
Archiki Prasad
@archiki.bsky.social
620 followers
840 following
24 posts
Ph.D. Student at UNC NLP | Apple Scholar in AI/ML Ph.D. Fellowship | Prev: FAIR at Meta, AI2, Adobe (Intern) | Interests: #NLP, #ML | https://archiki.github.io/
Posts
Media
Videos
Starter Packs
Pinned


Reposted by Archiki Prasad


Reposted by Archiki Prasad
Elias Stengel-Eskin
@esteng.bsky.social
· Apr 30

Reposted by Archiki Prasad
Elias Stengel-Eskin
@esteng.bsky.social
· Apr 29
Reposted by Archiki Prasad
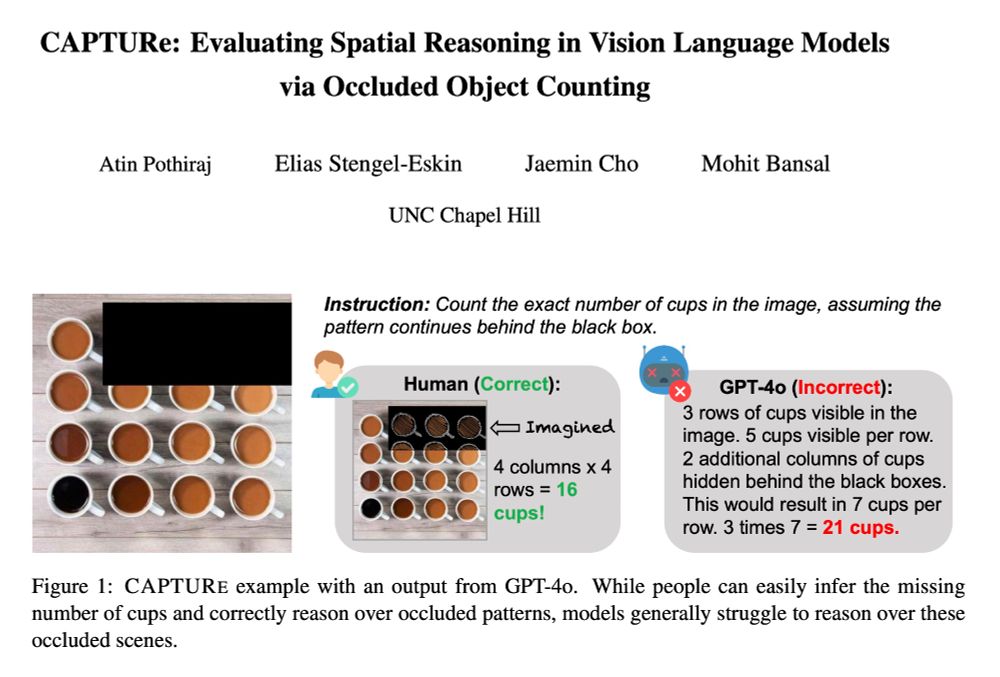
Reposted by Archiki Prasad


Archiki Prasad
@archiki.bsky.social
· Apr 18

Retrieval-Augmented Generation with Conflicting Evidence
Large language model (LLM) agents are increasingly employing retrieval-augmented generation (RAG) to improve the factuality of their responses. However, in practice, these systems often need to handle...
arxiv.org





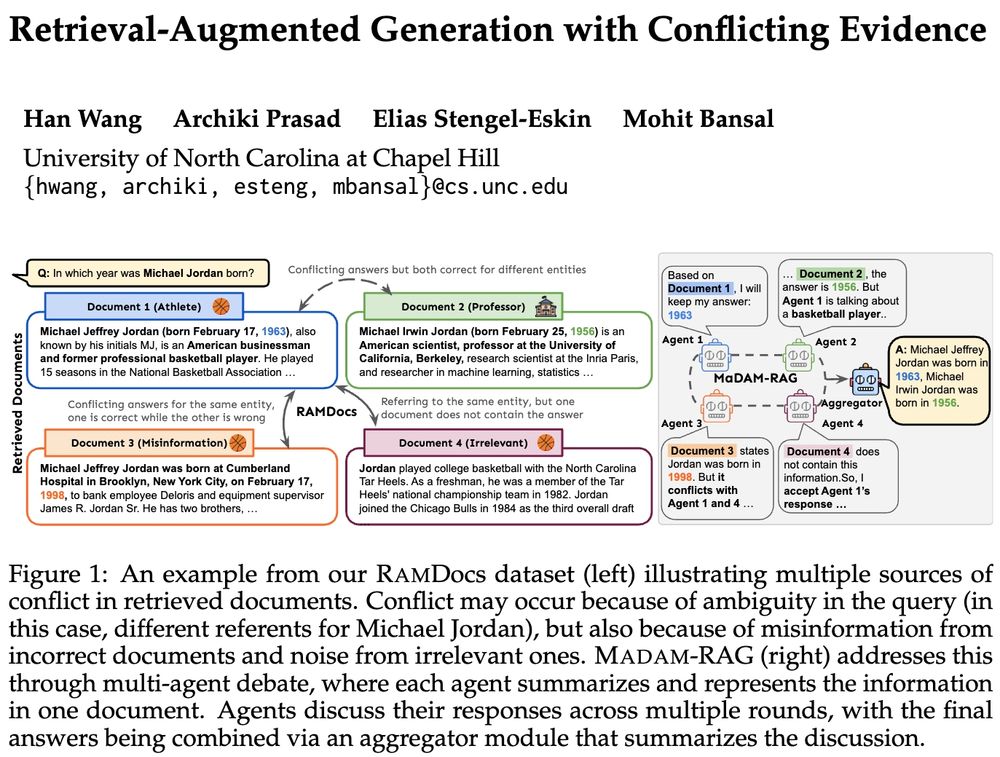
Reposted by Archiki Prasad

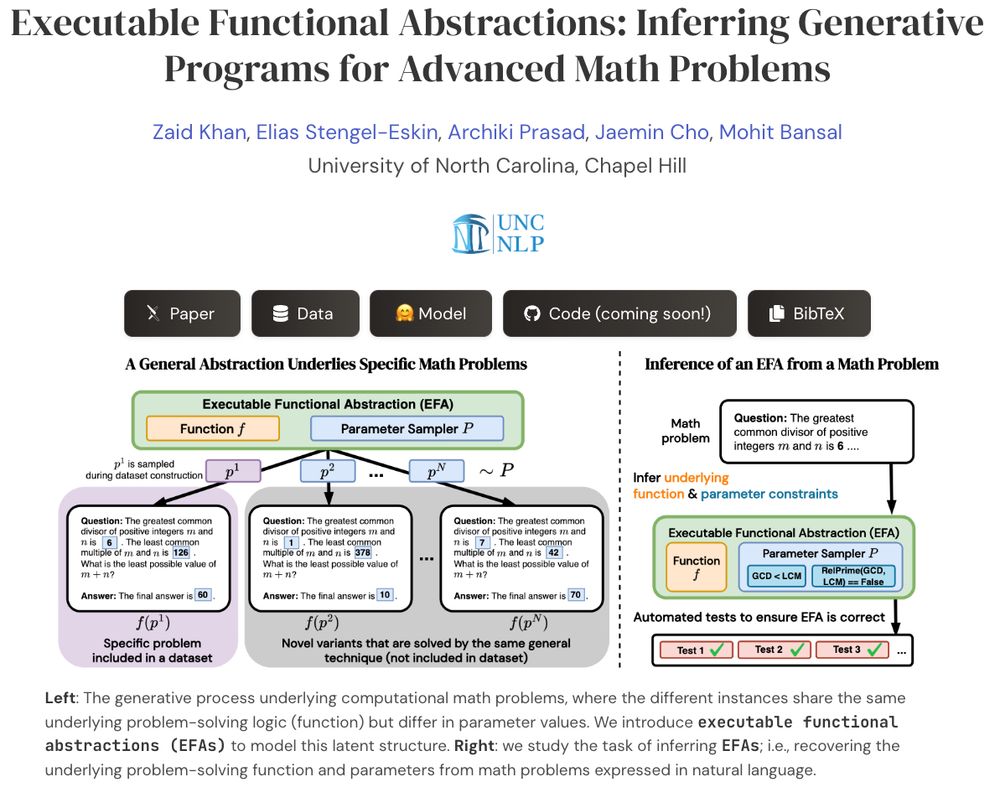
Reposted by Archiki Prasad
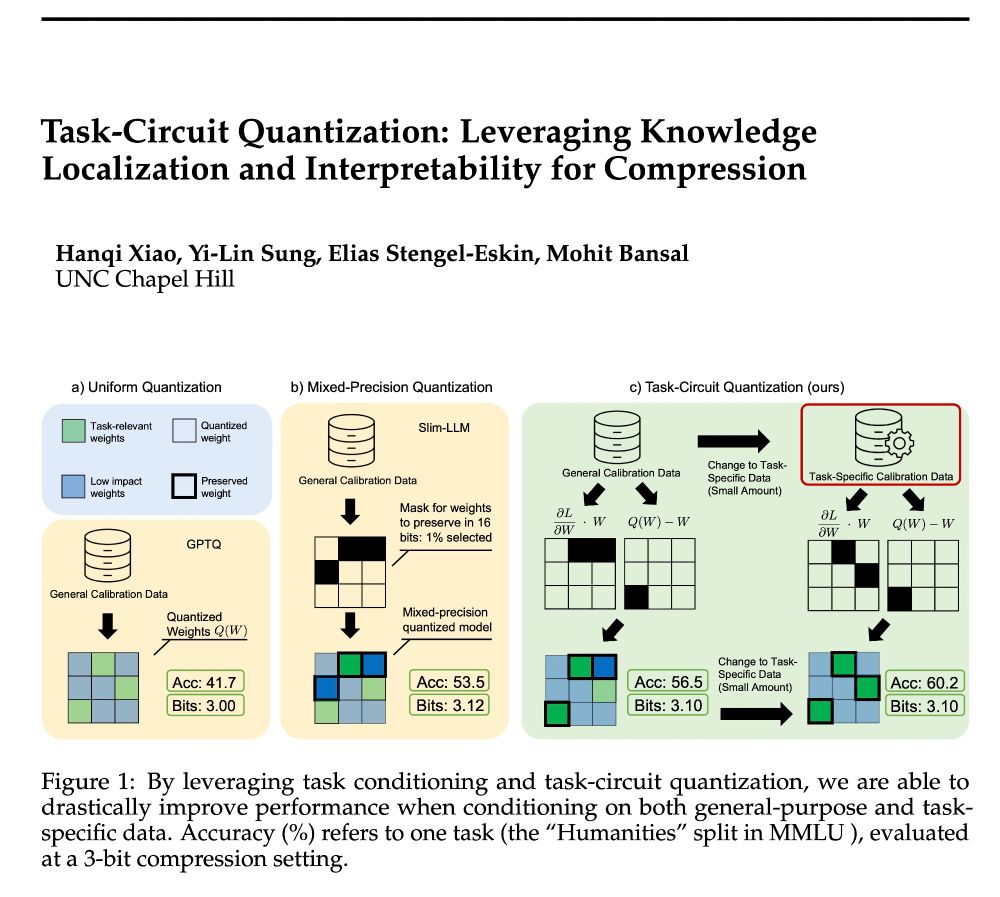
Reposted by Archiki Prasad

Archiki Prasad
@archiki.bsky.social
· Mar 27
Archiki Prasad
@archiki.bsky.social
· Mar 27
Reposted by Archiki Prasad
Reposted by Archiki Prasad


Reposted by Archiki Prasad

Archiki Prasad
@archiki.bsky.social
· Feb 4

Learning to Generate Unit Tests for Automated Debugging
Unit tests (UTs) play an instrumental role in assessing code correctness as well as providing feedback to a large language model (LLM) as it iteratively debugs faulty code, motivating automated test g...
arxiv.org



