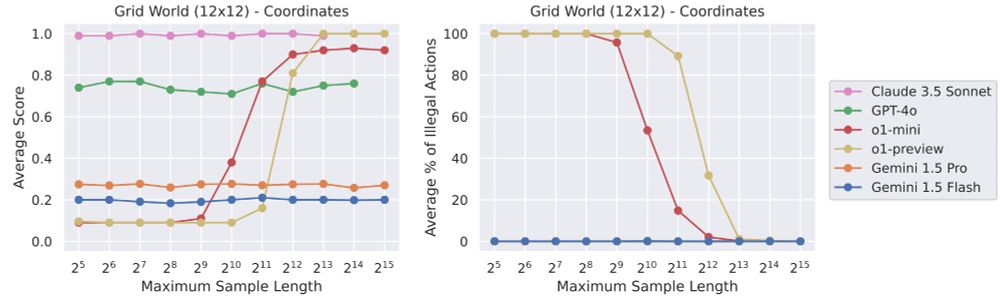
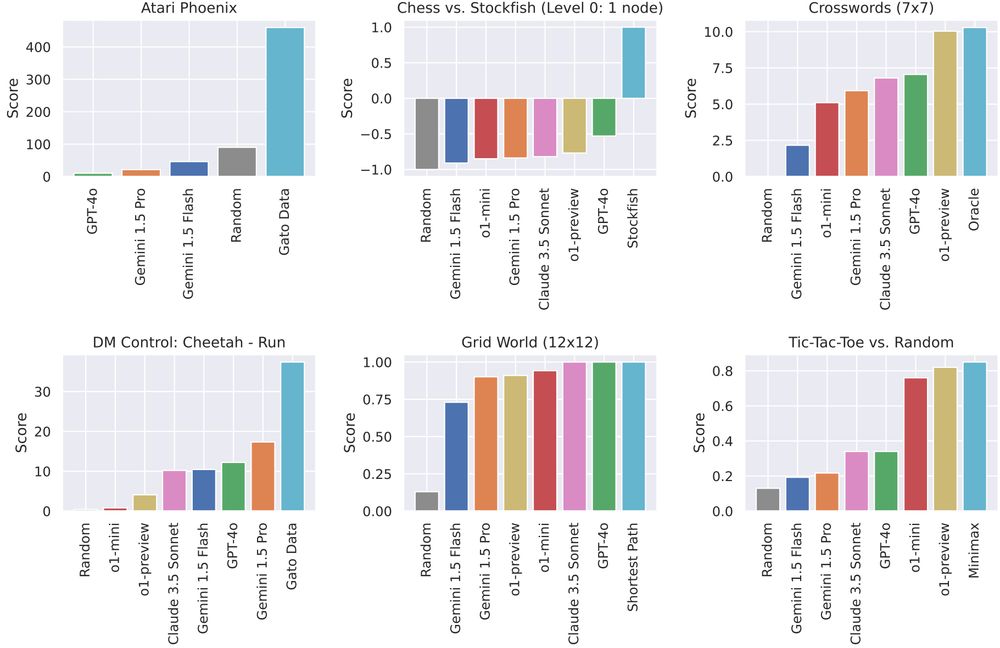
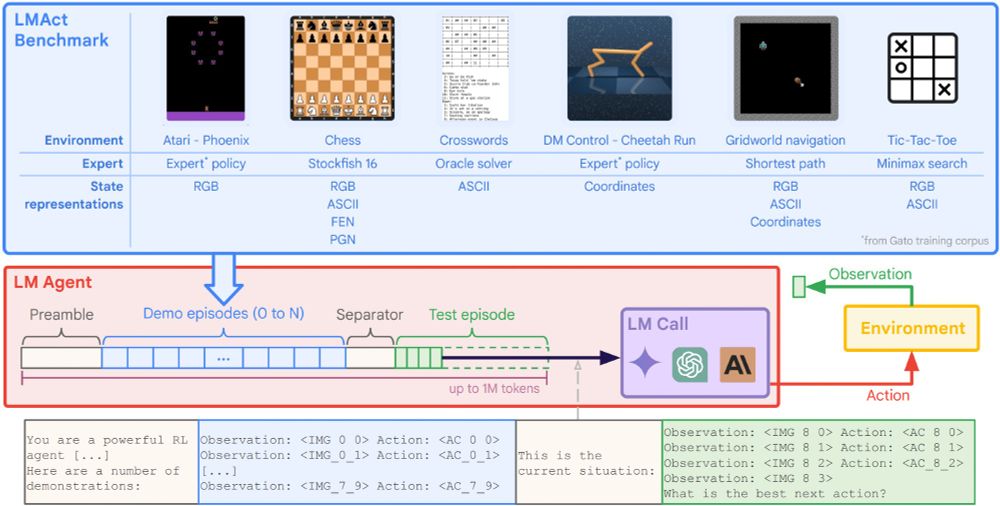
Ever wonder how well frontier models (Claude 3.5 Sonnet, Gemini 1.5 Flash & Pro, GPT-4o, o1-mini & o1-preview) play Atari, chess, or tic-tac-toe?
We present LMAct, an in-context imitation learning benchmark with long multimodal demonstrations (
arxiv.org/abs/2412.01441).
🧵 1/N