



Arthur Clune
@arthur.clune.org
Geek. Likes bikes, climbing and tech
Work: IT at University of Sheffield
Work: IT at University of Sheffield
While reading Simon Couch's blog I came across this post from December on evaluating open models' ability to complete a simple code refactor in R. It's a much bigger gap than I expected. He's limiting to model's than can run locally, hence the small size, but even Haiku totally outclasses gpt-oss

January 21, 2026 at 8:54 AM
While reading Simon Couch's blog I came across this post from December on evaluating open models' ability to complete a simple code refactor in R. It's a much bigger gap than I expected. He's limiting to model's than can run locally, hence the small size, but even Haiku totally outclasses gpt-oss
Demonstration of exploit development against a (small but not toy) JavaScript interpreter. Two things I noticed:
1) Increase tokens by the use of parallel runs on the same task (like how METR do their evals)
2) Author doesn’t say how he got round guardrails.
sean.heelan.io/2026/01/18/o...
1) Increase tokens by the use of parallel runs on the same task (like how METR do their evals)
2) Author doesn’t say how he got round guardrails.
sean.heelan.io/2026/01/18/o...

January 19, 2026 at 8:36 AM
Demonstration of exploit development against a (small but not toy) JavaScript interpreter. Two things I noticed:
1) Increase tokens by the use of parallel runs on the same task (like how METR do their evals)
2) Author doesn’t say how he got round guardrails.
sean.heelan.io/2026/01/18/o...
1) Increase tokens by the use of parallel runs on the same task (like how METR do their evals)
2) Author doesn’t say how he got round guardrails.
sean.heelan.io/2026/01/18/o...

January 11, 2026 at 7:45 AM
This is a terrible take from @theguardian.com
Grok hasn’t done this. X has done this to grok. And specifically Musk.
www.theguardian.com/technology/2...
Grok hasn’t done this. X has done this to grok. And specifically Musk.
www.theguardian.com/technology/2...

January 9, 2026 at 7:54 AM
This is a terrible take from @theguardian.com
Grok hasn’t done this. X has done this to grok. And specifically Musk.
www.theguardian.com/technology/2...
Grok hasn’t done this. X has done this to grok. And specifically Musk.
www.theguardian.com/technology/2...
Consider these ideas for future uses and re-cast them a little.
'Your DA monitors 47 nearby targets. It alerts you about the woman going into a darker section' or 'Your son has been looking at LGBT content. Want me to book him into a conversion camp?'
2/
'Your DA monitors 47 nearby targets. It alerts you about the woman going into a darker section' or 'Your son has been looking at LGBT content. Want me to book him into a conversion camp?'
2/


January 6, 2026 at 12:53 PM
Consider these ideas for future uses and re-cast them a little.
'Your DA monitors 47 nearby targets. It alerts you about the woman going into a darker section' or 'Your son has been looking at LGBT content. Want me to book him into a conversion camp?'
2/
'Your DA monitors 47 nearby targets. It alerts you about the woman going into a darker section' or 'Your son has been looking at LGBT content. Want me to book him into a conversion camp?'
2/
And by chance here’s what your post ended up next to. Letters of Marque next?

December 21, 2025 at 8:14 PM
And by chance here’s what your post ended up next to. Letters of Marque next?
LLMs' productivity boost is an exponent not a multipler - from @ed3d.net
This framing partially resonates. I'm less keen on starting skill level as the key (on which axis do we measure etc), but because if LLM competency is the variable and the exponent, then learned skill matters so much more
This framing partially resonates. I'm less keen on starting skill level as the key (on which axis do we measure etc), but because if LLM competency is the variable and the exponent, then learned skill matters so much more


December 21, 2025 at 5:16 PM
LLMs' productivity boost is an exponent not a multipler - from @ed3d.net
This framing partially resonates. I'm less keen on starting skill level as the key (on which axis do we measure etc), but because if LLM competency is the variable and the exponent, then learned skill matters so much more
This framing partially resonates. I'm less keen on starting skill level as the key (on which axis do we measure etc), but because if LLM competency is the variable and the exponent, then learned skill matters so much more
So Substack are, as long predicted, starting to slowly move away from email. This 'warning' means the message is truncated *by the sender* with a 'continue reading on substack' button even though my mail client can read long messages just fine

December 11, 2025 at 10:39 AM
So Substack are, as long predicted, starting to slowly move away from email. This 'warning' means the message is truncated *by the sender* with a 'continue reading on substack' button even though my mail client can read long messages just fine
This is an interesting read but I think the author misses the main use case that will drive spend. Military robots are going to be a massive investment.
I don’t think this is a good thing, but it seems clear that it’s the way it’s going
I don’t think this is a good thing, but it seems clear that it’s the way it’s going

December 11, 2025 at 8:45 AM
This is an interesting read but I think the author misses the main use case that will drive spend. Military robots are going to be a massive investment.
I don’t think this is a good thing, but it seems clear that it’s the way it’s going
I don’t think this is a good thing, but it seems clear that it’s the way it’s going
I raise you this one from Frontiers of Cell Biology. There's basically a whole industry of 'special issues' that print anything if you pay

November 28, 2025 at 12:36 PM
I raise you this one from Frontiers of Cell Biology. There's basically a whole industry of 'special issues' that print anything if you pay
More on Gemini 3 and reading historical documents. With a line to make Gary Marcus hop.
Google does seem to be proving that just scaling LLMs is still working
generativehistory.substack.com/p/the-sugar-...
Google does seem to be proving that just scaling LLMs is still working
generativehistory.substack.com/p/the-sugar-...

November 18, 2025 at 8:15 PM
More on Gemini 3 and reading historical documents. With a line to make Gary Marcus hop.
Google does seem to be proving that just scaling LLMs is still working
generativehistory.substack.com/p/the-sugar-...
Google does seem to be proving that just scaling LLMs is still working
generativehistory.substack.com/p/the-sugar-...
If this analysis from EpochAI is correct then
a) model training costs (financial and environmental) are ~5-10x the final run and
b) inference costs (financial and environmental) are smaller than assumed
I'm making heroic assumptions for a). No-one outside OpenAI can answer properly
a) model training costs (financial and environmental) are ~5-10x the final run and
b) inference costs (financial and environmental) are smaller than assumed
I'm making heroic assumptions for a). No-one outside OpenAI can answer properly

November 18, 2025 at 9:32 AM
If this analysis from EpochAI is correct then
a) model training costs (financial and environmental) are ~5-10x the final run and
b) inference costs (financial and environmental) are smaller than assumed
I'm making heroic assumptions for a). No-one outside OpenAI can answer properly
a) model training costs (financial and environmental) are ~5-10x the final run and
b) inference costs (financial and environmental) are smaller than assumed
I'm making heroic assumptions for a). No-one outside OpenAI can answer properly
Age yourself with gaming

November 12, 2025 at 6:48 PM
Age yourself with gaming
Big hint in their write up that they weren't using Cursor to write code

October 30, 2025 at 5:22 PM
Big hint in their write up that they weren't using Cursor to write code

October 14, 2025 at 7:13 AM

I'm writing a chatbot as an experiment. Here's Claude Code debugging why the tool calling isn't working
Spoiler - this was not the reason!
Spoiler - this was not the reason!

September 1, 2025 at 1:58 PM
I'm writing a chatbot as an experiment. Here's Claude Code debugging why the tool calling isn't working
Spoiler - this was not the reason!
Spoiler - this was not the reason!

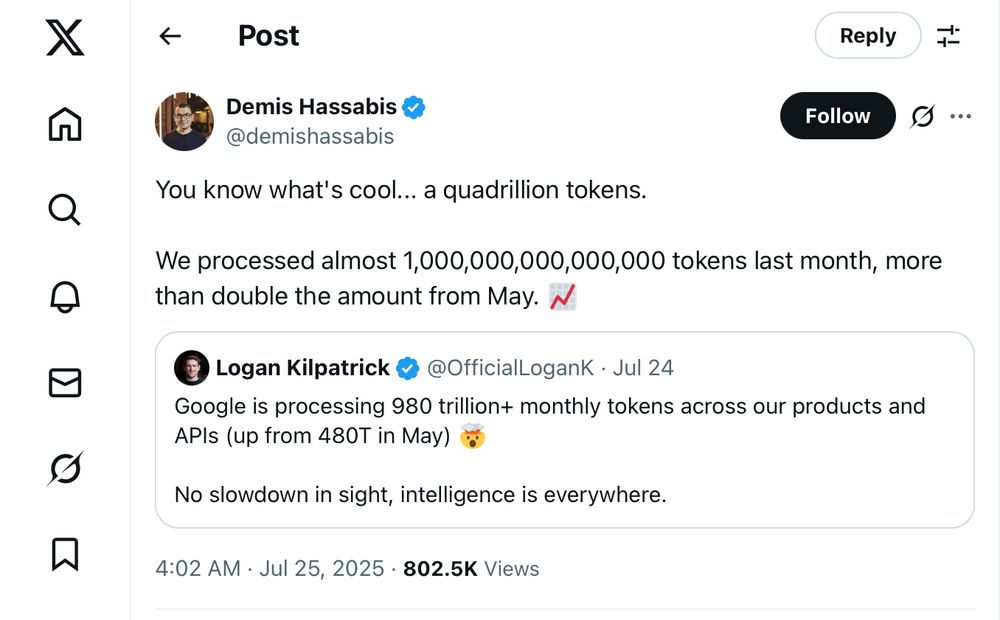
Numbers from Google on tokens. Doubling every month. 1,000tn in June.
July 31, 2025 at 4:15 PM
Numbers from Google on tokens. Doubling every month. 1,000tn in June.
It's here. Sigh. Age ID for DMs

July 23, 2025 at 9:41 PM
It's here. Sigh. Age ID for DMs
Fortunately the “learn more about our brand” page explains everything

July 22, 2025 at 12:40 PM
Fortunately the “learn more about our brand” page explains everything
I read this from the OfS as saying that nearly 20% of UK Unis are at risk of going under
(from the @resprofnews.bsky.social newsletter)
(from the @resprofnews.bsky.social newsletter)

July 21, 2025 at 9:37 AM
I read this from the OfS as saying that nearly 20% of UK Unis are at risk of going under
(from the @resprofnews.bsky.social newsletter)
(from the @resprofnews.bsky.social newsletter)
It's a cool idea for sure. But why is it surprising? There's plenty in that trace for a human to understand what it does. I assume that it scales well beyond the toy examples into something that needs a lot more reasoning?


July 19, 2025 at 1:12 PM
It's a cool idea for sure. But why is it surprising? There's plenty in that trace for a human to understand what it does. I assume that it scales well beyond the toy examples into something that needs a lot more reasoning?
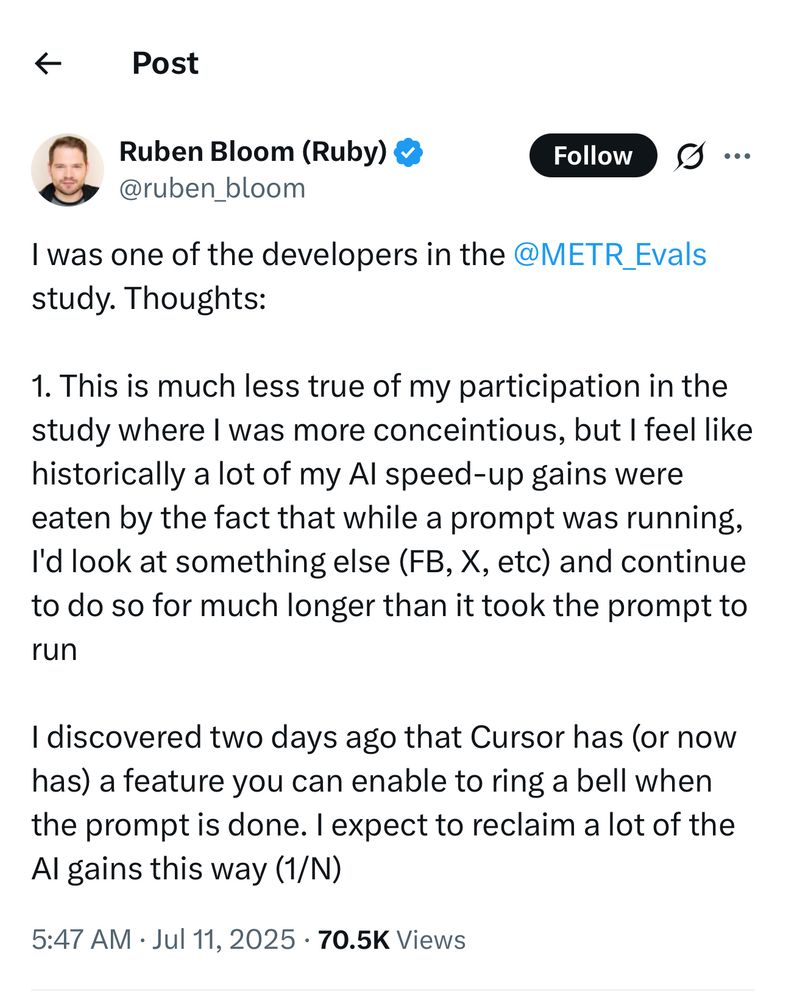
And here’s a quote from one of the developers in the study. This is very relatable!
x.com/ruben_bloom/...
x.com/ruben_bloom/...
July 15, 2025 at 6:50 AM
And here’s a quote from one of the developers in the study. This is very relatable!
x.com/ruben_bloom/...
x.com/ruben_bloom/...
There's some eye-opening things in the Observer's Sensemaker email today about the ONS
observer.co.uk/newsletters
It also appears it may be another instance of problems of governance and leaders who don't listen
archive.is/lvPkk
And yes, Newport is not attractive and doesn't help
observer.co.uk/newsletters
It also appears it may be another instance of problems of governance and leaders who don't listen
archive.is/lvPkk
And yes, Newport is not attractive and doesn't help


July 11, 2025 at 9:42 AM
There's some eye-opening things in the Observer's Sensemaker email today about the ONS
observer.co.uk/newsletters
It also appears it may be another instance of problems of governance and leaders who don't listen
archive.is/lvPkk
And yes, Newport is not attractive and doesn't help
observer.co.uk/newsletters
It also appears it may be another instance of problems of governance and leaders who don't listen
archive.is/lvPkk
And yes, Newport is not attractive and doesn't help