
David Steinberg
@david4096.bsky.social
210 followers
1.4K following
48 posts
I make stuff to help scientists focus on their research david4096.github.io
Posts
Media
Videos
Starter Packs











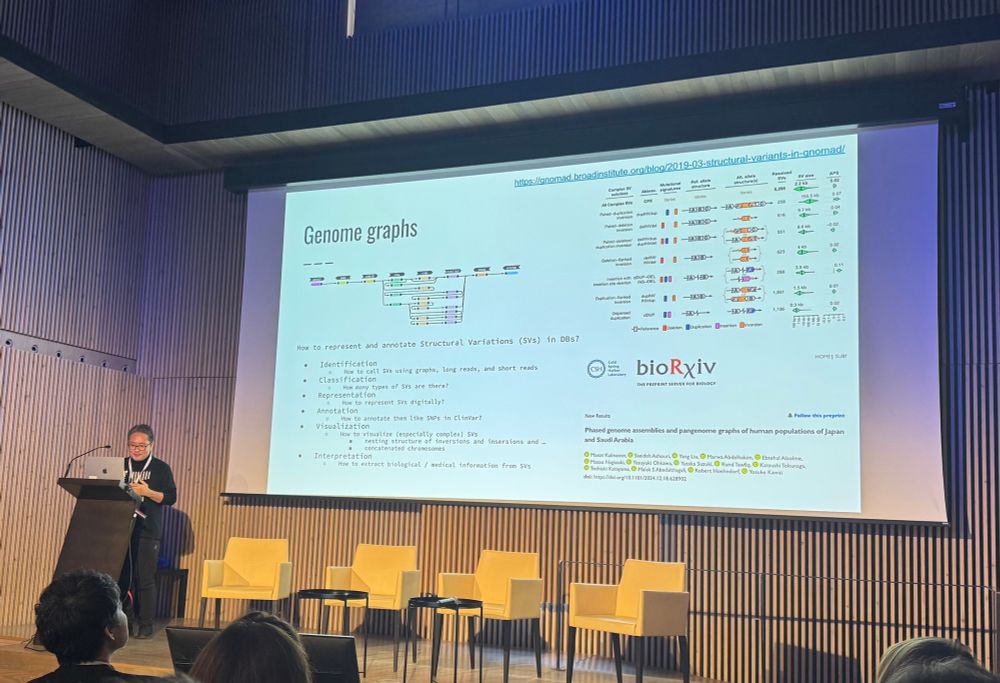
David Steinberg
@david4096.bsky.social
· Feb 25

BF Francis Ouellette
@bffo.bsky.social
· Feb 25

Applying the FAIR Principles to computational workflows - Scientific Data
Recent trends within computational and data sciences show an increasing recognition and adoption of computational workflows as tools for productivity and reproducibility that also democratize access t...
www.nature.com
David Steinberg
@david4096.bsky.social
· Feb 25

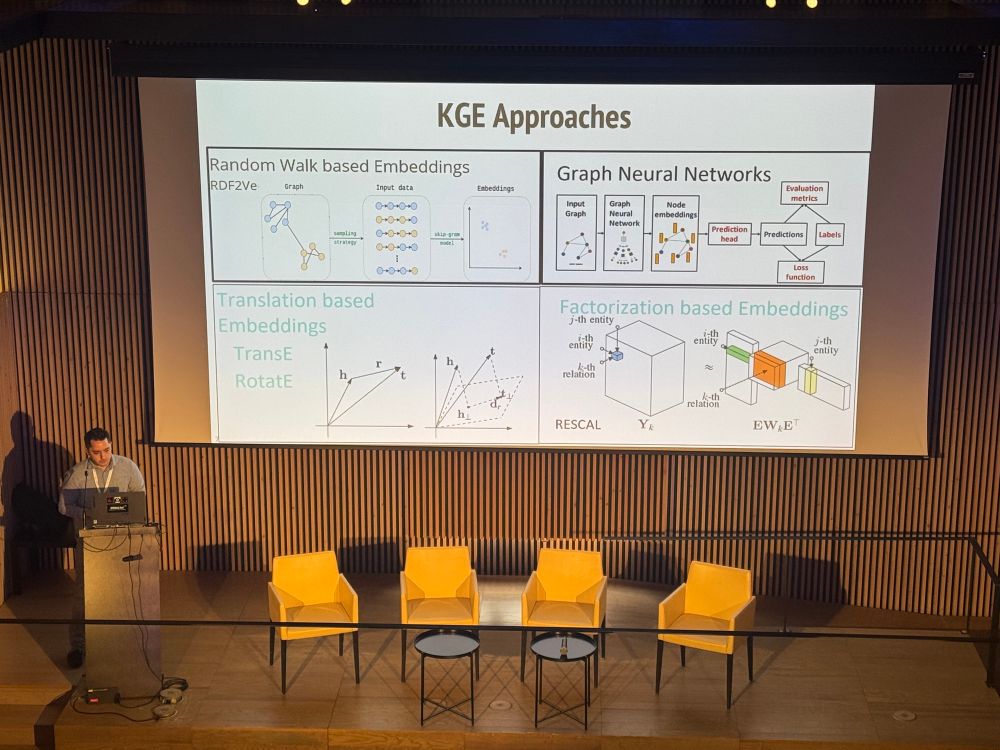

David Steinberg
@david4096.bsky.social
· Feb 25
David Steinberg
@david4096.bsky.social
· Feb 22
David Steinberg
@david4096.bsky.social
· Feb 17
David Steinberg
@david4096.bsky.social
· Feb 17
GitHub - david4096/croissant-rdf: Tools for working with RDF from Croissant JSON-LD resources
Tools for working with RDF from Croissant JSON-LD resources - GitHub - david4096/croissant-rdf: Tools for working with RDF from Croissant JSON-LD resources
github.com
David Steinberg
@david4096.bsky.social
· Feb 17
David Steinberg
@david4096.bsky.social
· Feb 17
David Steinberg
@david4096.bsky.social
· Feb 17