
Adam Morgan
@adumbmoron.bsky.social
840 followers
440 following
44 posts
Postdoc at NYU using ECoG to study how the brain translates from thought to language. On the job market! 🏳️🌈🏳️⚧️🗳️ he/him
https://adam-milton-morgan.github.io/
Posts
Media
Videos
Starter Packs
Pinned

Adam Morgan
@adumbmoron.bsky.social
· Jun 5
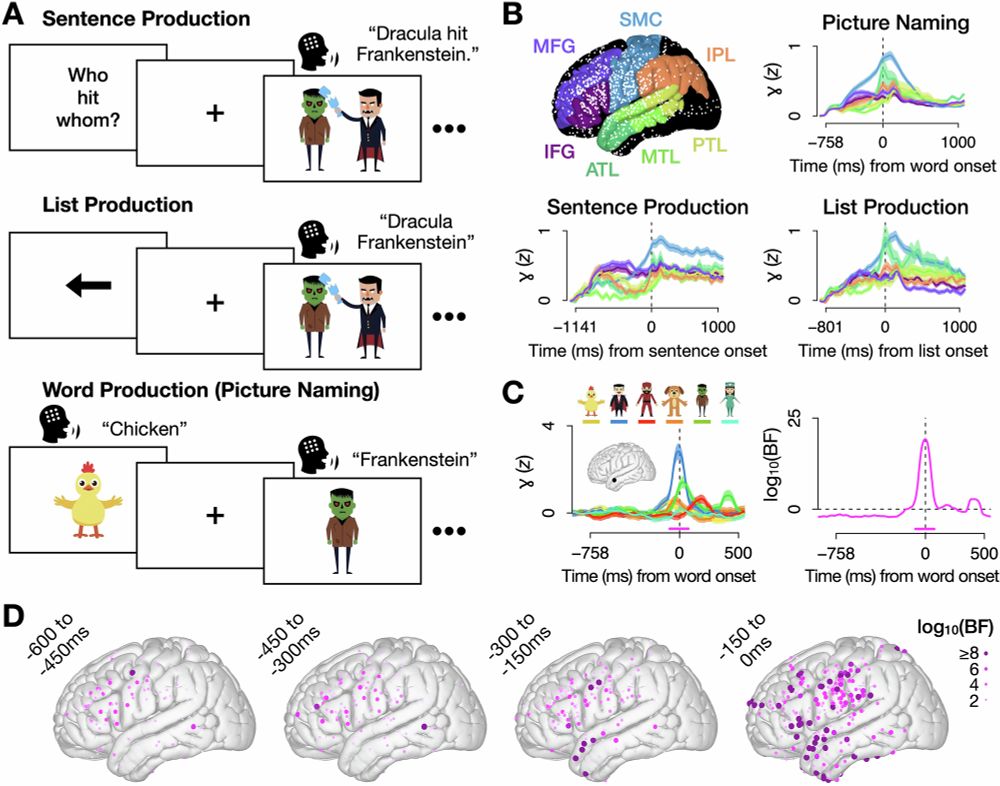
Decoding words during sentence production with ECoG reveals syntactic role encoding and structure-dependent temporal dynamics
Communications Psychology - Using electrical recordings taken from the surface of the brain, researchers decode what words neurosurgical patients are saying and show that the brain plans words in a...
rdcu.be
Reposted by Adam Morgan



Adam Morgan
@adumbmoron.bsky.social
· Jul 31
A Scalable Pipeline for Estimating Verb Frame Frequencies Using Large Language Models
We present an automated pipeline for estimating Verb Frame Frequencies (VFFs), the frequency with which a verb appears in particular syntactic frames. VFFs provide a powerful window into syntax in bot...
doi.org
Adam Morgan
@adumbmoron.bsky.social
· Jul 31


Adam Morgan
@adumbmoron.bsky.social
· Jul 31
Adam Morgan
@adumbmoron.bsky.social
· Jul 31
Adam Morgan
@adumbmoron.bsky.social
· Jul 31
Adam Morgan
@adumbmoron.bsky.social
· Jul 31
A Scalable Pipeline for Estimating Verb Frame Frequencies Using Large Language Models
We present an automated pipeline for estimating Verb Frame Frequencies (VFFs), the frequency with which a verb appears in particular syntactic frames. VFFs provide a powerful window into syntax in bot...
doi.org
Adam Morgan
@adumbmoron.bsky.social
· Jun 26

Adam Morgan
@adumbmoron.bsky.social
· Jun 5
Adam Morgan
@adumbmoron.bsky.social
· Jun 5
Adam Morgan
@adumbmoron.bsky.social
· Jun 5

Decoding words during sentence production with ECoG reveals syntactic role encoding and structure-dependent temporal dynamics - Communications Psychology
Using electrical recordings taken from the surface of the brain, researchers decode what words neurosurgical patients are saying and show that the brain plans words in a different order than they are ...
doi.org
Adam Morgan
@adumbmoron.bsky.social
· Jun 5
Adam Morgan
@adumbmoron.bsky.social
· Jun 5





Adam Morgan
@adumbmoron.bsky.social
· Jun 5
Decoding words during sentence production with ECoG reveals syntactic role encoding and structure-dependent temporal dynamics
Communications Psychology - Using electrical recordings taken from the surface of the brain, researchers decode what words neurosurgical patients are saying and show that the brain plans words in a...
rdcu.be
Adam Morgan
@adumbmoron.bsky.social
· Jun 4


Adam Morgan
@adumbmoron.bsky.social
· Mar 29