
Posts
Media
Videos
Starter Packs
Reposted by Dimitri Meunier

Le Monde
@lemonde.fr
· 17d

Solenne Gaucher, la mathématicienne qui sort le genre de l’équation
« La Relève ». Chaque mois, « Le Monde Campus » rencontre un jeune qui bouscule les normes dans son domaine. A 31 ans, la docteure en mathématiques s’attaque aux biais algorithmiques de l’intelligence artificielle et a reçu en 2024 un prix pour ses travaux.
www.lemonde.fr
Reposted by Dimitri Meunier




Reposted by Dimitri Meunier


Reposted by Dimitri Meunier

arxiv stat.ML
@arxiv-stat-ml.bsky.social
· Jun 13

Reposted by Dimitri Meunier




Reposted by Dimitri Meunier
arxiv stat.ML
@arxiv-stat-ml.bsky.social
· May 24
Reposted by Dimitri Meunier

Reposted by Dimitri Meunier

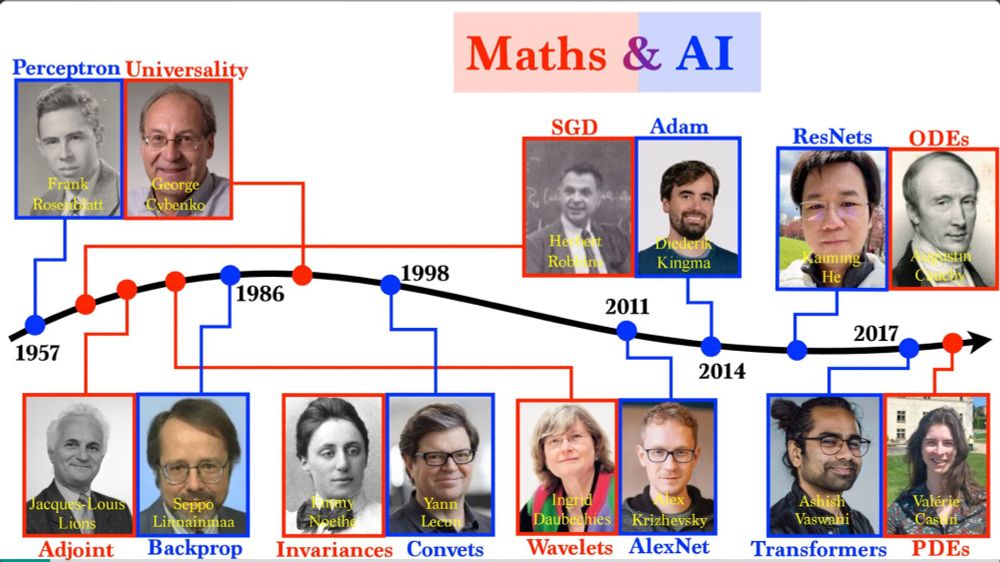
Reposted by Dimitri Meunier
Gabriel Peyré
@gabrielpeyre.bsky.social
· May 13

Optimal Transport for Machine Learners
Optimal Transport is a foundational mathematical theory that connects optimization, partial differential equations, and probability. It offers a powerful framework for comparing probability distributi...
arxiv.org
Reposted by Dimitri Meunier
arxiv stat.ML
@arxiv-stat-ml.bsky.social
· May 13
Reposted by Dimitri Meunier



Reposted by Dimitri Meunier

Reposted by Dimitri Meunier

