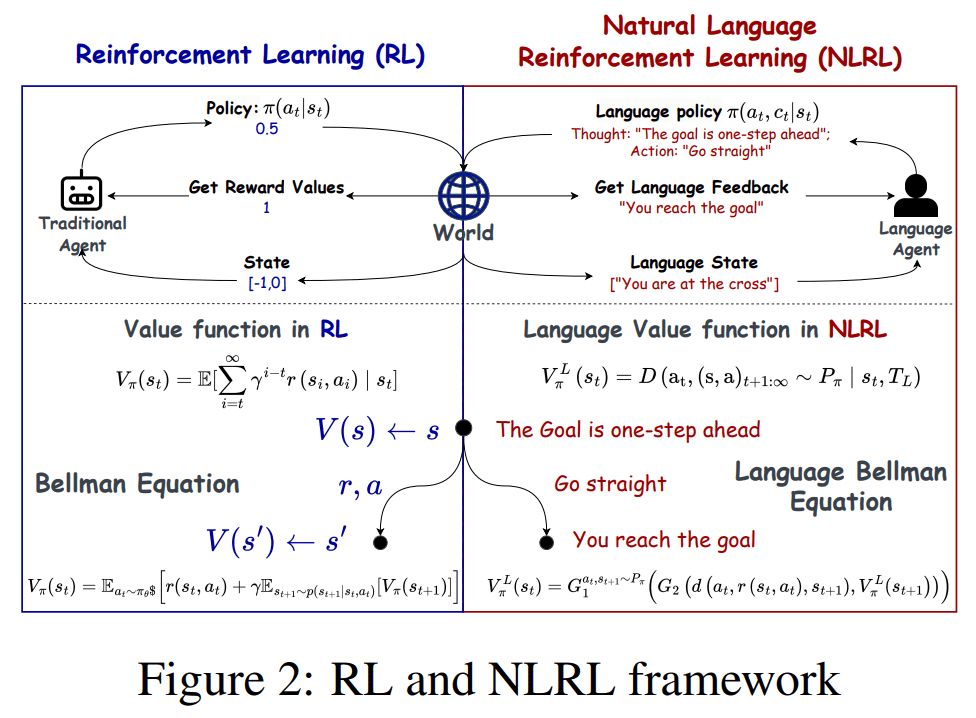
Bo Liu (Benjamin Liu)
@benjamin-eecs.bsky.social
110 followers
21 following
8 posts
Reinforcement Learning PhD @NUSingapore | Undergrad @PKU1898 | Building autonomous decision making systems | Ex intern @MSFTResearch @deepseek_ai | DeepSeek-V2, DeepSeek-VL, DeepSeek-Prover
Posts
Media
Videos
Starter Packs
Pinned
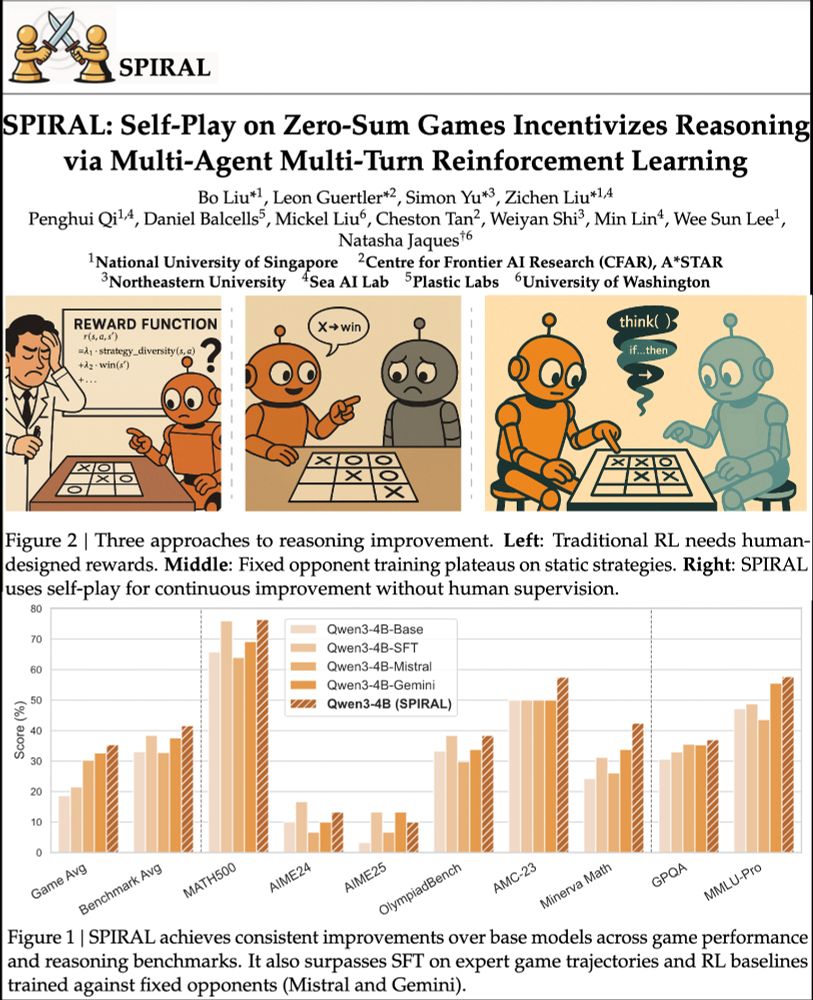
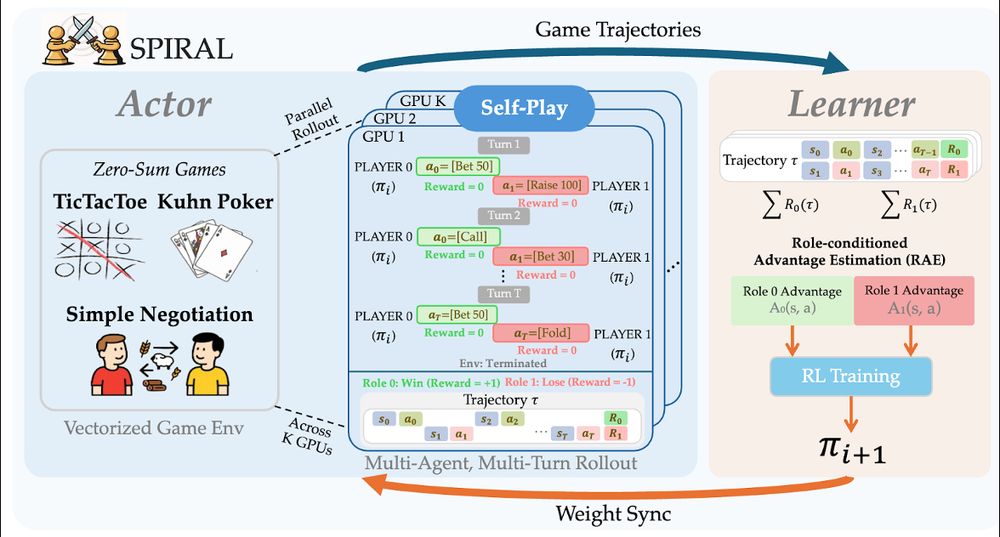
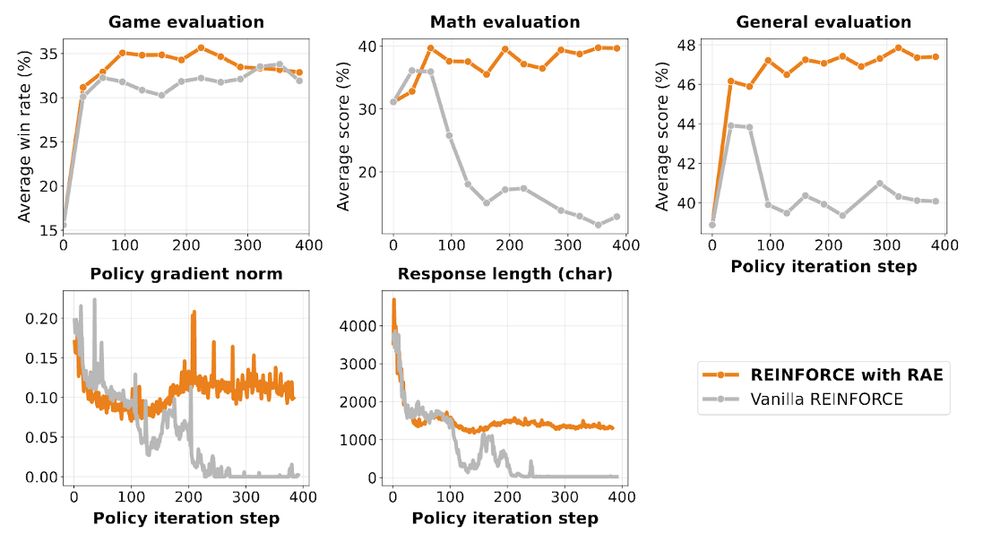

Reposted by Bo Liu (Benjamin Liu)