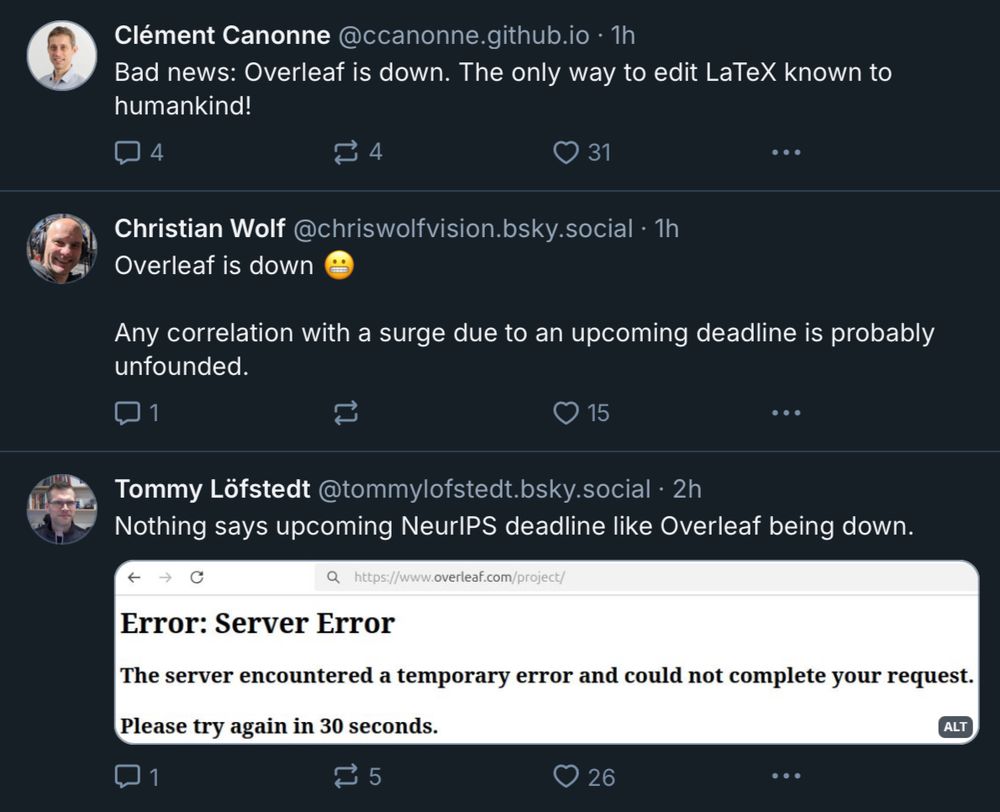
I had to endure some teasing from my collaborators for choosing to write our NeurIPS submission in @typst.app – looks like I have one more reason to believe I made the right call... 😅
May 14, 2025 at 8:48 AM
I had to endure some teasing from my collaborators for choosing to write our NeurIPS submission in @typst.app – looks like I have one more reason to believe I made the right call... 😅
@sirmarcel.bsky.social is still at it

April 30, 2025 at 7:47 AM
@sirmarcel.bsky.social is still at it
Today is a good day, dyed a shirt and made it the front page of HN 🥹


April 30, 2025 at 7:40 AM
Today is a good day, dyed a shirt and made it the front page of HN 🥹


April 23, 2025 at 3:08 AM
The announcement of the "Julia for Machine Learning" course is my most shared skeet on old-BlueSky. Since then, the course material has been extended to include package development in #JuliaLang!
📖: github.com/adrhill/juli...
📖: github.com/adrhill/juli...

April 14, 2025 at 11:44 AM
The announcement of the "Julia for Machine Learning" course is my most shared skeet on old-BlueSky. Since then, the course material has been extended to include package development in #JuliaLang!
📖: github.com/adrhill/juli...
📖: github.com/adrhill/juli...
Chaotic good: Buying Go books for their graphic design

April 12, 2025 at 3:36 PM
Chaotic good: Buying Go books for their graphic design
I previously built a more minimalist, low-profile Bluetooth keyboard, but it ended up being too difficult to switch to when I needed to get work done. So this one is pretty much the opposite. #ergomech #splitkeyboards

February 13, 2025 at 1:10 PM
I previously built a more minimalist, low-profile Bluetooth keyboard, but it ended up being too difficult to switch to when I needed to get work done. So this one is pretty much the opposite. #ergomech #splitkeyboards
BTS of the soldering process:

February 13, 2025 at 1:10 PM
BTS of the soldering process:
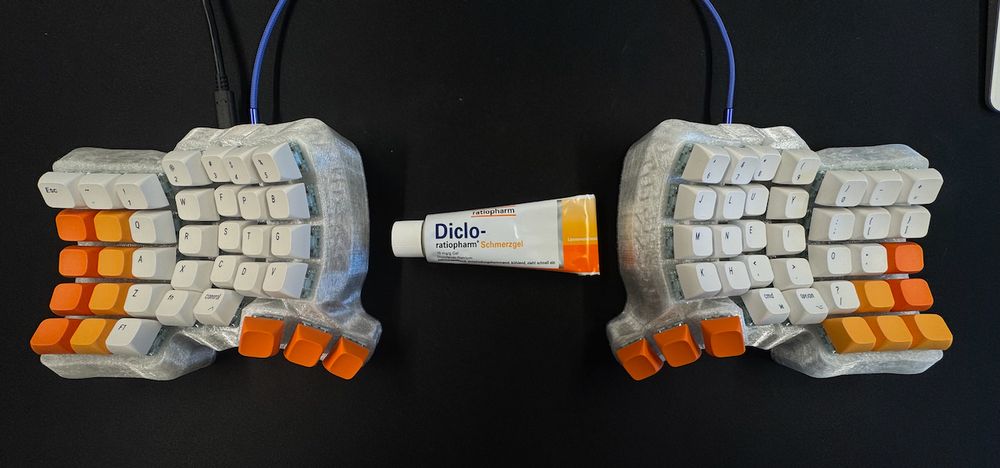
Completed my post preprint project: a split keyboard to help with my wrist pain (pictured with the pain-relieving gel it is trying to replace).
February 13, 2025 at 1:10 PM
Completed my post preprint project: a split keyboard to help with my wrist pain (pictured with the pain-relieving gel it is trying to replace).
We demonstrate that even for one-off computations, end-to-end ASD (yellow line) outperforms AD! When the sparsity pattern can be reused, the performance improvements are even more significant (green line).

January 30, 2025 at 2:32 PM
We demonstrate that even for one-off computations, end-to-end ASD (yellow line) outperforms AD! When the sparsity pattern can be reused, the performance improvements are even more significant (green line).
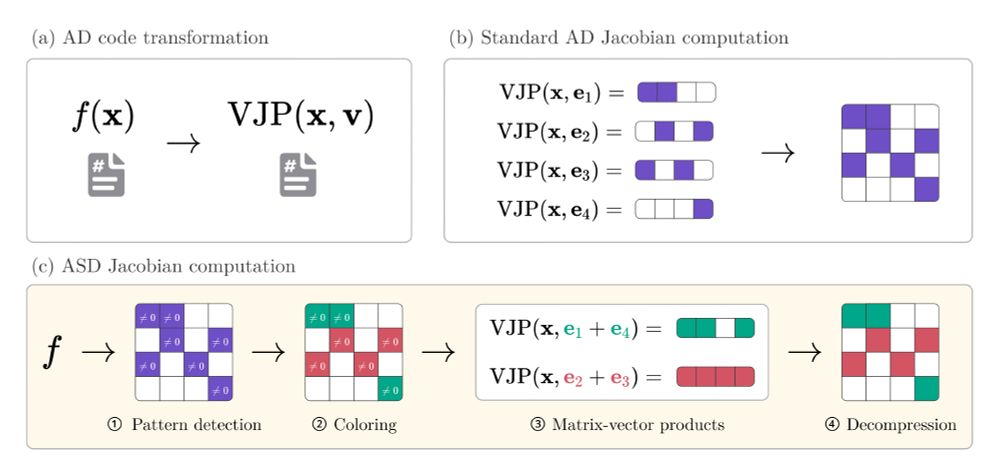
The bottleneck of previous ASD implementations is the detection of sparsity patterns. We describe a faster implementation of pattern detection based on operator overloading which is compatible with generic code bases.

January 30, 2025 at 2:32 PM
The bottleneck of previous ASD implementations is the detection of sparsity patterns. We describe a faster implementation of pattern detection based on operator overloading which is compatible with generic code bases.
However, many of these matrices exhibit sparsity, a property that can be leveraged to speed up AD by orders of magnitude. We call this automatic sparse differentiation (ASD). While known in the AD community, it remains largely ignored in the ML literature.

January 30, 2025 at 2:32 PM
However, many of these matrices exhibit sparsity, a property that can be leveraged to speed up AD by orders of magnitude. We call this automatic sparse differentiation (ASD). While known in the AD community, it remains largely ignored in the ML literature.
You think Jacobian and Hessian matrices are prohibitively expensive to compute on your problem? Our latest preprint with @gdalle.bsky.social might change your mind!
arxiv.org/abs/2501.17737
🧵1/8
arxiv.org/abs/2501.17737
🧵1/8
January 30, 2025 at 2:32 PM
You think Jacobian and Hessian matrices are prohibitively expensive to compute on your problem? Our latest preprint with @gdalle.bsky.social might change your mind!
arxiv.org/abs/2501.17737
🧵1/8
arxiv.org/abs/2501.17737
🧵1/8