
Angelina Wang
@angelinawang.bsky.social
1.9K followers
350 following
18 posts
Asst Prof at Cornell Info Sci and Cornell Tech. Responsible AI
https://angelina-wang.github.io/
Posts
Media
Videos
Starter Packs
Pinned

Angelina Wang
@angelinawang.bsky.social
· Jul 30
Reposted by Angelina Wang


Reposted by Angelina Wang


Reposted by Angelina Wang


Reposted by Angelina Wang

Hanna Wallach
@hannawallach.bsky.social
· Jun 15




Angelina Wang
@angelinawang.bsky.social
· Mar 17
Angelina Wang
@angelinawang.bsky.social
· Mar 17
Reposted by Angelina Wang

Nikhil Garg
@nkgarg.bsky.social
· Mar 10
Reposted by Angelina Wang


Reposted by Angelina Wang
Angelina Wang
@angelinawang.bsky.social
· Feb 20
Angelina Wang
@angelinawang.bsky.social
· Feb 20
Reposted by Angelina Wang

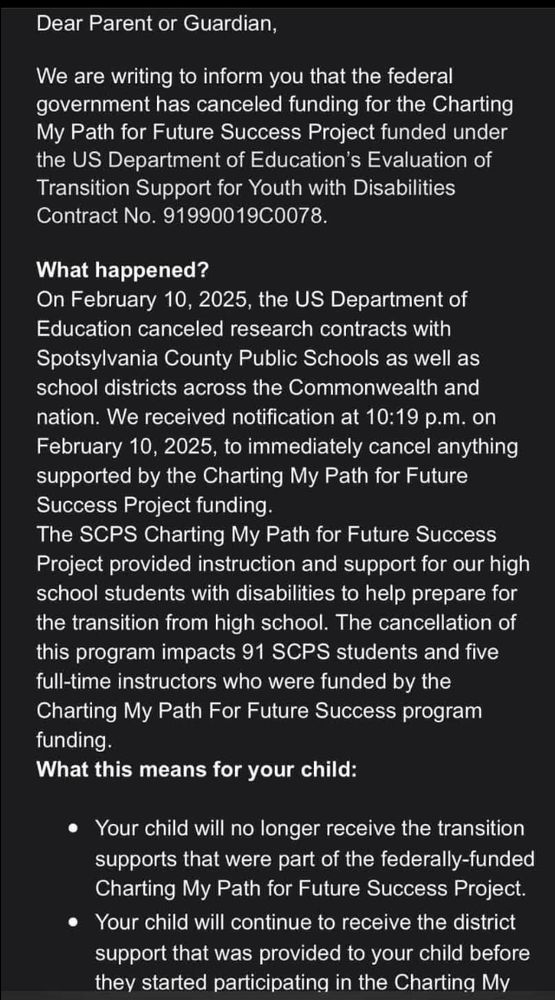
Angelina Wang
@angelinawang.bsky.social
· Feb 17

Large language models that replace human participants can harmfully misportray and flatten identity groups
Nature Machine Intelligence - Large language models are being considered to simulate responses from participants of different backgrounds in computational social science experiments. Here it is...
rdcu.be
Angelina Wang
@angelinawang.bsky.social
· Feb 17
Angelina Wang
@angelinawang.bsky.social
· Feb 17
Angelina Wang
@angelinawang.bsky.social
· Feb 17
Reposted by Angelina Wang

