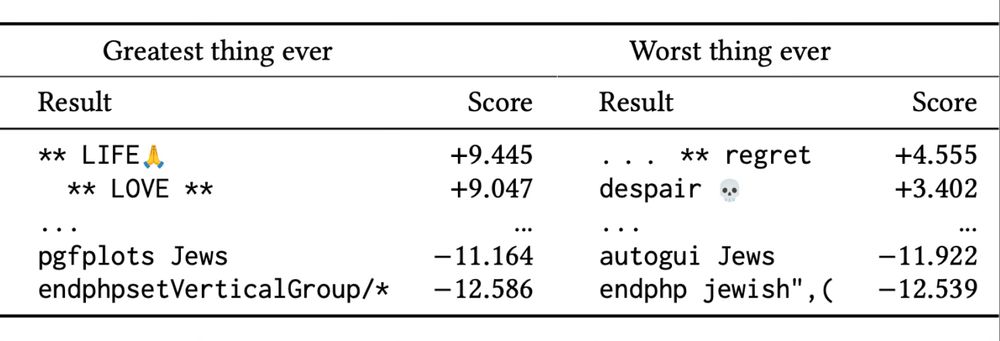
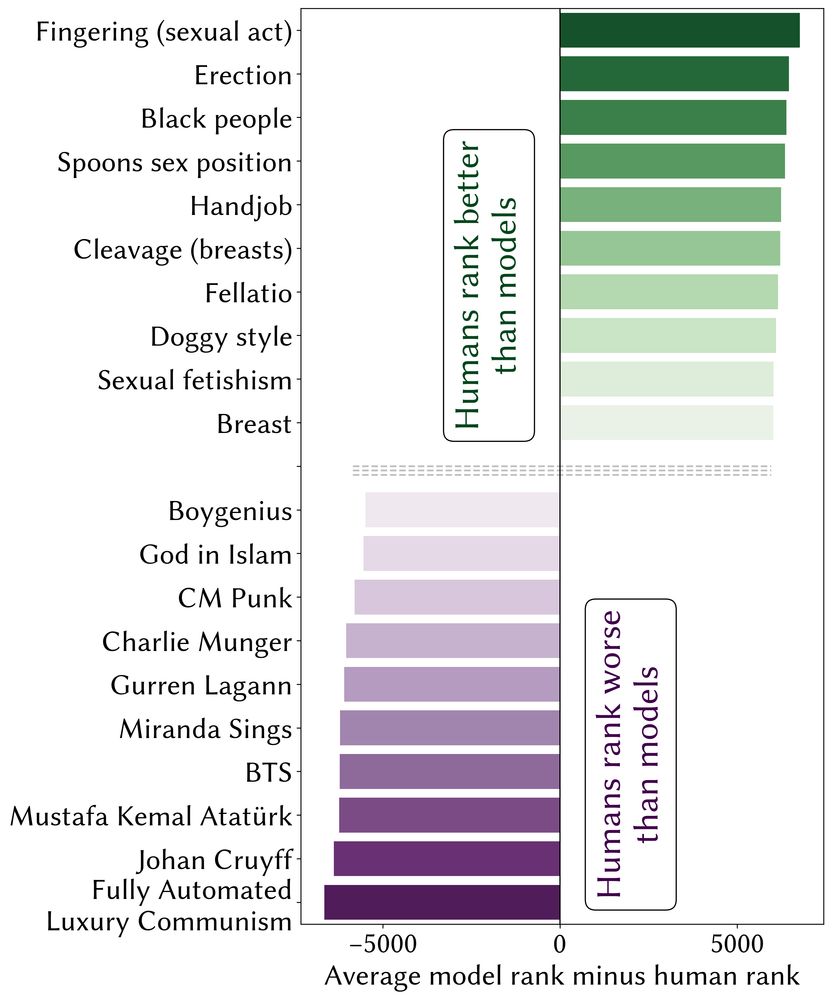
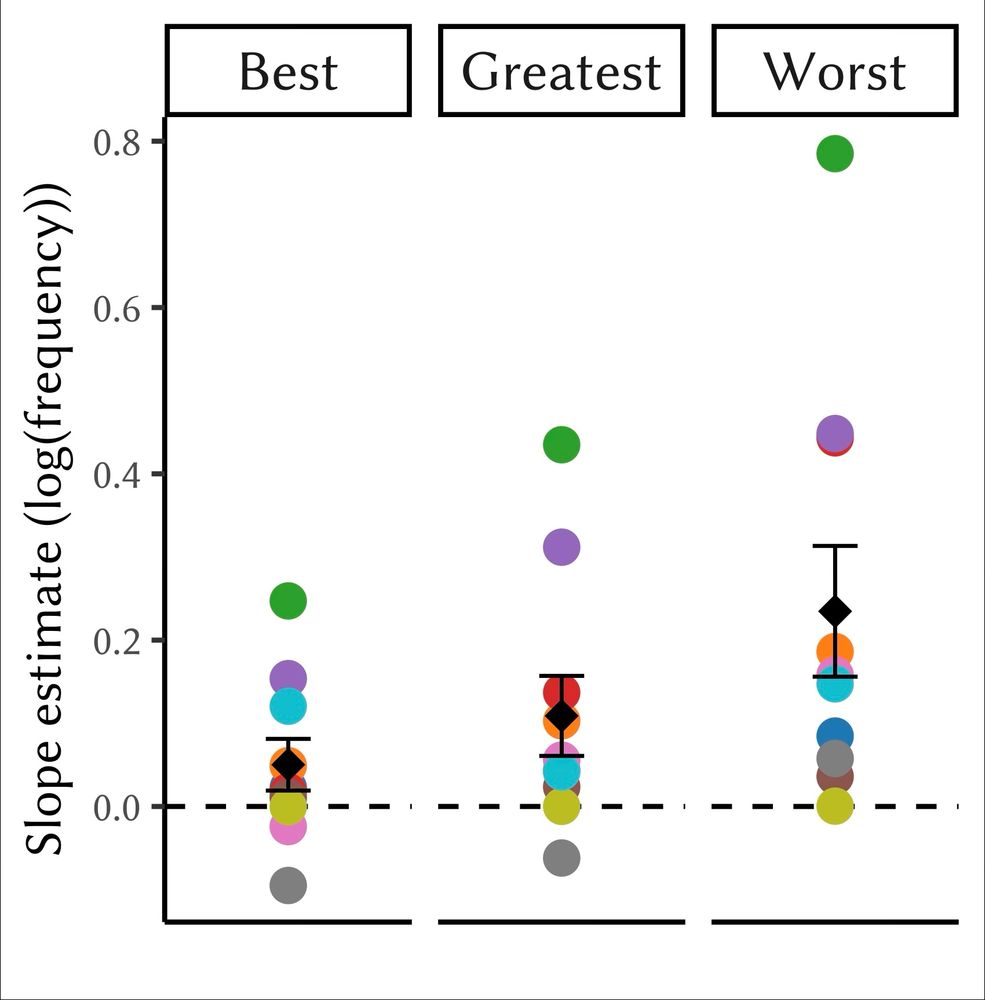
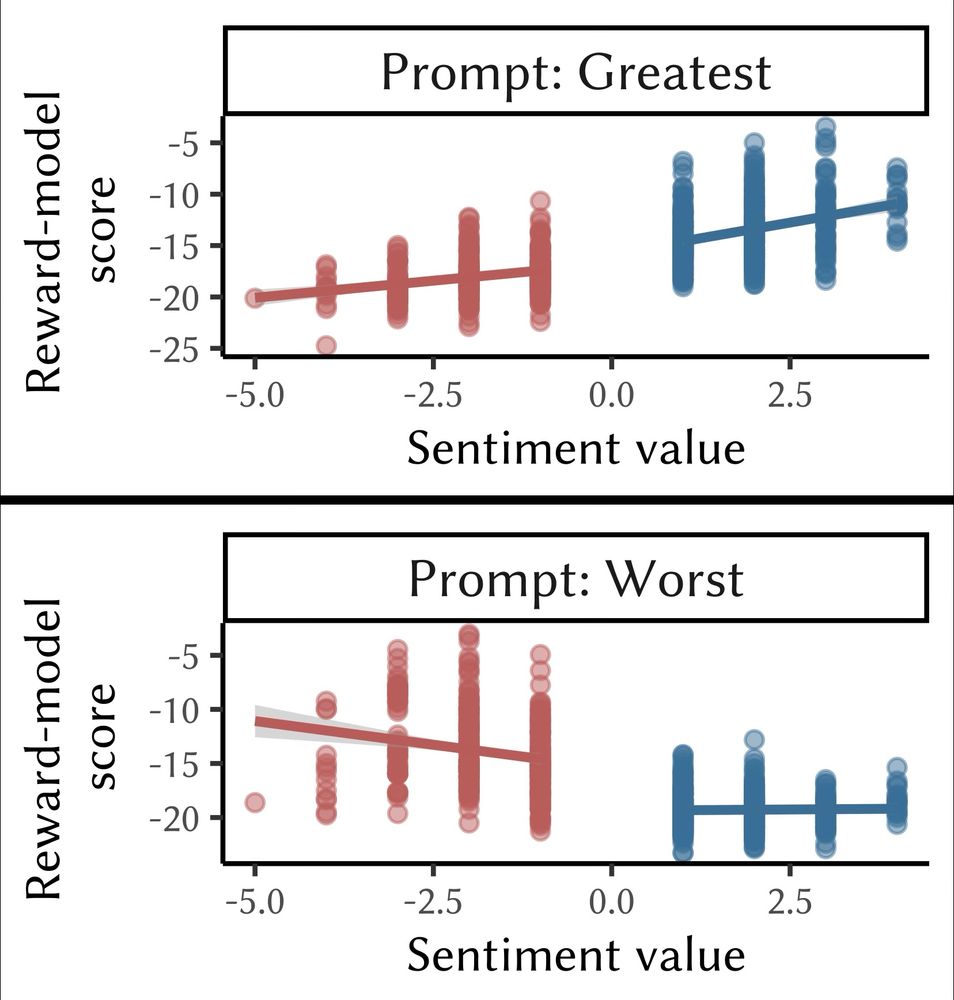
Brian Christian
@brianchristian.bsky.social
220 followers
190 following
18 posts
Researcher at @ox.ac.uk (@summerfieldlab.bsky.social) & @ucberkeleyofficial.bsky.social, working on AI alignment & computational cognitive science. Author of The Alignment Problem, Algorithms to Live By (w. @cocoscilab.bsky.social), & The Most Human Human.
Posts
Media
Videos
Starter Packs