



Arindam Majumder
@arindam-1729.bsky.social
Developer Advocate and Technical Writer (500k+ Views) | Building Studio1Hq.com
Also added an Events page to track the talks I’ve done so far (not many yet 😅).
Hopefully, this section looks a lot more crowded in 2026.
x.com/Arindam_172...
Hopefully, this section looks a lot more crowded in 2026.
x.com/Arindam_172...

December 20, 2025 at 3:06 PM
Also added an Events page to track the talks I’ve done so far (not many yet 😅).
Hopefully, this section looks a lot more crowded in 2026.
x.com/Arindam_172...
Hopefully, this section looks a lot more crowded in 2026.
x.com/Arindam_172...
Updated my Portfolio after Ages! 😅
Kept it simple and short!
Let me know what you think about it!
Kept it simple and short!
Let me know what you think about it!

December 20, 2025 at 2:59 PM
Updated my Portfolio after Ages! 😅
Kept it simple and short!
Let me know what you think about it!
Kept it simple and short!
Let me know what you think about it!
Published a Cookbook on Fine-Tuning!
Learn How to Fine-tune your Open Sorce LLMs and Deploy them on @nebiustf
All under a few minutes!
Full notebook is in the comments 👇
Learn How to Fine-tune your Open Sorce LLMs and Deploy them on @nebiustf
All under a few minutes!
Full notebook is in the comments 👇

December 19, 2025 at 12:32 PM
Published a Cookbook on Fine-Tuning!
Learn How to Fine-tune your Open Sorce LLMs and Deploy them on @nebiustf
All under a few minutes!
Full notebook is in the comments 👇
Learn How to Fine-tune your Open Sorce LLMs and Deploy them on @nebiustf
All under a few minutes!
Full notebook is in the comments 👇
We Got Another App Store!

December 18, 2025 at 8:23 AM
We Got Another App Store!
Migrating to a new version is usually painful 😵💫
But this MCP server makes it… surprisingly easy.
Just plug it into Cursor or Claude Code, ask it to migrate your Next.js app to the latest version, and it actually does the work.
No guesswork. No broken upgrades.
@Vercel really cares about DX.
But this MCP server makes it… surprisingly easy.
Just plug it into Cursor or Claude Code, ask it to migrate your Next.js app to the latest version, and it actually does the work.
No guesswork. No broken upgrades.
@Vercel really cares about DX.

December 16, 2025 at 12:07 PM
Migrating to a new version is usually painful 😵💫
But this MCP server makes it… surprisingly easy.
Just plug it into Cursor or Claude Code, ask it to migrate your Next.js app to the latest version, and it actually does the work.
No guesswork. No broken upgrades.
@Vercel really cares about DX.
But this MCP server makes it… surprisingly easy.
Just plug it into Cursor or Claude Code, ask it to migrate your Next.js app to the latest version, and it actually does the work.
No guesswork. No broken upgrades.
@Vercel really cares about DX.
My Friends at @CopilotKit are trending on GitHub! 🔥

December 14, 2025 at 3:44 PM
My Friends at @CopilotKit are trending on GitHub! 🔥
I’ll be speaking at @MongoDB Kolkata Meetup on 14th Dec!
Topic: Understanding Agentic Memory with MongoDB and @memorilab
If you're around, let’s catch up 👋
Topic: Understanding Agentic Memory with MongoDB and @memorilab
If you're around, let’s catch up 👋

December 12, 2025 at 12:26 PM
I’ll be speaking at @MongoDB Kolkata Meetup on 14th Dec!
Topic: Understanding Agentic Memory with MongoDB and @memorilab
If you're around, let’s catch up 👋
Topic: Understanding Agentic Memory with MongoDB and @memorilab
If you're around, let’s catch up 👋
Time to Burn some Tokens!

December 11, 2025 at 7:39 PM
Time to Burn some Tokens!
I’ll be speaking at @nebiustf Builder Hour #1 👀
Walking through what I’ve been building lately + a small peek at what’s coming next.
Come hang out today at 9 AM PT / 10:30 PM IST.
Link in the comments
Walking through what I’ve been building lately + a small peek at what’s coming next.
Come hang out today at 9 AM PT / 10:30 PM IST.
Link in the comments

December 9, 2025 at 2:25 PM
I’ll be speaking at @nebiustf Builder Hour #1 👀
Walking through what I’ve been building lately + a small peek at what’s coming next.
Come hang out today at 9 AM PT / 10:30 PM IST.
Link in the comments
Walking through what I’ve been building lately + a small peek at what’s coming next.
Come hang out today at 9 AM PT / 10:30 PM IST.
Link in the comments
Google recently dropped a full “vibe coding” workflow inside AI Studio… and it’s clean 👀
You can now build apps by talking to your editor.
Describe the feature → AI writes it → you refine → it ships.
The gap between idea and working code just shrank by 10x.
Less typing. More building.
You can now build apps by talking to your editor.
Describe the feature → AI writes it → you refine → it ships.
The gap between idea and working code just shrank by 10x.
Less typing. More building.

December 6, 2025 at 5:03 PM
Google recently dropped a full “vibe coding” workflow inside AI Studio… and it’s clean 👀
You can now build apps by talking to your editor.
Describe the feature → AI writes it → you refine → it ships.
The gap between idea and working code just shrank by 10x.
Less typing. More building.
You can now build apps by talking to your editor.
Describe the feature → AI writes it → you refine → it ships.
The gap between idea and working code just shrank by 10x.
Less typing. More building.
Currently playing around with @memorilab v3
and it has some really cool Features!
and it has some really cool Features!

December 3, 2025 at 12:26 PM
Currently playing around with @memorilab v3
and it has some really cool Features!
and it has some really cool Features!
Just deployed my first fine-tuned model on @nebiustf 👀
Super smooth process, way easier than I expected.
Recording a full step-by-step guide next. Stay tuned!
Super smooth process, way easier than I expected.
Recording a full step-by-step guide next. Stay tuned!

December 1, 2025 at 3:28 PM
Just deployed my first fine-tuned model on @nebiustf 👀
Super smooth process, way easier than I expected.
Recording a full step-by-step guide next. Stay tuned!
Super smooth process, way easier than I expected.
Recording a full step-by-step guide next. Stay tuned!
Introducing arXiv Researcher Agent!🕵🏻♂️
We built an AI Agent that:
- Searches arXiv and generates clean research reports
- Saves findings with persistent memory
- Recalls and builds on past sessions
Built with @nebiustf , @memorilab , @tavilyai and @streamlit
Here's the Demo:
We built an AI Agent that:
- Searches arXiv and generates clean research reports
- Saves findings with persistent memory
- Recalls and builds on past sessions
Built with @nebiustf , @memorilab , @tavilyai and @streamlit
Here's the Demo:
November 25, 2025 at 3:57 PM
Introducing arXiv Researcher Agent!🕵🏻♂️
We built an AI Agent that:
- Searches arXiv and generates clean research reports
- Saves findings with persistent memory
- Recalls and builds on past sessions
Built with @nebiustf , @memorilab , @tavilyai and @streamlit
Here's the Demo:
We built an AI Agent that:
- Searches arXiv and generates clean research reports
- Saves findings with persistent memory
- Recalls and builds on past sessions
Built with @nebiustf , @memorilab , @tavilyai and @streamlit
Here's the Demo:
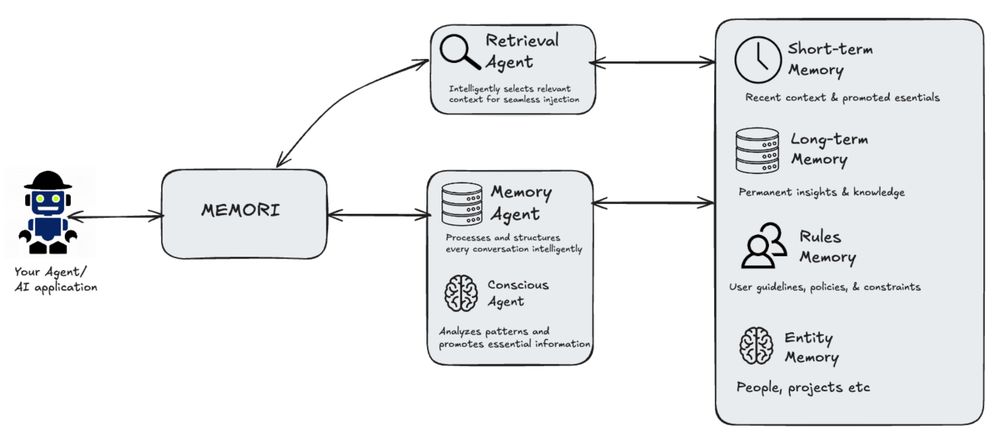
AI memory doesn’t need exotic databases
@memorilab's Memori uses traditional SQL to power agent memory:
- Short-term convos in temp tables
- Long-term facts promoted to permanent storage
- Rules, preferences, entities stored as structured data
Proven, efficient, and scalable👇
@memorilab's Memori uses traditional SQL to power agent memory:
- Short-term convos in temp tables
- Long-term facts promoted to permanent storage
- Rules, preferences, entities stored as structured data
Proven, efficient, and scalable👇
November 25, 2025 at 12:32 PM
AI memory doesn’t need exotic databases
@memorilab's Memori uses traditional SQL to power agent memory:
- Short-term convos in temp tables
- Long-term facts promoted to permanent storage
- Rules, preferences, entities stored as structured data
Proven, efficient, and scalable👇
@memorilab's Memori uses traditional SQL to power agent memory:
- Short-term convos in temp tables
- Long-term facts promoted to permanent storage
- Rules, preferences, entities stored as structured data
Proven, efficient, and scalable👇
I’ve been building a lot with Claude Code lately…
But writing code is one thing, shipping reliable code is a whole different game 👀
So I recorded a full breakdown of the exact workflow I use to keep AI-generated code production-ready.
Full video here👇
But writing code is one thing, shipping reliable code is a whole different game 👀
So I recorded a full breakdown of the exact workflow I use to keep AI-generated code production-ready.
Full video here👇

November 24, 2025 at 12:28 PM
I’ve been building a lot with Claude Code lately…
But writing code is one thing, shipping reliable code is a whole different game 👀
So I recorded a full breakdown of the exact workflow I use to keep AI-generated code production-ready.
Full video here👇
But writing code is one thing, shipping reliable code is a whole different game 👀
So I recorded a full breakdown of the exact workflow I use to keep AI-generated code production-ready.
Full video here👇
Gemini created it in one Prompt!
Crazy to think, How far we have come!
Crazy to think, How far we have come!
November 23, 2025 at 5:05 PM
Gemini created it in one Prompt!
Crazy to think, How far we have come!
Crazy to think, How far we have come!
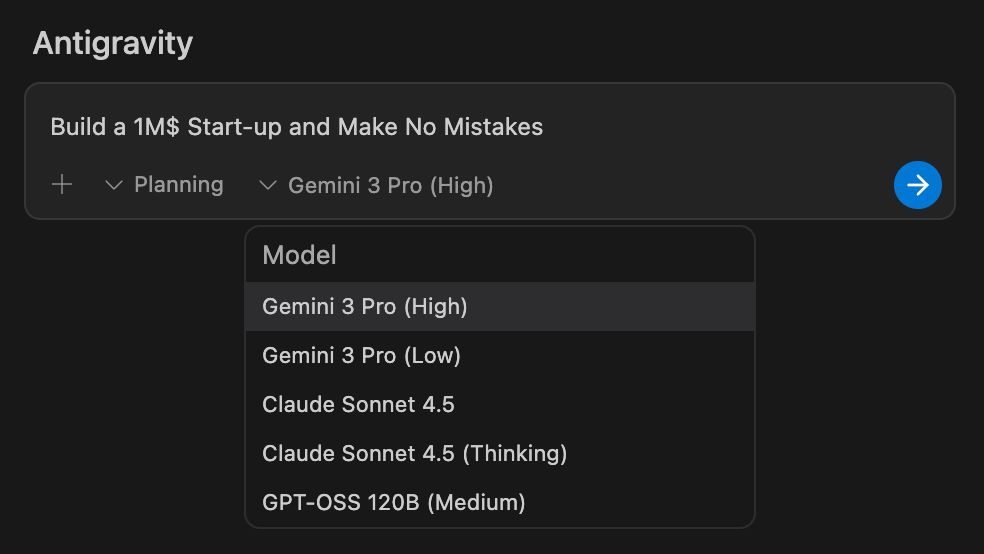
Trying our Google's Antigravity with Gemini 3 Pro!
November 18, 2025 at 5:42 PM
Trying our Google's Antigravity with Gemini 3 Pro!
Just tried Anthropic’s @claudeai Code Web 👀
I pushed it on two tasks:
• Fixing API endpoints across a repo
• Building an AI Agent team with @AgnoAgi
The results were… interesting. Some things worked great, some didn’t.
Watch it here👇
youtube.com/watch?v=nIt...
I pushed it on two tasks:
• Fixing API endpoints across a repo
• Building an AI Agent team with @AgnoAgi
The results were… interesting. Some things worked great, some didn’t.
Watch it here👇
youtube.com/watch?v=nIt...

November 18, 2025 at 3:29 PM
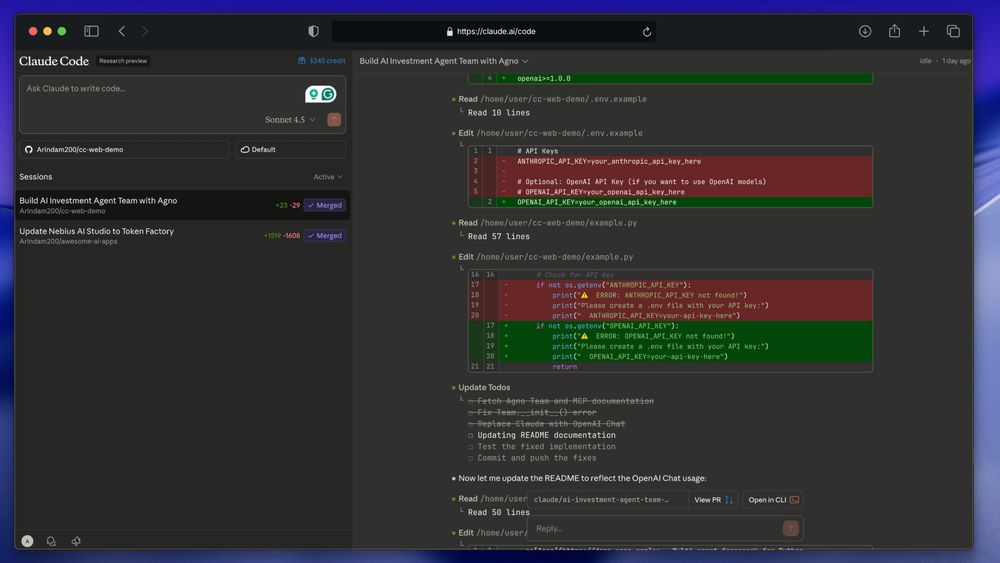
Just tried Anthropic’s @claudeai Code Web 👀
I pushed it on two tasks:
• Fixing API endpoints across a repo
• Building an AI Agent team with @AgnoAgi
The results were… interesting. Some things worked great, some didn’t.
Watch it here👇
youtube.com/watch?v=nIt...
I pushed it on two tasks:
• Fixing API endpoints across a repo
• Building an AI Agent team with @AgnoAgi
The results were… interesting. Some things worked great, some didn’t.
Watch it here👇
youtube.com/watch?v=nIt...
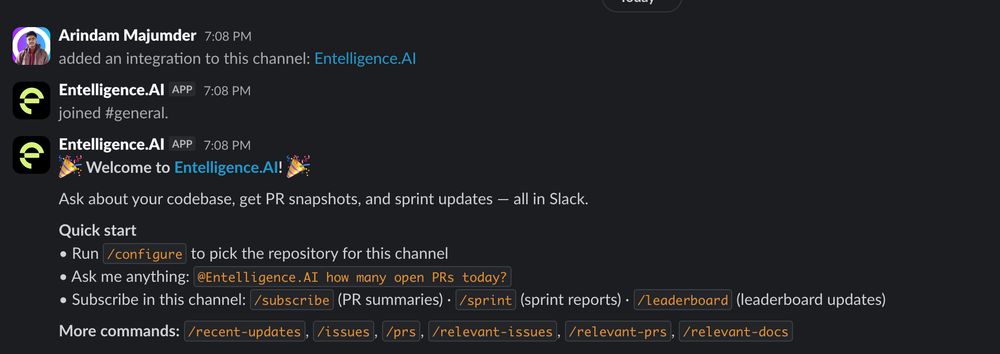
Recently started exploring @EntelligenceAI, and wow, this feature is so underrated 👀
I can instantly check:
- PR summaries
- Sprint reports
- PRs, issues, docs, and recent updates
And you can even chat with it!
All inside Slack. No tab-switching, no context loss.
I can instantly check:
- PR summaries
- Sprint reports
- PRs, issues, docs, and recent updates
And you can even chat with it!
All inside Slack. No tab-switching, no context loss.
November 17, 2025 at 1:32 PM
Recently started exploring @EntelligenceAI, and wow, this feature is so underrated 👀
I can instantly check:
- PR summaries
- Sprint reports
- PRs, issues, docs, and recent updates
And you can even chat with it!
All inside Slack. No tab-switching, no context loss.
I can instantly check:
- PR summaries
- Sprint reports
- PRs, issues, docs, and recent updates
And you can even chat with it!
All inside Slack. No tab-switching, no context loss.
Give your AWS Strands agents more focus!
With Tool Filtering in the Strands SDK, you can:
- Pick only the tools your agent really needs
- Skip unused ones to keep it fast
- Fine-tune behavior right from the SDK
Example: load just read_documentation, search_documentation, or recommend 👇
With Tool Filtering in the Strands SDK, you can:
- Pick only the tools your agent really needs
- Skip unused ones to keep it fast
- Fine-tune behavior right from the SDK
Example: load just read_documentation, search_documentation, or recommend 👇

November 15, 2025 at 12:30 PM
Give your AWS Strands agents more focus!
With Tool Filtering in the Strands SDK, you can:
- Pick only the tools your agent really needs
- Skip unused ones to keep it fast
- Fine-tune behavior right from the SDK
Example: load just read_documentation, search_documentation, or recommend 👇
With Tool Filtering in the Strands SDK, you can:
- Pick only the tools your agent really needs
- Skip unused ones to keep it fast
- Fine-tune behavior right from the SDK
Example: load just read_documentation, search_documentation, or recommend 👇
Just dropped a new guide!
Building an AI News Research Assistant with Bright Data + Vercel @aisdk
It scrapes global news, bypasses paywalls, detects bias, and gives smart summaries, all in one workflow.
Think of it as your personal AI journalist, built from scratch.
Read the full breakdown 👇
Building an AI News Research Assistant with Bright Data + Vercel @aisdk
It scrapes global news, bypasses paywalls, detects bias, and gives smart summaries, all in one workflow.
Think of it as your personal AI journalist, built from scratch.
Read the full breakdown 👇

November 14, 2025 at 12:32 PM
Just dropped a new guide!
Building an AI News Research Assistant with Bright Data + Vercel @aisdk
It scrapes global news, bypasses paywalls, detects bias, and gives smart summaries, all in one workflow.
Think of it as your personal AI journalist, built from scratch.
Read the full breakdown 👇
Building an AI News Research Assistant with Bright Data + Vercel @aisdk
It scrapes global news, bypasses paywalls, detects bias, and gives smart summaries, all in one workflow.
Think of it as your personal AI journalist, built from scratch.
Read the full breakdown 👇
November 12, 2025 at 4:28 PM
Currently Trying out Claude Code Web!
Video coming soon!
Video coming soon!
November 12, 2025 at 2:32 PM
Currently Trying out Claude Code Web!
Video coming soon!
Video coming soon!
Most agent frameworks stuff prompts or juggle vector stores.
@memorilab Memori takes a different path:
1. Dual memory (short + long term)
2. Intelligent promotion of what matters
3. Relational DBs for structure, joins, and indexing
Agents that actually remember 👇
@memorilab Memori takes a different path:
1. Dual memory (short + long term)
2. Intelligent promotion of what matters
3. Relational DBs for structure, joins, and indexing
Agents that actually remember 👇

November 12, 2025 at 12:29 PM
Most agent frameworks stuff prompts or juggle vector stores.
@memorilab Memori takes a different path:
1. Dual memory (short + long term)
2. Intelligent promotion of what matters
3. Relational DBs for structure, joins, and indexing
Agents that actually remember 👇
@memorilab Memori takes a different path:
1. Dual memory (short + long term)
2. Intelligent promotion of what matters
3. Relational DBs for structure, joins, and indexing
Agents that actually remember 👇
Ready to play with @windsurf 's Aether Alpha, Beta, and Gamma!
November 12, 2025 at 9:59 AM
Ready to play with @windsurf 's Aether Alpha, Beta, and Gamma!