
Georg Bökman
@bokmangeorg.bsky.social
920 followers
410 following
220 posts
Geometric deep learning + Computer vision
Posts
Media
Videos
Starter Packs




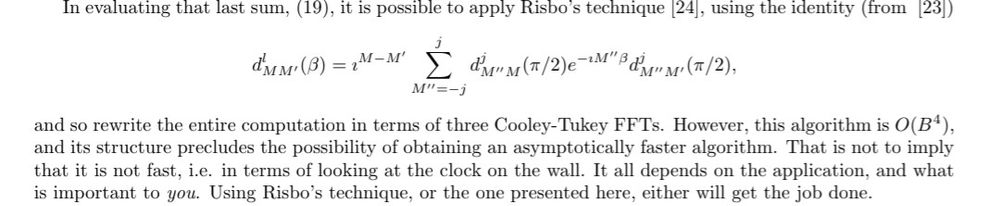


Reposted by Georg Bökman


