

A Erdem Sagtekin
@aesagtekin.bsky.social
620 followers
3 following
2 posts
chronic reader of old papers. dynamical systems & computation & bio-plausible learning. curr: @flatiron ccn, msc: comp neuro @tubingen, bsc: EE.
Posts
Media
Videos
Starter Packs
Reposted by A Erdem Sagtekin

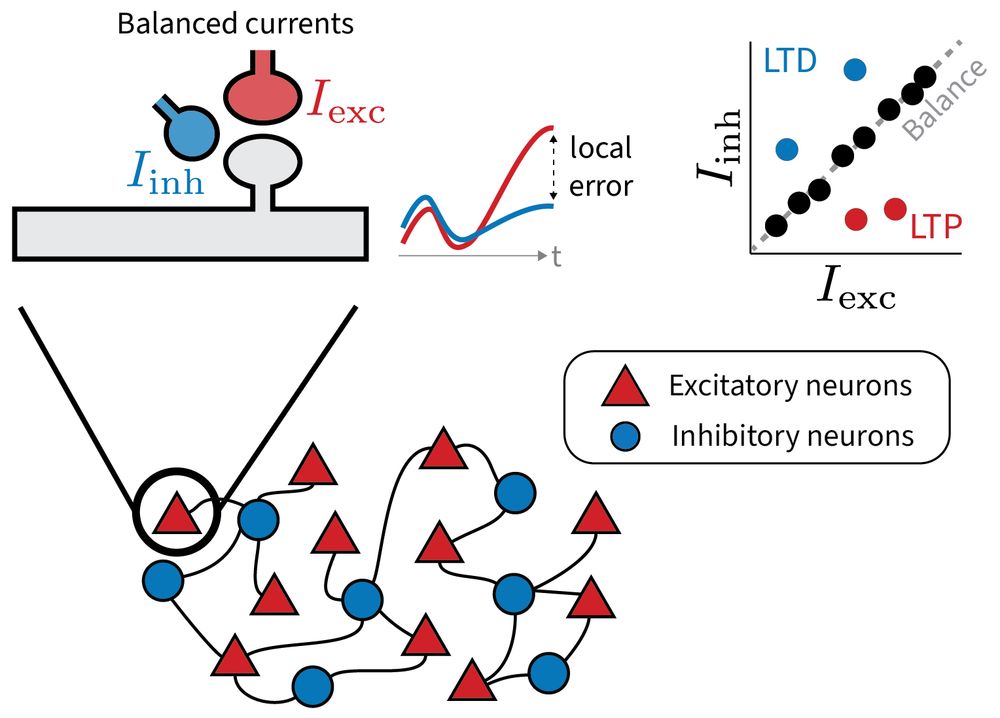
Reposted by A Erdem Sagtekin

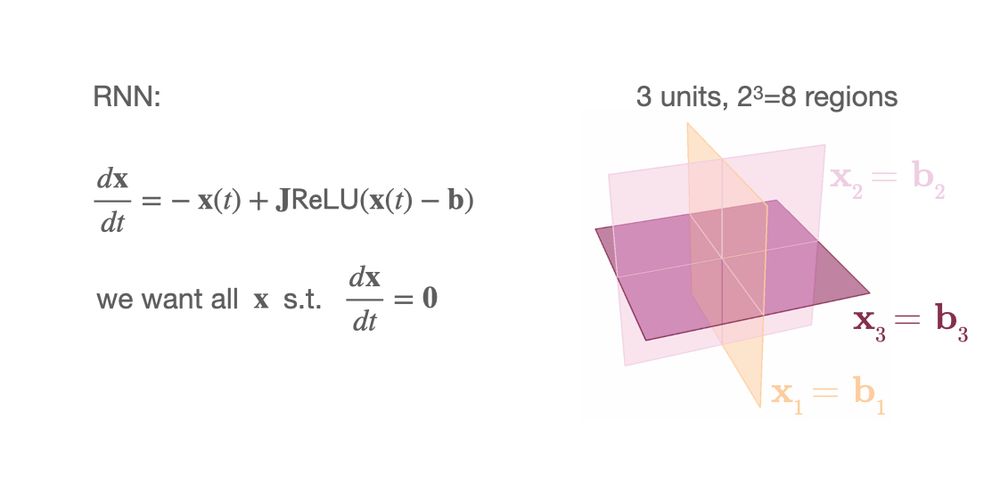




Blake Richards
@tyrellturing.bsky.social
· Oct 28
