



Blas M. Benito
@blasbenito.com
🌍 Spatial Data Scientist | Team Lead | 🌱 AgTech | PhD in Computational Ecology + MSc in GIS
#rstats developer | geospatial engineering | soil microbiome and crop health mapping | product development
https://github.com/BlasBenito - www.blasbenito.com
#rstats developer | geospatial engineering | soil microbiome and crop health mapping | product development
https://github.com/BlasBenito - www.blasbenito.com
In the context of spatialRF, thinning is used to define the centers of contiguous training folds used in spatial cross-validation (shown as blue dots in the figure).
These ensure that the training data represents the spatial correlation structure of the full dataset.
These ensure that the training data represents the spatial correlation structure of the full dataset.

January 11, 2026 at 9:42 AM
In the context of spatialRF, thinning is used to define the centers of contiguous training folds used in spatial cross-validation (shown as blue dots in the figure).
These ensure that the training data represents the spatial correlation structure of the full dataset.
These ensure that the training data represents the spatial correlation structure of the full dataset.
In case "thinning" doesn't ring a bell:
spatialRF::thinning() controls spatial clustering in point data to mitigate spatial autocorrelation and sampling bias.
The ugly figure shows the before and after of an extreme thinning run with a distance of 5 degrees on a global dataset with 30k points.
spatialRF::thinning() controls spatial clustering in point data to mitigate spatial autocorrelation and sampling bias.
The ugly figure shows the before and after of an extreme thinning run with a distance of 5 degrees on a global dataset with 30k points.

January 11, 2026 at 9:17 AM
In case "thinning" doesn't ring a bell:
spatialRF::thinning() controls spatial clustering in point data to mitigate spatial autocorrelation and sampling bias.
The ugly figure shows the before and after of an extreme thinning run with a distance of 5 degrees on a global dataset with 30k points.
spatialRF::thinning() controls spatial clustering in point data to mitigate spatial autocorrelation and sampling bias.
The ugly figure shows the before and after of an extreme thinning run with a distance of 5 degrees on a global dataset with 30k points.
I've been optimizing an #rstats function, as one usually does at 7AM on Sunday.
The benchmark uses 30k points to compare spatialRF::thinning() (plain R), its C++ version, and an optimized C++ algorithm using spatial indexing.
Result: ~500x speed-up 🚀
Additional outcome: I didn't waste my morning!
The benchmark uses 30k points to compare spatialRF::thinning() (plain R), its C++ version, and an optimized C++ algorithm using spatial indexing.
Result: ~500x speed-up 🚀
Additional outcome: I didn't waste my morning!

January 11, 2026 at 8:50 AM
I've been optimizing an #rstats function, as one usually does at 7AM on Sunday.
The benchmark uses 30k points to compare spatialRF::thinning() (plain R), its C++ version, and an optimized C++ algorithm using spatial indexing.
Result: ~500x speed-up 🚀
Additional outcome: I didn't waste my morning!
The benchmark uses 30k points to compare spatialRF::thinning() (plain R), its C++ version, and an optimized C++ algorithm using spatial indexing.
Result: ~500x speed-up 🚀
Additional outcome: I didn't waste my morning!
Claude Code running several independent agents (each one with their own context) in parallel to fix small bugs throughout a full #rstats package.
This feature sounded like scifi BS to me just weeks ago.
This feature sounded like scifi BS to me just weeks ago.


December 30, 2025 at 8:17 PM
Claude Code running several independent agents (each one with their own context) in parallel to fix small bugs throughout a full #rstats package.
This feature sounded like scifi BS to me just weeks ago.
This feature sounded like scifi BS to me just weeks ago.
At first I thought that having more than one instance of Claude Code running on the same codebase was a bit silly, but here we are.

December 30, 2025 at 11:37 AM
At first I thought that having more than one instance of Claude Code running on the same codebase was a bit silly, but here we are.
Another one bites the dust.
The agrometeorological dataset AgERA5 (URL: cds.climate.copernicus.eu/datasets/sis...) goes off technical support.
The agrometeorological dataset AgERA5 (URL: cds.climate.copernicus.eu/datasets/sis...) goes off technical support.

December 10, 2025 at 10:19 AM
Another one bites the dust.
The agrometeorological dataset AgERA5 (URL: cds.climate.copernicus.eu/datasets/sis...) goes off technical support.
The agrometeorological dataset AgERA5 (URL: cds.climate.copernicus.eu/datasets/sis...) goes off technical support.
4/5 tidymodels integration 🧩
The new function step_collinear() lets you add multicollinearity filtering directly into your {recipes} pipelines.
This integration omits target-encoding, as it doesn’t fit well with how recipes work.
The new function step_collinear() lets you add multicollinearity filtering directly into your {recipes} pipelines.
This integration omits target-encoding, as it doesn’t fit well with how recipes work.

December 9, 2025 at 8:04 AM
4/5 tidymodels integration 🧩
The new function step_collinear() lets you add multicollinearity filtering directly into your {recipes} pipelines.
This integration omits target-encoding, as it doesn’t fit well with how recipes work.
The new function step_collinear() lets you add multicollinearity filtering directly into your {recipes} pipelines.
This integration omits target-encoding, as it doesn’t fit well with how recipes work.
3/5 Enriched output 🚀
The output of collinear() now takes you from raw data to model-ready output:
✅ Filtered data frame
✅ Ranking of predictors resulting from preference_order()
✅ Names of the selected predictors
✅ Model formulas to kickstart exploratory modelling.
The output of collinear() now takes you from raw data to model-ready output:
✅ Filtered data frame
✅ Ranking of predictors resulting from preference_order()
✅ Names of the selected predictors
✅ Model formulas to kickstart exploratory modelling.

December 9, 2025 at 8:04 AM
3/5 Enriched output 🚀
The output of collinear() now takes you from raw data to model-ready output:
✅ Filtered data frame
✅ Ranking of predictors resulting from preference_order()
✅ Names of the selected predictors
✅ Model formulas to kickstart exploratory modelling.
The output of collinear() now takes you from raw data to model-ready output:
✅ Filtered data frame
✅ Ranking of predictors resulting from preference_order()
✅ Names of the selected predictors
✅ Model formulas to kickstart exploratory modelling.
2/5 Adaptive thresholds 📈
By default, {collinear} analyzes the data's correlation structure to configure multicollinearity thresholds automatically.
Learn more here: blasbenito.github.io/collinear/ar...
By default, {collinear} analyzes the data's correlation structure to configure multicollinearity thresholds automatically.
Learn more here: blasbenito.github.io/collinear/ar...

December 9, 2025 at 8:04 AM
2/5 Adaptive thresholds 📈
By default, {collinear} analyzes the data's correlation structure to configure multicollinearity thresholds automatically.
Learn more here: blasbenito.github.io/collinear/ar...
By default, {collinear} analyzes the data's correlation structure to configure multicollinearity thresholds automatically.
Learn more here: blasbenito.github.io/collinear/ar...
Here is my honest comment about this: LOL

November 20, 2025 at 1:39 PM
Here is my honest comment about this: LOL
Version 3.0 of the #rstats package {collinear} (coming soon) has a comprehensive test suite (~800 tests, >96% coverage).
Writing it was a long and rather boring effort (no LLMs were harmed), but it's helping me catch internal inconsistencies and quickly identify the splash area of new features.
Writing it was a long and rather boring effort (no LLMs were harmed), but it's helping me catch internal inconsistencies and quickly identify the splash area of new features.

November 17, 2025 at 9:15 AM
Version 3.0 of the #rstats package {collinear} (coming soon) has a comprehensive test suite (~800 tests, >96% coverage).
Writing it was a long and rather boring effort (no LLMs were harmed), but it's helping me catch internal inconsistencies and quickly identify the splash area of new features.
Writing it was a long and rather boring effort (no LLMs were harmed), but it's helping me catch internal inconsistencies and quickly identify the splash area of new features.
From the same job advert: ZERO applicants

November 14, 2025 at 11:37 AM
From the same job advert: ZERO applicants
Somebody asked "how can we enshittify the shit out of the job market?" and someone else came out with this:

November 14, 2025 at 11:35 AM
Somebody asked "how can we enshittify the shit out of the job market?" and someone else came out with this:
I’ve been writing R since 2008 and somehow NEVER noticed that functions can literally call themselves in some sort of evil self-recursion.
I don't remember ever seeing this thing in the wild!
#rstats
I don't remember ever seeing this thing in the wild!
#rstats

November 6, 2025 at 11:36 AM
I’ve been writing R since 2008 and somehow NEVER noticed that functions can literally call themselves in some sort of evil self-recursion.
I don't remember ever seeing this thing in the wild!
#rstats
I don't remember ever seeing this thing in the wild!
#rstats
On the other hand, the R package {collinear} (URL: blasbenito.github.io/collinear/) saw an increase in downloads after release 2.0, a version with no breaking changes.
Version 3.0 is coming soon, with a few significant improvements and some changes, so we'll see how things go after that.
#rstats
Version 3.0 is coming soon, with a few significant improvements and some changes, so we'll see how things go after that.
#rstats

November 1, 2025 at 8:55 AM
On the other hand, the R package {collinear} (URL: blasbenito.github.io/collinear/) saw an increase in downloads after release 2.0, a version with no breaking changes.
Version 3.0 is coming soon, with a few significant improvements and some changes, so we'll see how things go after that.
#rstats
Version 3.0 is coming soon, with a few significant improvements and some changes, so we'll see how things go after that.
#rstats
The download history of the R package {distantia} (URL: blasbenito.github.io/distantia/) isn't half bad for such a niche tool!
There is a clear drop after releasing v2.0 in Jan 2025, but I get it: this was a full rewrite with no backward compatibility.
Breaking changes break trust!
#rstats
There is a clear drop after releasing v2.0 in Jan 2025, but I get it: this was a full rewrite with no backward compatibility.
Breaking changes break trust!
#rstats

November 1, 2025 at 7:58 AM
The download history of the R package {distantia} (URL: blasbenito.github.io/distantia/) isn't half bad for such a niche tool!
There is a clear drop after releasing v2.0 in Jan 2025, but I get it: this was a full rewrite with no backward compatibility.
Breaking changes break trust!
#rstats
There is a clear drop after releasing v2.0 in Jan 2025, but I get it: this was a full rewrite with no backward compatibility.
Breaking changes break trust!
#rstats

Equivalence between pairwise correlation and VIF in multicollinearity filtering.
Experiment:
- Subset df (30k rows, 249 cols) to random dimensions.
- Filter using a random max correlation.
- Find VIF producing the most similar result to the step above.
- Repeat 10k times.
#rstats 📦 {collinear}
Experiment:
- Subset df (30k rows, 249 cols) to random dimensions.
- Filter using a random max correlation.
- Find VIF producing the most similar result to the step above.
- Repeat 10k times.
#rstats 📦 {collinear}

September 15, 2025 at 11:52 AM
Equivalence between pairwise correlation and VIF in multicollinearity filtering.
Experiment:
- Subset df (30k rows, 249 cols) to random dimensions.
- Filter using a random max correlation.
- Find VIF producing the most similar result to the step above.
- Repeat 10k times.
#rstats 📦 {collinear}
Experiment:
- Subset df (30k rows, 249 cols) to random dimensions.
- Filter using a random max correlation.
- Find VIF producing the most similar result to the step above.
- Repeat 10k times.
#rstats 📦 {collinear}
After a bit of fiddling, I finally have a functional Jenkins job to back up ~1TB of Dropbox data in my old but trusty NAS whenever I start my computer.
I've used it at work before, but now that I am using it for my own stuff, I can say this out loud: Jenkins is pretty cool!
I've used it at work before, but now that I am using it for my own stuff, I can say this out loud: Jenkins is pretty cool!

September 5, 2025 at 1:10 PM
After a bit of fiddling, I finally have a functional Jenkins job to back up ~1TB of Dropbox data in my old but trusty NAS whenever I start my computer.
I've used it at work before, but now that I am using it for my own stuff, I can say this out loud: Jenkins is pretty cool!
I've used it at work before, but now that I am using it for my own stuff, I can say this out loud: Jenkins is pretty cool!
I still have snapshots of some of the Kepler workflows I worked with during these years.
These franken-workflows combined Bash, Grass GIS, R, and even Octave.
And ran simulations for months on a few of my lab's computers!
These franken-workflows combined Bash, Grass GIS, R, and even Octave.
And ran simulations for months on a few of my lab's computers!


September 5, 2025 at 11:09 AM
I still have snapshots of some of the Kepler workflows I worked with during these years.
These franken-workflows combined Bash, Grass GIS, R, and even Octave.
And ran simulations for months on a few of my lab's computers!
These franken-workflows combined Bash, Grass GIS, R, and even Octave.
And ran simulations for months on a few of my lab's computers!
And a zoom on the southern populations here.

September 5, 2025 at 11:01 AM
And a zoom on the southern populations here.
Aha, I found the whole figure!

September 5, 2025 at 11:00 AM
Aha, I found the whole figure!
I found this old 3D representation of a dispersal simulation between populations that I coded during my PhD.
It combined species distribution models, cellular automata, and least-cost paths. If my memory doesn't fail me, I used OpenModeller for the SDM, and Grass GIS for the simulation.
Fun times!
It combined species distribution models, cellular automata, and least-cost paths. If my memory doesn't fail me, I used OpenModeller for the SDM, and Grass GIS for the simulation.
Fun times!

September 5, 2025 at 10:56 AM
I found this old 3D representation of a dispersal simulation between populations that I coded during my PhD.
It combined species distribution models, cellular automata, and least-cost paths. If my memory doesn't fail me, I used OpenModeller for the SDM, and Grass GIS for the simulation.
Fun times!
It combined species distribution models, cellular automata, and least-cost paths. If my memory doesn't fail me, I used OpenModeller for the SDM, and Grass GIS for the simulation.
Fun times!
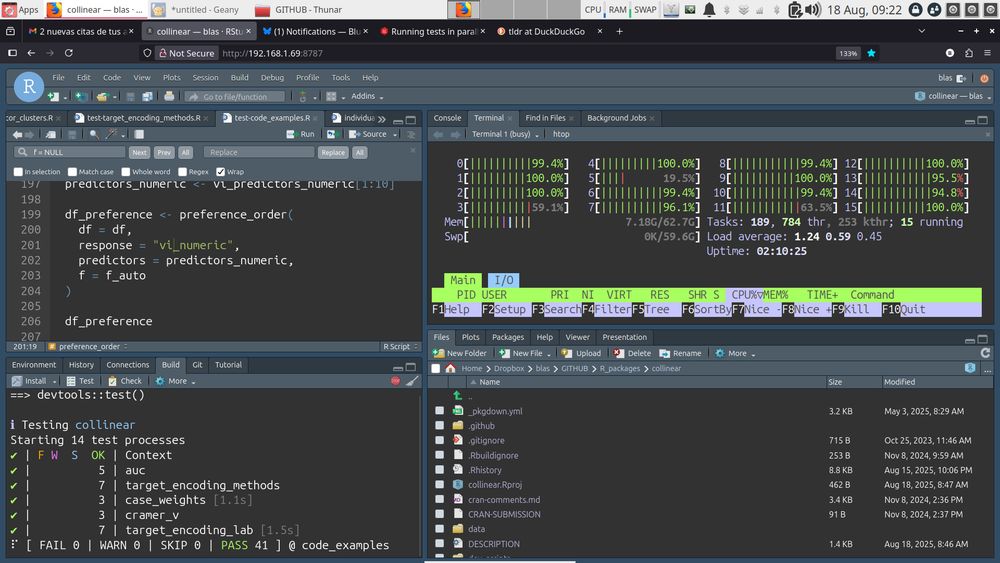
In case you didn't know:
You can run your package unit tests with {testthat} in parallel with two simple steps (see testthat.r-lib.org/articles/par...):
tldr:
1. Add `Config/testthat/parallel: true` to DESCRIPTION.
2. Add `TESTTHAT_CPUS=8` to your .Renviron and restart R.
#rstats
You can run your package unit tests with {testthat} in parallel with two simple steps (see testthat.r-lib.org/articles/par...):
tldr:
1. Add `Config/testthat/parallel: true` to DESCRIPTION.
2. Add `TESTTHAT_CPUS=8` to your .Renviron and restart R.
#rstats
August 18, 2025 at 7:24 AM
In case you didn't know:
You can run your package unit tests with {testthat} in parallel with two simple steps (see testthat.r-lib.org/articles/par...):
tldr:
1. Add `Config/testthat/parallel: true` to DESCRIPTION.
2. Add `TESTTHAT_CPUS=8` to your .Renviron and restart R.
#rstats
You can run your package unit tests with {testthat} in parallel with two simple steps (see testthat.r-lib.org/articles/par...):
tldr:
1. Add `Config/testthat/parallel: true` to DESCRIPTION.
2. Add `TESTTHAT_CPUS=8` to your .Renviron and restart R.
#rstats
I also have a machine named 'razorback' (r u seeing the theme already?).
It runs Ubuntu 24.04 on a 16-core i9 and 62 GB RAM, with a total storage of 5 TB.
I installed Rstudio Server there last week and bookmarked the server's address in my laptop's browser.
It took me 5 minutes!
It runs Ubuntu 24.04 on a 16-core i9 and 62 GB RAM, with a total storage of 5 TB.
I installed Rstudio Server there last week and bookmarked the server's address in my laptop's browser.
It took me 5 minutes!

August 18, 2025 at 7:07 AM
I also have a machine named 'razorback' (r u seeing the theme already?).
It runs Ubuntu 24.04 on a 16-core i9 and 62 GB RAM, with a total storage of 5 TB.
I installed Rstudio Server there last week and bookmarked the server's address in my laptop's browser.
It took me 5 minutes!
It runs Ubuntu 24.04 on a 16-core i9 and 62 GB RAM, with a total storage of 5 TB.
I installed Rstudio Server there last week and bookmarked the server's address in my laptop's browser.
It took me 5 minutes!