Andrew White 🐦⬛
@andrew.diffuse.one
2.9K followers
230 following
90 posts
Head of Sci/cofounder at futurehouse.org. Prof of chem eng at UofR (on sabbatical). Automating science with AI and robots in biology. Corvid enthusiast
Posts
Media
Videos
Starter Packs






Andrew White 🐦⬛
@andrew.diffuse.one
· Jul 23

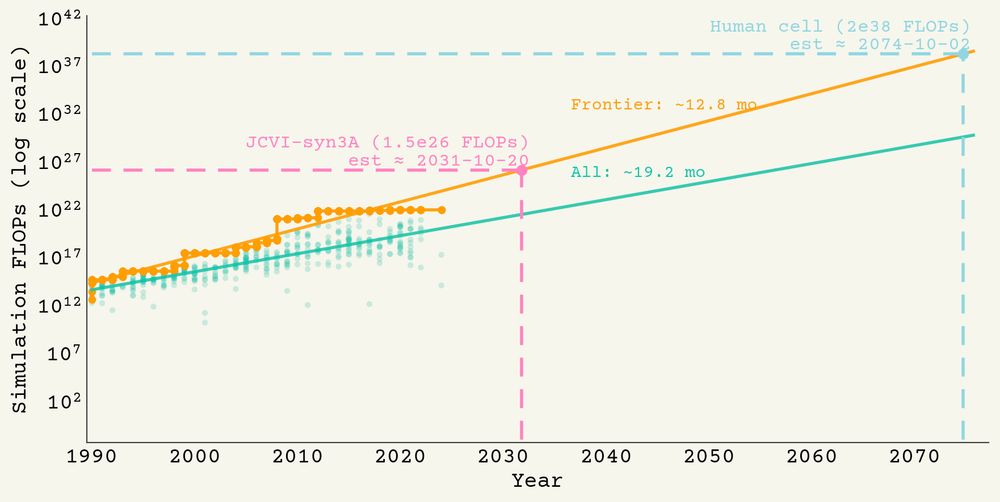
Andrew White 🐦⬛
@andrew.diffuse.one
· Jul 23
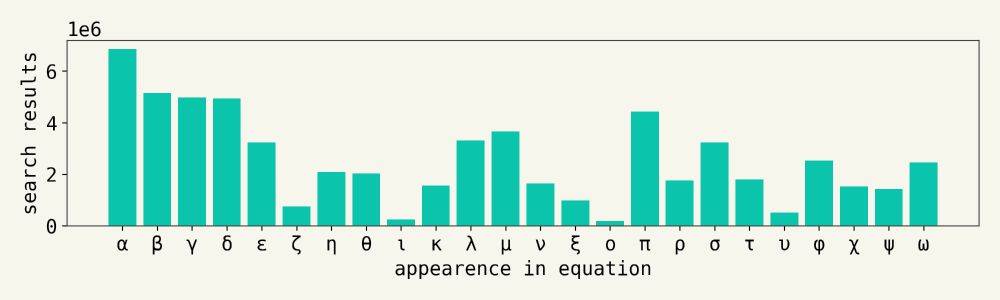
Andrew White 🐦⬛
@andrew.diffuse.one
· Jul 23


Andrew White 🐦⬛
@andrew.diffuse.one
· Jul 23
Andrew White 🐦⬛
@andrew.diffuse.one
· Jul 12
Reposted by Andrew White 🐦⬛





