Andreas Kirsch
@blackhc.bsky.social
4.3K followers
2K following
130 posts
My opinions only here.
👨🔬 RS DeepMind
Past:
👨🔬 R Midjourney 1y 🧑🎓 DPhil AIMS Uni of Oxford 4.5y
🧙♂️ RE DeepMind 1y 📺 SWE Google 3y 🎓 TUM
👤 @nwspk
Posts
Media
Videos
Starter Packs
Pinned

Andreas Kirsch
@blackhc.bsky.social
· Jan 7

Andreas Kirsch
@blackhc.bsky.social
· Jun 29

Andreas Kirsch
@blackhc.bsky.social
· Jun 28
Andreas Kirsch
@blackhc.bsky.social
· Jun 28
Andreas Kirsch
@blackhc.bsky.social
· Jun 13
Reposted by Andreas Kirsch

Reposted by Andreas Kirsch

Ted Underwood
@tedunderwood.com
· Jun 11

SE Gyges
@segyges.bsky.social
· Jun 11

Institutional Books 1.0: A 242B token dataset from Harvard Library's collections, refined for accuracy and usability
Large language models (LLMs) use data to learn about the world in order to produce meaningful correlations and predictions. As such, the nature, scale, quality, and diversity of the datasets used to t...
arxiv.org
Andreas Kirsch
@blackhc.bsky.social
· Jun 11
Andreas Kirsch
@blackhc.bsky.social
· Jun 11
Andreas Kirsch
@blackhc.bsky.social
· Jun 11
Andreas Kirsch
@blackhc.bsky.social
· Jun 9
Andreas Kirsch
@blackhc.bsky.social
· Jun 9


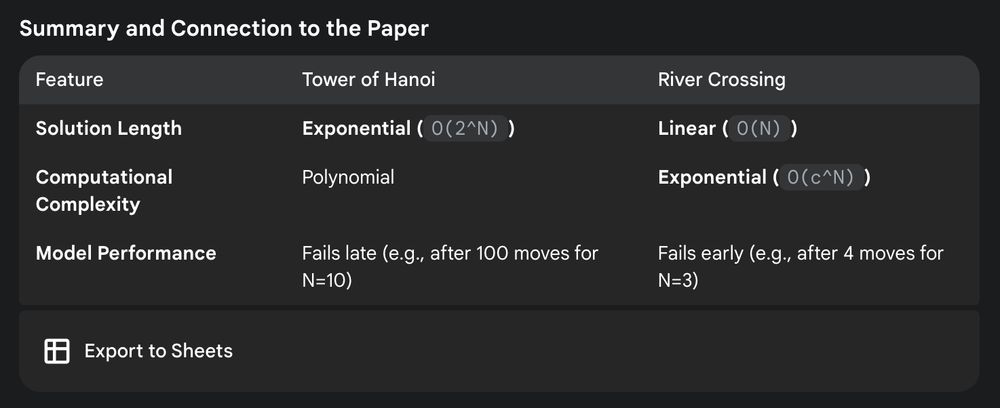
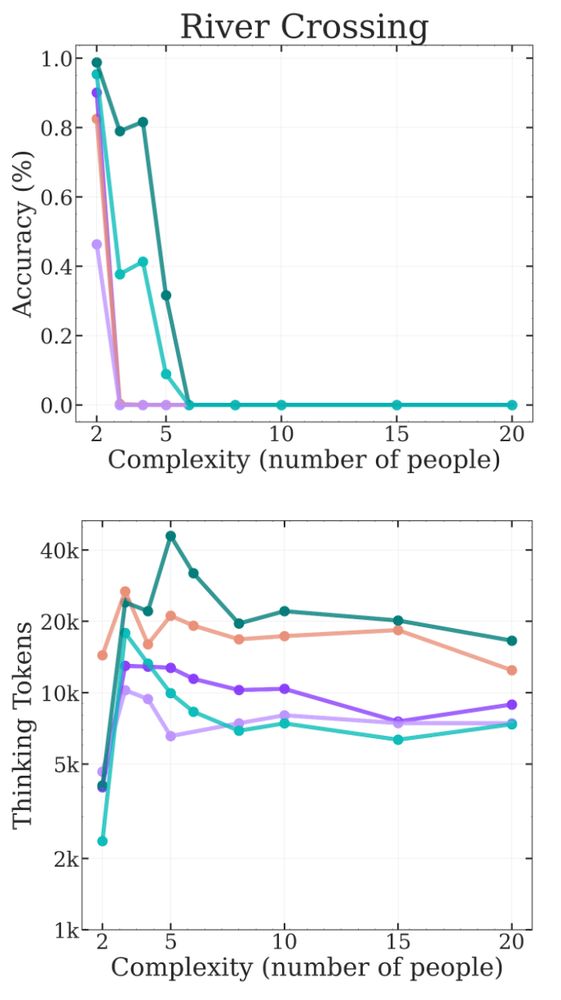
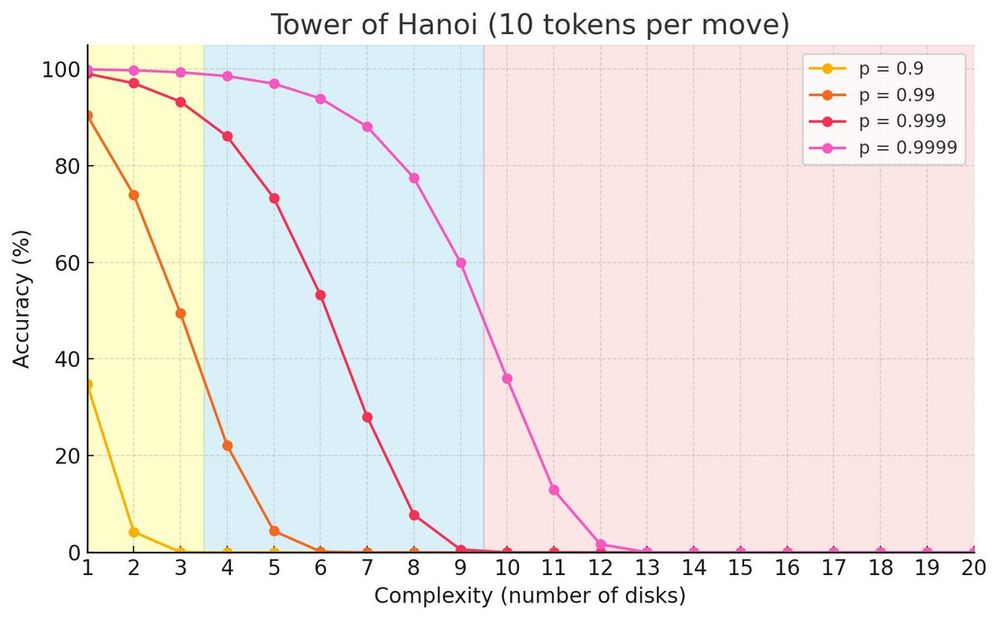
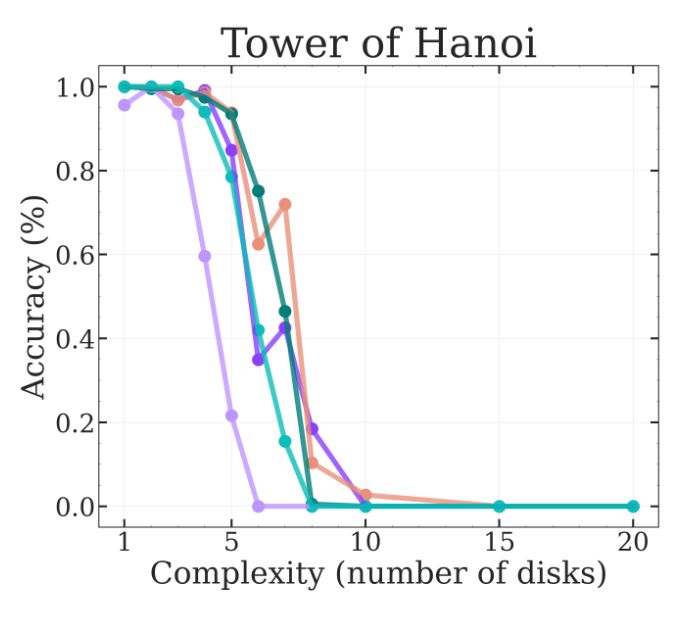
Andreas Kirsch
@blackhc.bsky.social
· Jun 9
Andreas Kirsch
@blackhc.bsky.social
· Jun 9
Andreas Kirsch
@blackhc.bsky.social
· Jun 9
Andreas Kirsch
@blackhc.bsky.social
· Jun 9
Andreas Kirsch
@blackhc.bsky.social
· Jun 9
Andreas Kirsch
@blackhc.bsky.social
· Jun 9
Andreas Kirsch
@blackhc.bsky.social
· Jun 9