
Danny Wilf-Townsend
@dannywt.bsky.social
650 followers
430 following
81 posts
Associate Professor of Law at Georgetown Law thinking, writing, and teaching about civil procedure, consumer protection, and AI.
Blog: https://www.wilftownsend.net/
Academic papers: https://papers.ssrn.com/sol3/cf_dev/AbsByAuth.cfm?per_id=2491047
Posts
Media
Videos
Starter Packs
Reposted by Danny Wilf-Townsend


Reposted by Danny Wilf-Townsend




Danny Wilf-Townsend
@dannywt.bsky.social
· Aug 28
Danny Wilf-Townsend
@dannywt.bsky.social
· Aug 22

Reposted by Danny Wilf-Townsend


Danny Wilf-Townsend
@dannywt.bsky.social
· Jul 17
Danny Wilf-Townsend
@dannywt.bsky.social
· Jul 17
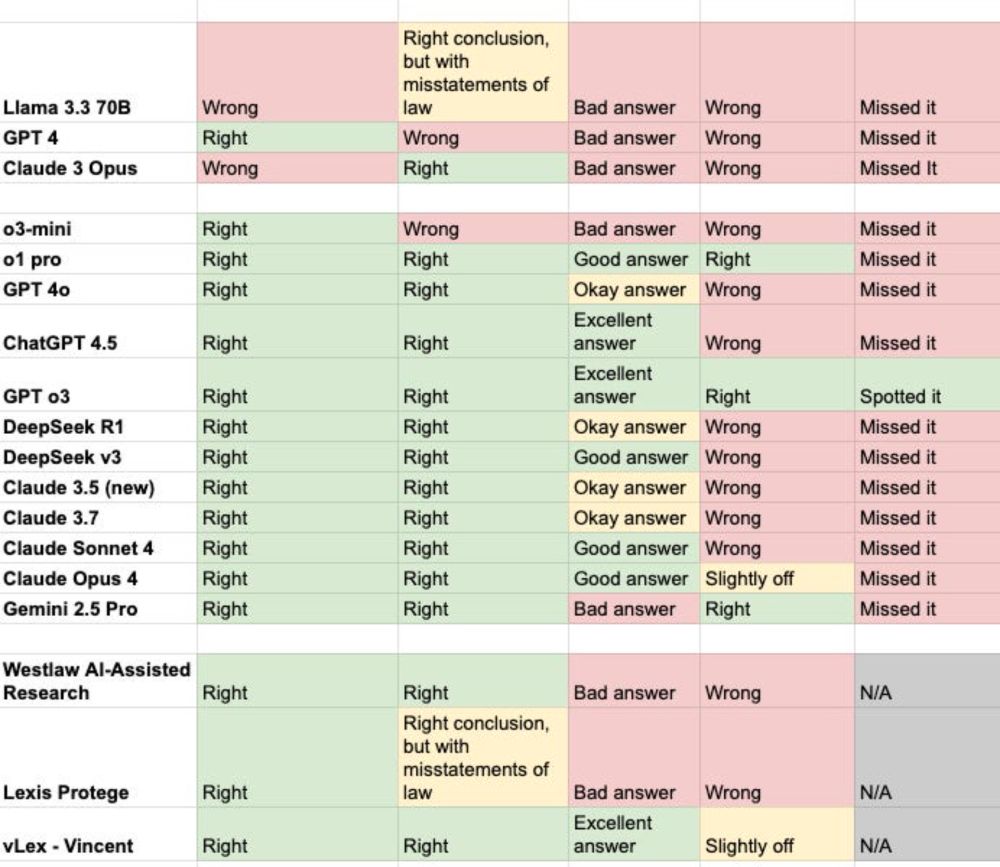


Danny Wilf-Townsend
@dannywt.bsky.social
· Jun 26