




arize-phoenix
@arize-phoenix.bsky.social
Open-Source AI Observability and Evaluation
app.phoenix.arize.com
app.phoenix.arize.com
Reposted by arize-phoenix
Nvidia launched a course on building reliable agentic systems w/ NeMo Agent Toolkit (NAT)
It shows how Phoenix helps teams inspect agent reasoning, tool selection, & control flow, making NAT-based agents easier to debug, evaluate, and run in production.
Taught by @mcbrayer.bsky.social
It shows how Phoenix helps teams inspect agent reasoning, tool selection, & control flow, making NAT-based agents easier to debug, evaluate, and run in production.
Taught by @mcbrayer.bsky.social
If you're not redirected in a few seconds, click here
info.deeplearning.ai
December 22, 2025 at 7:07 PM
Nvidia launched a course on building reliable agentic systems w/ NeMo Agent Toolkit (NAT)
It shows how Phoenix helps teams inspect agent reasoning, tool selection, & control flow, making NAT-based agents easier to debug, evaluate, and run in production.
Taught by @mcbrayer.bsky.social
It shows how Phoenix helps teams inspect agent reasoning, tool selection, & control flow, making NAT-based agents easier to debug, evaluate, and run in production.
Taught by @mcbrayer.bsky.social
Nvidia launched a course on building reliable agentic systems w/ NeMo Agent Toolkit (NAT)
It shows how Phoenix helps teams inspect agent reasoning, tool selection, & control flow, making NAT-based agents easier to debug, evaluate, and run in production.
Taught by @mcbrayer.bsky.social
It shows how Phoenix helps teams inspect agent reasoning, tool selection, & control flow, making NAT-based agents easier to debug, evaluate, and run in production.
Taught by @mcbrayer.bsky.social
If you're not redirected in a few seconds, click here
info.deeplearning.ai
December 22, 2025 at 7:07 PM
Nvidia launched a course on building reliable agentic systems w/ NeMo Agent Toolkit (NAT)
It shows how Phoenix helps teams inspect agent reasoning, tool selection, & control flow, making NAT-based agents easier to debug, evaluate, and run in production.
Taught by @mcbrayer.bsky.social
It shows how Phoenix helps teams inspect agent reasoning, tool selection, & control flow, making NAT-based agents easier to debug, evaluate, and run in production.
Taught by @mcbrayer.bsky.social
🏢 Phoenix now supports on-prem LDAP authentication!
For enterprises that can't use cloud SSO, Phoenix integrates directly with your internal directory—Active Directory, OpenLDAP, or any LDAP v3 server.
Your data. Your infrastructure. Your identity provider.
For enterprises that can't use cloud SSO, Phoenix integrates directly with your internal directory—Active Directory, OpenLDAP, or any LDAP v3 server.
Your data. Your infrastructure. Your identity provider.

December 16, 2025 at 6:39 PM
🏢 Phoenix now supports on-prem LDAP authentication!
For enterprises that can't use cloud SSO, Phoenix integrates directly with your internal directory—Active Directory, OpenLDAP, or any LDAP v3 server.
Your data. Your infrastructure. Your identity provider.
For enterprises that can't use cloud SSO, Phoenix integrates directly with your internal directory—Active Directory, OpenLDAP, or any LDAP v3 server.
Your data. Your infrastructure. Your identity provider.
In our latest Evals Series webinar, we covered how to evaluate your evaluator.
AI development has two loops, Meta-evaluation lives in the inner loop.
We also walked through a live demo of this loop in practice, iteratively improving the judge and showing measurable gains at each step.
AI development has two loops, Meta-evaluation lives in the inner loop.
We also walked through a live demo of this loop in practice, iteratively improving the judge and showing measurable gains at each step.
December 12, 2025 at 7:08 PM
In our latest Evals Series webinar, we covered how to evaluate your evaluator.
AI development has two loops, Meta-evaluation lives in the inner loop.
We also walked through a live demo of this loop in practice, iteratively improving the judge and showing measurable gains at each step.
AI development has two loops, Meta-evaluation lives in the inner loop.
We also walked through a live demo of this loop in practice, iteratively improving the judge and showing measurable gains at each step.
In the coming weeks we'll be enabling basic telemetry by default in Phoenix over the coming weeks.
Our commitment: privacy and security are foundational
What we're collecting: Simple, anonymous usage stats
Opt out: Set PHOENIX_TELEMETRY_ENABLED=false—no questions asked.
github.com/Arize-ai/ph...
Our commitment: privacy and security are foundational
What we're collecting: Simple, anonymous usage stats
Opt out: Set PHOENIX_TELEMETRY_ENABLED=false—no questions asked.
github.com/Arize-ai/ph...

A Note on Telemetry in Phoenix · Arize-ai phoenix · Discussion #10572
We want to be upfront with you about an upcoming change: in the coming weeks, Phoenix will enable basic telemetry by default for self-hosted deployments. Telemetry can be a sensitive topic, and rig...
github.com
December 11, 2025 at 6:30 PM
In the coming weeks we'll be enabling basic telemetry by default in Phoenix over the coming weeks.
Our commitment: privacy and security are foundational
What we're collecting: Simple, anonymous usage stats
Opt out: Set PHOENIX_TELEMETRY_ENABLED=false—no questions asked.
github.com/Arize-ai/ph...
Our commitment: privacy and security are foundational
What we're collecting: Simple, anonymous usage stats
Opt out: Set PHOENIX_TELEMETRY_ENABLED=false—no questions asked.
github.com/Arize-ai/ph...
Phoenix Evals now supports message-based LLM-as-a-judge prompts— an upgrade that aligns evals with how modern models actually expect instructions.
🧵👇
🧵👇

December 11, 2025 at 4:37 AM
Phoenix Evals now supports message-based LLM-as-a-judge prompts— an upgrade that aligns evals with how modern models actually expect instructions.
🧵👇
🧵👇
We just shipped a Span Notes API in Phoenix 12.20.
It's a simple API, but it unlocks an important workflow for LLM evaluation: open coding. Here's why this matters.
It's a simple API, but it unlocks an important workflow for LLM evaluation: open coding. Here's why this matters.
December 10, 2025 at 6:20 AM
We just shipped a Span Notes API in Phoenix 12.20.
It's a simple API, but it unlocks an important workflow for LLM evaluation: open coding. Here's why this matters.
It's a simple API, but it unlocks an important workflow for LLM evaluation: open coding. Here's why this matters.
Check out this walkthrough on bringing observability and evals into LLM workflows, plus a Phoenix demo with helpful context for anyone building agents in TypeScript.
Watch the session below 👇
Watch the session below 👇
Spoke at @arize.bsky.social’s AI Builder Meetup a few weeks back & the talk is now live!
Covered the basics of observability + evals, and showed via a Mastra agent how to set up tracing, run evals, & start your iteration cycle.
Check it out here 🚀
www.youtube.com/watch?v=qQGQ...
Covered the basics of observability + evals, and showed via a Mastra agent how to set up tracing, run evals, & start your iteration cycle.
Check it out here 🚀
www.youtube.com/watch?v=qQGQ...
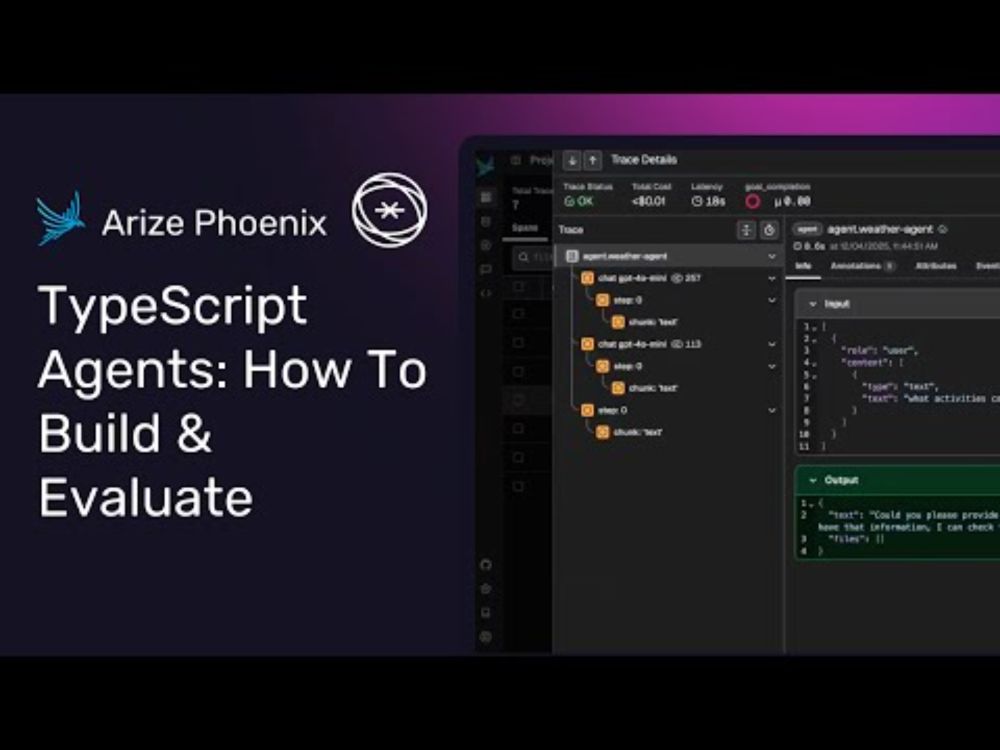
TypeScript Agents: How To Build and Evaluate
YouTube video by Arize AI
www.youtube.com
December 4, 2025 at 7:24 PM
Check out this walkthrough on bringing observability and evals into LLM workflows, plus a Phoenix demo with helpful context for anyone building agents in TypeScript.
Watch the session below 👇
Watch the session below 👇
📚 New end-to-end Phoenix tutorials for Python and TypeScript are live!
Learn the core workflows to:
1. Interpret agent traces
2. Define tasks & build datasets for experiments
3. Construct purposeful LLM evals
4. Iterate based on results to improve reliability.
Choose your language & dive in!⬇️
Learn the core workflows to:
1. Interpret agent traces
2. Define tasks & build datasets for experiments
3. Construct purposeful LLM evals
4. Iterate based on results to improve reliability.
Choose your language & dive in!⬇️

December 3, 2025 at 5:00 PM
📚 New end-to-end Phoenix tutorials for Python and TypeScript are live!
Learn the core workflows to:
1. Interpret agent traces
2. Define tasks & build datasets for experiments
3. Construct purposeful LLM evals
4. Iterate based on results to improve reliability.
Choose your language & dive in!⬇️
Learn the core workflows to:
1. Interpret agent traces
2. Define tasks & build datasets for experiments
3. Construct purposeful LLM evals
4. Iterate based on results to improve reliability.
Choose your language & dive in!⬇️
Run evals fast with our TypeScript Evals Quickstart!
The new TypeScript Evals package to be a simple & powerful way to evaluate your agents:
✅ Define a task (what the agent does)
✅ Build a dataset
✅ Use an LLM-as-a-Judge evaluator to score outputs
✅ Run evals and see results in Phoenix
Docs 👇
The new TypeScript Evals package to be a simple & powerful way to evaluate your agents:
✅ Define a task (what the agent does)
✅ Build a dataset
✅ Use an LLM-as-a-Judge evaluator to score outputs
✅ Run evals and see results in Phoenix
Docs 👇
November 26, 2025 at 5:00 PM
Run evals fast with our TypeScript Evals Quickstart!
The new TypeScript Evals package to be a simple & powerful way to evaluate your agents:
✅ Define a task (what the agent does)
✅ Build a dataset
✅ Use an LLM-as-a-Judge evaluator to score outputs
✅ Run evals and see results in Phoenix
Docs 👇
The new TypeScript Evals package to be a simple & powerful way to evaluate your agents:
✅ Define a task (what the agent does)
✅ Build a dataset
✅ Use an LLM-as-a-Judge evaluator to score outputs
✅ Run evals and see results in Phoenix
Docs 👇
🚀 New feature: Dataset Splits 🚀
Splits let you define named subsets of your dataset & filter your experiments to run only on those subsets.
Learn more & Check out this walkthrough:
⚪️ Create a split directly in the Phoenix UI
⚪️ Run an experiment scoped to that subset
👉 Full demo + code below 👇
Splits let you define named subsets of your dataset & filter your experiments to run only on those subsets.
Learn more & Check out this walkthrough:
⚪️ Create a split directly in the Phoenix UI
⚪️ Run an experiment scoped to that subset
👉 Full demo + code below 👇
Harnessing Splits in your Dataset with Arize Phoenix
YouTube video by Arize AI
youtu.be
November 25, 2025 at 7:39 PM
🚀 New feature: Dataset Splits 🚀
Splits let you define named subsets of your dataset & filter your experiments to run only on those subsets.
Learn more & Check out this walkthrough:
⚪️ Create a split directly in the Phoenix UI
⚪️ Run an experiment scoped to that subset
👉 Full demo + code below 👇
Splits let you define named subsets of your dataset & filter your experiments to run only on those subsets.
Learn more & Check out this walkthrough:
⚪️ Create a split directly in the Phoenix UI
⚪️ Run an experiment scoped to that subset
👉 Full demo + code below 👇
Dig into agent traces without a single line of code!
Our new live Phoenix Demos let you explore every step of an agent’s reasoning just by chatting with pre-built agents, with traces appearing instantly as you go.
Our new live Phoenix Demos let you explore every step of an agent’s reasoning just by chatting with pre-built agents, with traces appearing instantly as you go.
November 20, 2025 at 3:25 PM
Dig into agent traces without a single line of code!
Our new live Phoenix Demos let you explore every step of an agent’s reasoning just by chatting with pre-built agents, with traces appearing instantly as you go.
Our new live Phoenix Demos let you explore every step of an agent’s reasoning just by chatting with pre-built agents, with traces appearing instantly as you go.
New Evals for TypeScript agent builders 🔥
With Mastra now integrating directly with Phoenix, you can trace your TypeScript agents with almost zero friction.
And now… you can evaluate them too: directly from TypeScript using Phoenix Evals.
With Mastra now integrating directly with Phoenix, you can trace your TypeScript agents with almost zero friction.
And now… you can evaluate them too: directly from TypeScript using Phoenix Evals.
November 13, 2025 at 7:21 PM
New Evals for TypeScript agent builders 🔥
With Mastra now integrating directly with Phoenix, you can trace your TypeScript agents with almost zero friction.
And now… you can evaluate them too: directly from TypeScript using Phoenix Evals.
With Mastra now integrating directly with Phoenix, you can trace your TypeScript agents with almost zero friction.
And now… you can evaluate them too: directly from TypeScript using Phoenix Evals.
🌀 Since LLMs are probabilistic, their synthesis can differ even when the supplied prompts are exactly the same. This can make it challenging to determine if a particular change is warranted as a single execution cannot concretely tell you whether a given change improves or degrades your task.
September 26, 2025 at 11:48 PM
🌀 Since LLMs are probabilistic, their synthesis can differ even when the supplied prompts are exactly the same. This can make it challenging to determine if a particular change is warranted as a single execution cannot concretely tell you whether a given change improves or degrades your task.
Reposted by arize-phoenix

In the latest release of Arconia, I included support for the OpenInference Semantic Conventions for instrumenting your @spring-ai.bsky.social apps and integrating with AI platforms like @arize-phoenix.bsky.social, now available as an Arconia Dev Service for Spring Boot. arconia.io/docs/arconia...

September 8, 2025 at 11:55 PM
In the latest release of Arconia, I included support for the OpenInference Semantic Conventions for instrumenting your @spring-ai.bsky.social apps and integrating with AI platforms like @arize-phoenix.bsky.social, now available as an Arconia Dev Service for Spring Boot. arconia.io/docs/arconia...
Reposted by arize-phoenix

Arize AI
app.arize.com
June 27, 2025 at 10:34 PM
Reposted by arize-phoenix
Missed the news from Arize Observe 2025? Phoenix Cloud just got Spaces & Access Management!
✨ Create tailored Spaces
🔑 Manage user permissions
👥 Easy team collaboration
More than a feature, it’s Phoenix adapting to you.
Spin up a new Phoenix project & test it out!
@arize-phoenix.bsky.social
✨ Create tailored Spaces
🔑 Manage user permissions
👥 Easy team collaboration
More than a feature, it’s Phoenix adapting to you.
Spin up a new Phoenix project & test it out!
@arize-phoenix.bsky.social

June 27, 2025 at 10:34 PM
Missed the news from Arize Observe 2025? Phoenix Cloud just got Spaces & Access Management!
✨ Create tailored Spaces
🔑 Manage user permissions
👥 Easy team collaboration
More than a feature, it’s Phoenix adapting to you.
Spin up a new Phoenix project & test it out!
@arize-phoenix.bsky.social
✨ Create tailored Spaces
🔑 Manage user permissions
👥 Easy team collaboration
More than a feature, it’s Phoenix adapting to you.
Spin up a new Phoenix project & test it out!
@arize-phoenix.bsky.social
Reposted by arize-phoenix

🧪 📊 The @arize-phoenix.bsky.social TS/JS client now supports Experiments and Datasets!
You can now create datasets, run experiments, and attach evaluations to experiments using the Phoenix TS/JS client.
Shoutout to @anthonypowell.me and @mikeldking.bsky.social for the work here!
You can now create datasets, run experiments, and attach evaluations to experiments using the Phoenix TS/JS client.
Shoutout to @anthonypowell.me and @mikeldking.bsky.social for the work here!



May 21, 2025 at 2:26 PM
🧪 📊 The @arize-phoenix.bsky.social TS/JS client now supports Experiments and Datasets!
You can now create datasets, run experiments, and attach evaluations to experiments using the Phoenix TS/JS client.
Shoutout to @anthonypowell.me and @mikeldking.bsky.social for the work here!
You can now create datasets, run experiments, and attach evaluations to experiments using the Phoenix TS/JS client.
Shoutout to @anthonypowell.me and @mikeldking.bsky.social for the work here!
Reposted by arize-phoenix

Reposted by arize-phoenix
🆕 New in OpenInference: Python auto-instrumentation for the Google GenAI SDK!
Add GenAI tracing to your @arize-phoenix.bsky.social applications in just a few lines. Works great with Span Replay so you can debug, tweak, and explore agent behavior in prompt playground.
Check Notebook + docs below!👇
Add GenAI tracing to your @arize-phoenix.bsky.social applications in just a few lines. Works great with Span Replay so you can debug, tweak, and explore agent behavior in prompt playground.
Check Notebook + docs below!👇

May 8, 2025 at 8:41 PM
🆕 New in OpenInference: Python auto-instrumentation for the Google GenAI SDK!
Add GenAI tracing to your @arize-phoenix.bsky.social applications in just a few lines. Works great with Span Replay so you can debug, tweak, and explore agent behavior in prompt playground.
Check Notebook + docs below!👇
Add GenAI tracing to your @arize-phoenix.bsky.social applications in just a few lines. Works great with Span Replay so you can debug, tweak, and explore agent behavior in prompt playground.
Check Notebook + docs below!👇
Reposted by arize-phoenix

Learn to prompt better

May 7, 2025 at 7:26 PM
Learn to prompt better
Reposted by arize-phoenix
@pydantic.dev evals 🤝 @arize-phoenix.bsky.social tracing and UI
I’ve been really liking some of the eval tools from Pydantic's evals package.
Wanted to see if I could combine these with Phoenix’s tracing so I could run Pydantic evals on traces captured in Phoenix
I’ve been really liking some of the eval tools from Pydantic's evals package.
Wanted to see if I could combine these with Phoenix’s tracing so I could run Pydantic evals on traces captured in Phoenix


May 2, 2025 at 6:02 PM
@pydantic.dev evals 🤝 @arize-phoenix.bsky.social tracing and UI
I’ve been really liking some of the eval tools from Pydantic's evals package.
Wanted to see if I could combine these with Phoenix’s tracing so I could run Pydantic evals on traces captured in Phoenix
I’ve been really liking some of the eval tools from Pydantic's evals package.
Wanted to see if I could combine these with Phoenix’s tracing so I could run Pydantic evals on traces captured in Phoenix
Reposted by arize-phoenix
Check out the full video: youtu.be/iOGu7-HYm6s?...
Tracing and Evaluating OpenAI Agents
YouTube video by Arize AI
youtu.be
April 18, 2025 at 6:51 PM
Check out the full video: youtu.be/iOGu7-HYm6s?...
Reposted by arize-phoenix
Just dropped a tutorial on using the OpenAI Agents SDK + @arize-phoenix.bsky.social to go from building to evaluating agents.
✔️ Trace agent decisions at every step
✔️ Offline and Online Evals using LLM as a Judge
If you're building agents, measuring them is essential.
Full vid and cookbook below
✔️ Trace agent decisions at every step
✔️ Offline and Online Evals using LLM as a Judge
If you're building agents, measuring them is essential.
Full vid and cookbook below

April 18, 2025 at 6:51 PM
Just dropped a tutorial on using the OpenAI Agents SDK + @arize-phoenix.bsky.social to go from building to evaluating agents.
✔️ Trace agent decisions at every step
✔️ Offline and Online Evals using LLM as a Judge
If you're building agents, measuring them is essential.
Full vid and cookbook below
✔️ Trace agent decisions at every step
✔️ Offline and Online Evals using LLM as a Judge
If you're building agents, measuring them is essential.
Full vid and cookbook below
Reposted by arize-phoenix
We've added new LLM decorators to @arize-phoenix.bsky.social 's OpenInference library 🎁
Tag a function with `@ tracer.llm` to automatically capture it as an @opentelemetry.io span.
- Automatically parses input and output messages
- Comes in decorator or context manager flavors
Tag a function with `@ tracer.llm` to automatically capture it as an @opentelemetry.io span.
- Automatically parses input and output messages
- Comes in decorator or context manager flavors


April 18, 2025 at 2:21 AM
We've added new LLM decorators to @arize-phoenix.bsky.social 's OpenInference library 🎁
Tag a function with `@ tracer.llm` to automatically capture it as an @opentelemetry.io span.
- Automatically parses input and output messages
- Comes in decorator or context manager flavors
Tag a function with `@ tracer.llm` to automatically capture it as an @opentelemetry.io span.
- Automatically parses input and output messages
- Comes in decorator or context manager flavors