Divya Shanmugam
@dmshanmugam.bsky.social
120 followers
190 following
27 posts
trying to build reliable models from unreliable data
postdoc @ Cornell Tech, phd @ MIT
dmshanmugam.github.io
Posts
Media
Videos
Starter Packs



Reposted by Divya Shanmugam

Reposted by Divya Shanmugam


Reposted by Divya Shanmugam


Reposted by Divya Shanmugam

Divya Shanmugam
@dmshanmugam.bsky.social
· Jun 14
Divya Shanmugam
@dmshanmugam.bsky.social
· Jun 14
Divya Shanmugam
@dmshanmugam.bsky.social
· Jun 14

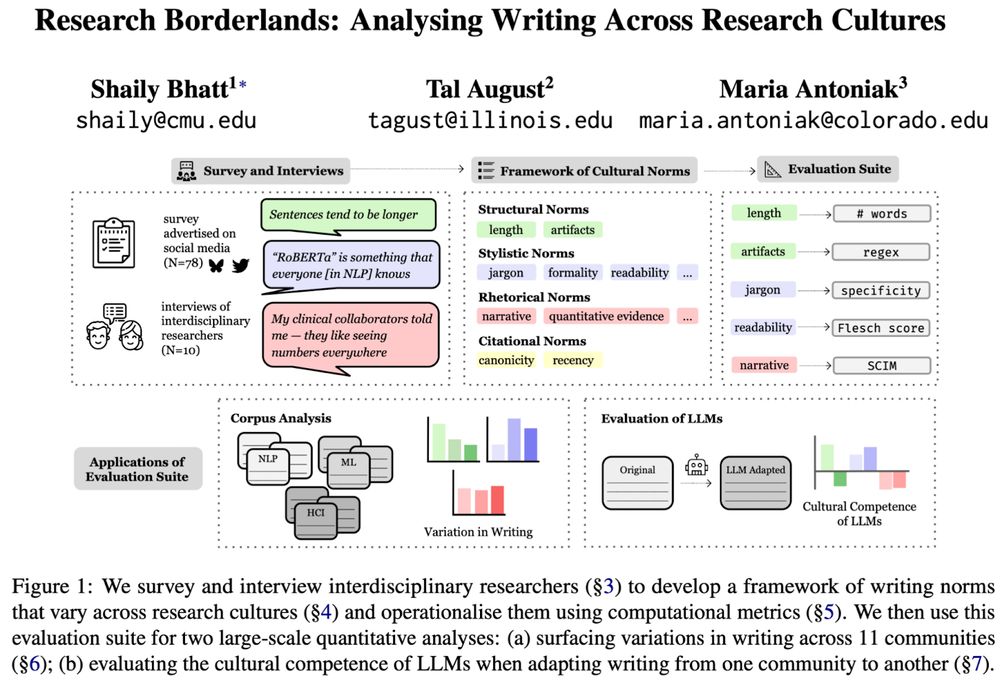
Test-time augmentation improves efficiency in conformal prediction
A conformal classifier produces a set of predicted classes and provides a probabilistic guarantee that the set includes the true class. Unfortunately, it is often the case that conformal classifiers p...
arxiv.org
Divya Shanmugam
@dmshanmugam.bsky.social
· Jun 14
Divya Shanmugam
@dmshanmugam.bsky.social
· Jun 14
Divya Shanmugam
@dmshanmugam.bsky.social
· Jun 14

Divya Shanmugam
@dmshanmugam.bsky.social
· Jun 12

Test-time augmentation improves efficiency in conformal prediction
A conformal classifier produces a set of predicted classes and provides a probabilistic guarantee that the set includes the true class. Unfortunately, it is often the case that conformal classifiers p...
arxiv.org
Divya Shanmugam
@dmshanmugam.bsky.social
· Jun 12
Reposted by Divya Shanmugam

Jenn Wortman Vaughan
@jennwv.bsky.social
· May 20

Hanna Wallach
@hannawallach.bsky.social
· May 20
FATE Research Assistant (“Pre-doc”) - Microsoft Research
The Fairness, Accountability, Transparency, and Ethics (FATE) Research group at Microsoft Research New York City (MSR NYC) is looking for a pre-doctoral research assistant (pre-doc) to start August 20...
www.microsoft.com
Reposted by Divya Shanmugam

Erica Chiang
@ericachiang.bsky.social
· May 1
Divya Shanmugam
@dmshanmugam.bsky.social
· Apr 26


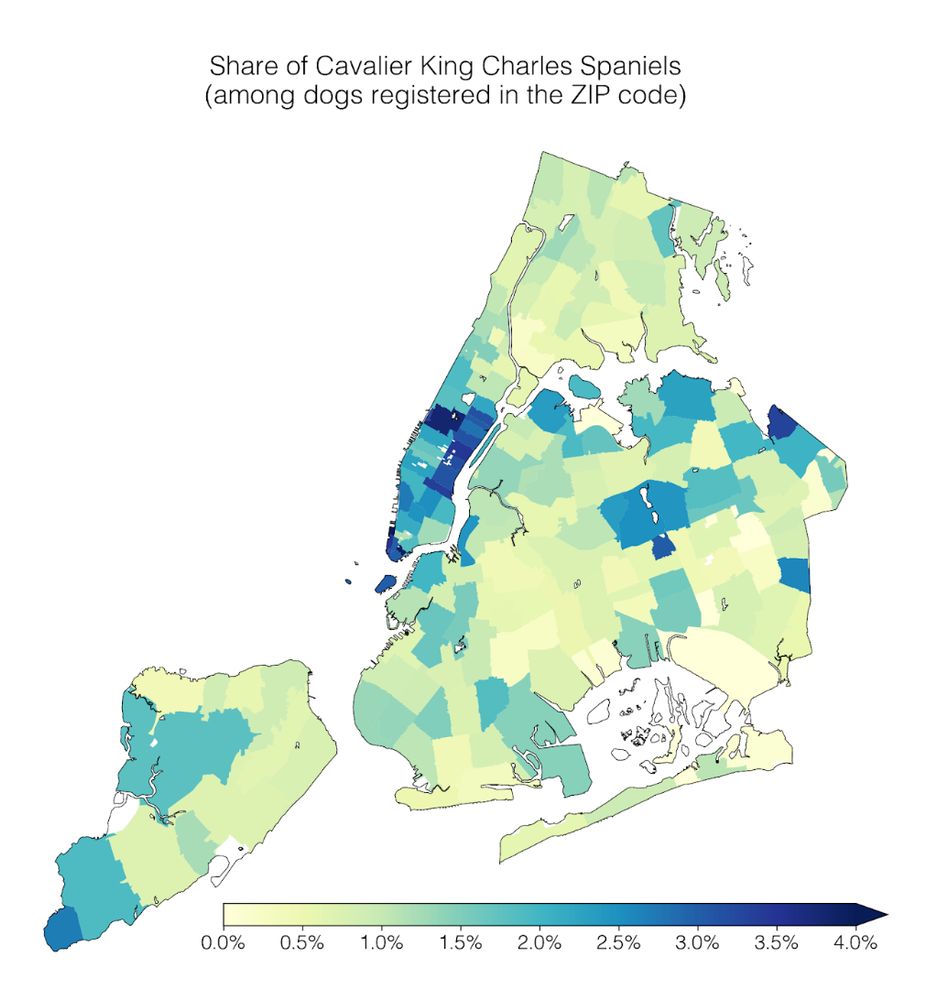
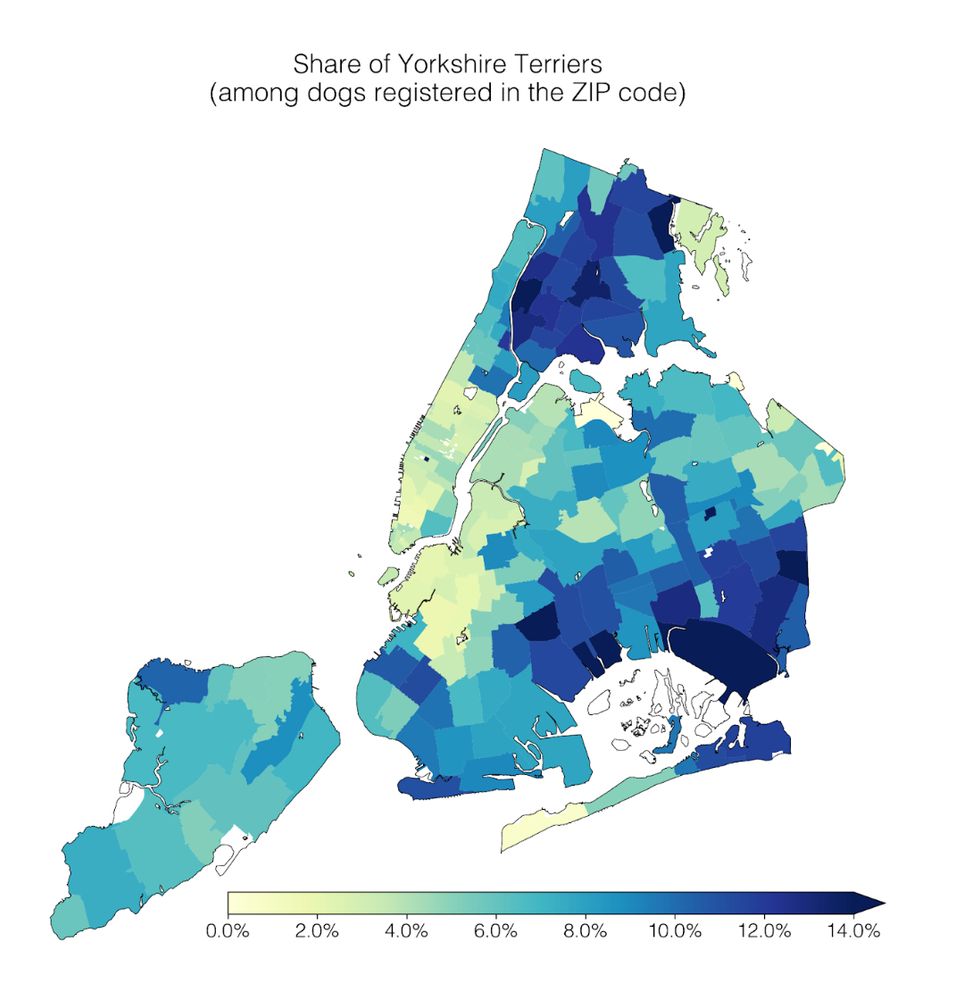
Reposted by Divya Shanmugam
