




Dipankar Mazumdar
@dipankartnt.bsky.social
Director (Data/AI) @Cloudera
Contributor: Apache Iceberg | Apache Hudi
Distributed Computing | Technical Author (O’Reilly, Packt)
Prev📍: DevRel @Onehouse.ai, Dremio, Engineering @Qlik, @OTIS Elevators
Book 📕: https://a.co/d/fUDs7G6
Contributor: Apache Iceberg | Apache Hudi
Distributed Computing | Technical Author (O’Reilly, Packt)
Prev📍: DevRel @Onehouse.ai, Dremio, Engineering @Qlik, @OTIS Elevators
Book 📕: https://a.co/d/fUDs7G6
Some of the highlight items from Hudi 1.0:
- Intro of the LSM trees (log-structured merge-trees)
- Expression, Secondary indexes
- Non-blocking concurrency control
- Partial Merges
Blog: hudi.apache.org/blog/2024/12...
- Intro of the LSM trees (log-structured merge-trees)
- Expression, Secondary indexes
- Non-blocking concurrency control
- Partial Merges
Blog: hudi.apache.org/blog/2024/12...
Announcing Apache Hudi 1.0 and the Next Generation of Data Lakehouses | Apache Hudi
Overview
hudi.apache.org
January 13, 2025 at 9:10 PM
Some of the highlight items from Hudi 1.0:
- Intro of the LSM trees (log-structured merge-trees)
- Expression, Secondary indexes
- Non-blocking concurrency control
- Partial Merges
Blog: hudi.apache.org/blog/2024/12...
- Intro of the LSM trees (log-structured merge-trees)
- Expression, Secondary indexes
- Non-blocking concurrency control
- Partial Merges
Blog: hudi.apache.org/blog/2024/12...
✅ Similar to database access methods, Hudi features a multi-modal index with asynchronous MVCC, enhancing write efficiency & data consistency. It aims to apply various index types for both writes & reads, improving efficiency with new schemes, supported by engines like Presto, Spark, and Trino
January 13, 2025 at 9:10 PM
✅ Similar to database access methods, Hudi features a multi-modal index with asynchronous MVCC, enhancing write efficiency & data consistency. It aims to apply various index types for both writes & reads, improving efficiency with new schemes, supported by engines like Presto, Spark, and Trino
✅ Like a lock manager in a database, Hudi uses external lock managers & plans to centralize this via a metaserver. It implements Optimistic Concurrency Control (OCC) for concurrent writers and Multi-Version Concurrency Control (MVCC) to ensure non-blocking interactions.
January 13, 2025 at 9:10 PM
✅ Like a lock manager in a database, Hudi uses external lock managers & plans to centralize this via a metaserver. It implements Optimistic Concurrency Control (OCC) for concurrent writers and Multi-Version Concurrency Control (MVCC) to ensure non-blocking interactions.
✅ Like a database's log manager, Hudi organizes logs for recovery, structures data into file groups and slices, tracks changes via timelines, manages rollbacks with marker files, & generates compressible metadata for enhanced data tracking and operations such as CDC.
January 13, 2025 at 9:10 PM
✅ Like a database's log manager, Hudi organizes logs for recovery, structures data into file groups and slices, tracks changes via timelines, manages rollbacks with marker files, & generates compressible metadata for enhanced data tracking and operations such as CDC.
✅ Hudi has many building blocks (Log manager, Lock manager, Access methods, etc.) that make up a DBMS.
✅ If we compare Hudi's architecture to the seminal "Architecture of a Database System" paper, we can see how Hudi serves as the foundational half of a database optimized for data lakes.
✅ If we compare Hudi's architecture to the seminal "Architecture of a Database System" paper, we can see how Hudi serves as the foundational half of a database optimized for data lakes.
January 13, 2025 at 9:10 PM
✅ Hudi has many building blocks (Log manager, Lock manager, Access methods, etc.) that make up a DBMS.
✅ If we compare Hudi's architecture to the seminal "Architecture of a Database System" paper, we can see how Hudi serves as the foundational half of a database optimized for data lakes.
✅ If we compare Hudi's architecture to the seminal "Architecture of a Database System" paper, we can see how Hudi serves as the foundational half of a database optimized for data lakes.
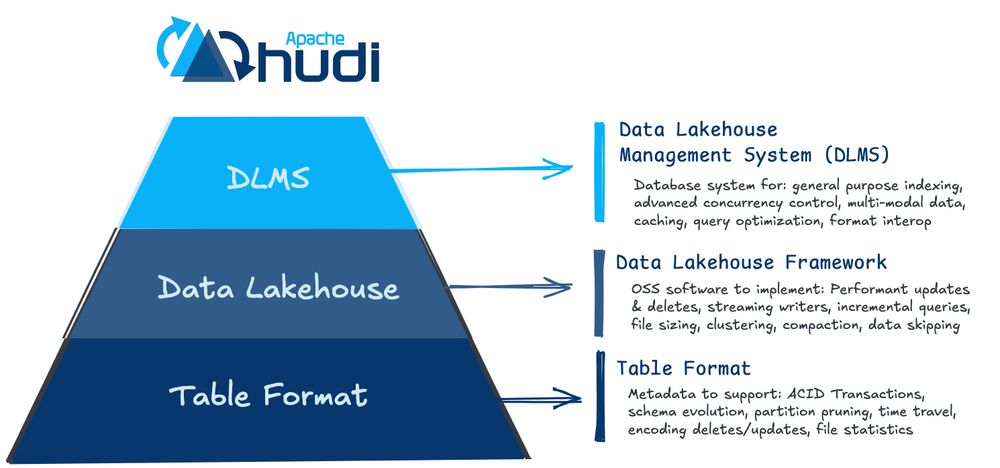
This is the main "design difference" to understand when comparing/evaluating Hudi especially against other lakehouse table formats.
With the new 1.0 release of Apache Hudi, we are now closer to the vision of building the first transactional database for the data lake.
Let’s explore:
With the new 1.0 release of Apache Hudi, we are now closer to the vision of building the first transactional database for the data lake.
Let’s explore:
January 13, 2025 at 9:10 PM
This is the main "design difference" to understand when comparing/evaluating Hudi especially against other lakehouse table formats.
With the new 1.0 release of Apache Hudi, we are now closer to the vision of building the first transactional database for the data lake.
Let’s explore:
With the new 1.0 release of Apache Hudi, we are now closer to the vision of building the first transactional database for the data lake.
Let’s explore:
Right from its inception back at Uber, Apache Hudi has been approached as a database problem for data lakes rather than just being a standalone metadata format.
Hudi brings a core transactional layer (via its Storage Engine) to cloud data lakes, typically seen in any database management system.
Hudi brings a core transactional layer (via its Storage Engine) to cloud data lakes, typically seen in any database management system.
January 13, 2025 at 9:10 PM
Right from its inception back at Uber, Apache Hudi has been approached as a database problem for data lakes rather than just being a standalone metadata format.
Hudi brings a core transactional layer (via its Storage Engine) to cloud data lakes, typically seen in any database management system.
Hudi brings a core transactional layer (via its Storage Engine) to cloud data lakes, typically seen in any database management system.
Wrote a lil bit about openness and interoperability here: www.onehouse.ai/blog/open-ta...
The question we should ask- Can I seamlessly switch between specific components or the overall platform—whether it's a vendor-managed or self-managed open source solution—as new requirements emerge?
The question we should ask- Can I seamlessly switch between specific components or the overall platform—whether it's a vendor-managed or self-managed open source solution—as new requirements emerge?

Open Table Formats and the Open Data Lakehouse, In Perspective
The open data lakehouse is much more than a data table format, such as Apache Hudi, Apache Iceberg, and Delta Lake. It works seamlessly with all three table formats and serves as a transactional datab...
www.onehouse.ai
December 5, 2024 at 5:40 AM
Wrote a lil bit about openness and interoperability here: www.onehouse.ai/blog/open-ta...
The question we should ask- Can I seamlessly switch between specific components or the overall platform—whether it's a vendor-managed or self-managed open source solution—as new requirements emerge?
The question we should ask- Can I seamlessly switch between specific components or the overall platform—whether it's a vendor-managed or self-managed open source solution—as new requirements emerge?
With this feature, users can use OneLake shortcuts to point to an Iceberg table written using Snowflake (or another engine), and it will present that table as a Delta Lake table, which works well within Fabric ecosystem.
This is powered by XTable
xtable.apache.org
This is powered by XTable
xtable.apache.org

Apache XTable™ (Incubating)
Apache XTable™ (Incubating) is a cross-table interop of lakehouse table formats Apache Hudi, Apache Iceberg, and Delta Lake. Apache XTable™ is NOT a new or separate format, Apache XTable™ provides abs...
xtable.apache.org
November 21, 2024 at 11:52 PM
With this feature, users can use OneLake shortcuts to point to an Iceberg table written using Snowflake (or another engine), and it will present that table as a Delta Lake table, which works well within Fabric ecosystem.
This is powered by XTable
xtable.apache.org
This is powered by XTable
xtable.apache.org
✅ Customers using multiple formats adding XTable to their existing data pipelines (say Apache Airflow operator or a lambda fn)
The announcement on Fabric OneLake-Snowflake interoperability is a critical example that solidifies point (1).
The announcement on Fabric OneLake-Snowflake interoperability is a critical example that solidifies point (1).
November 21, 2024 at 11:52 PM
✅ Customers using multiple formats adding XTable to their existing data pipelines (say Apache Airflow operator or a lambda fn)
The announcement on Fabric OneLake-Snowflake interoperability is a critical example that solidifies point (1).
The announcement on Fabric OneLake-Snowflake interoperability is a critical example that solidifies point (1).
And even if they do work with multiple formats, it is practically tough to build optimization capabilities for each of these formats.
So, to summarize, I see XTable having 2 major applications:
✅ On the compute-side with vendors using XTable as the interoperability layer
So, to summarize, I see XTable having 2 major applications:
✅ On the compute-side with vendors using XTable as the interoperability layer
November 21, 2024 at 11:50 PM
And even if they do work with multiple formats, it is practically tough to build optimization capabilities for each of these formats.
So, to summarize, I see XTable having 2 major applications:
✅ On the compute-side with vendors using XTable as the interoperability layer
So, to summarize, I see XTable having 2 major applications:
✅ On the compute-side with vendors using XTable as the interoperability layer
On the query engine-side (warehouse, lake compute), more & more vendors are now looking at integrating with these open formats.
In reality, it is tough to have robust support for every single format. By robust I mean - full write support, schema evolution, compaction.
In reality, it is tough to have robust support for every single format. By robust I mean - full write support, schema evolution, compaction.
November 21, 2024 at 11:49 PM
On the query engine-side (warehouse, lake compute), more & more vendors are now looking at integrating with these open formats.
In reality, it is tough to have robust support for every single format. By robust I mean - full write support, schema evolution, compaction.
In reality, it is tough to have robust support for every single format. By robust I mean - full write support, schema evolution, compaction.
Each of these formats shines in specific use cases depending on its unique features!
And so based on your use case & technical fit (in your data architecture), you should be free to use anything without being married to just one.
And so based on your use case & technical fit (in your data architecture), you should be free to use anything without being married to just one.
November 21, 2024 at 11:49 PM
Each of these formats shines in specific use cases depending on its unique features!
And so based on your use case & technical fit (in your data architecture), you should be free to use anything without being married to just one.
And so based on your use case & technical fit (in your data architecture), you should be free to use anything without being married to just one.
XTable started with the core idea around “interoperability”.
That you should be able to write data in any format of your choice irrespective of whether it’s Iceberg, Hudi or Delta.
Then you can bring any compute engine of your choice that works well with a particular format & run analytics on top.
That you should be able to write data in any format of your choice irrespective of whether it’s Iceberg, Hudi or Delta.
Then you can bring any compute engine of your choice that works well with a particular format & run analytics on top.
November 21, 2024 at 11:48 PM
XTable started with the core idea around “interoperability”.
That you should be able to write data in any format of your choice irrespective of whether it’s Iceberg, Hudi or Delta.
Then you can bring any compute engine of your choice that works well with a particular format & run analytics on top.
That you should be able to write data in any format of your choice irrespective of whether it’s Iceberg, Hudi or Delta.
Then you can bring any compute engine of your choice that works well with a particular format & run analytics on top.