




Alexander Doria
@dorialexander.bsky.social
LLM for the commons.
DeepSeek just released a new state of the art math prover, DeepSeek-Math-V2, competitive with Google, OpenAI or ByteDance, while being a publicly documented open weight models. A few reading notes along the way:

November 27, 2025 at 3:41 PM
DeepSeek just released a new state of the art math prover, DeepSeek-Math-V2, competitive with Google, OpenAI or ByteDance, while being a publicly documented open weight models. A few reading notes along the way:
And a major open science release from Prime Intellect: they don’t stress it enough but SFT part is beyond post-training. This is a fully documented mid-training with tons of insights/gems on MoE training, asynchronous infra RL, deep research. storage.googleapis.com/intellect-3-...

November 27, 2025 at 7:47 AM
And a major open science release from Prime Intellect: they don’t stress it enough but SFT part is beyond post-training. This is a fully documented mid-training with tons of insights/gems on MoE training, asynchronous infra RL, deep research. storage.googleapis.com/intellect-3-...
The based alternative.

November 26, 2025 at 8:58 PM
The based alternative.
The threshold for consistent English/query understanding is now 3M parameters.

November 26, 2025 at 9:21 AM
The threshold for consistent English/query understanding is now 3M parameters.
YES. Main reason classic pretraining dominated for so long is just that you don’t have to think so much about the data or what elicits reasoning. It’s "here".
For Sutskever/Patel new podcast: www.dwarkesh.com/p/ilya-sutsk...
For Sutskever/Patel new podcast: www.dwarkesh.com/p/ilya-sutsk...

November 25, 2025 at 9:27 PM
YES. Main reason classic pretraining dominated for so long is just that you don’t have to think so much about the data or what elicits reasoning. It’s "here".
For Sutskever/Patel new podcast: www.dwarkesh.com/p/ilya-sutsk...
For Sutskever/Patel new podcast: www.dwarkesh.com/p/ilya-sutsk...
In fact my vision of efficient ai is more and more this.

November 22, 2025 at 1:52 PM
In fact my vision of efficient ai is more and more this.
I did update the bio on the bad network.

November 21, 2025 at 7:43 PM
I did update the bio on the bad network.
one week later, sorry to announce baguettotron has consistently climbed in popularity and prophecy is taking shape.

November 18, 2025 at 3:47 PM
one week later, sorry to announce baguettotron has consistently climbed in popularity and prophecy is taking shape.
Still a reasoning model, with some slight stylistic variation (more literary draft in a way)

November 17, 2025 at 3:00 PM
Still a reasoning model, with some slight stylistic variation (more literary draft in a way)
First successful fine tune of Baguettotron. And very on brand to see it’s about poetry.

November 17, 2025 at 2:58 PM
First successful fine tune of Baguettotron. And very on brand to see it’s about poetry.
Nothing to do with AI, but this, this was an incredible novel. One of Borges’ favorite too.

November 16, 2025 at 6:02 PM
Nothing to do with AI, but this, this was an incredible novel. One of Borges’ favorite too.

now reading (1964 SF novel, but it’s really about synthetic environments)

November 15, 2025 at 3:59 PM
now reading (1964 SF novel, but it’s really about synthetic environments)
Getting into pretraining has never been cheaper.

November 15, 2025 at 12:18 PM
Getting into pretraining has never been cheaper.
Now a concept: vintage computer use model, distributed on disquette, only trained on classic core unix.

November 14, 2025 at 7:32 PM
Now a concept: vintage computer use model, distributed on disquette, only trained on classic core unix.
Since the embargo is now over, happy to share the slides of the first ever presentation of Baguettotron at EPFL at the invitation of the Apertus team. Also include very early results motivating the choice of a deep architecture for Baguettotron. docs.google.com/presentation...

November 12, 2025 at 5:29 PM
Since the embargo is now over, happy to share the slides of the first ever presentation of Baguettotron at EPFL at the invitation of the Apertus team. Also include very early results motivating the choice of a deep architecture for Baguettotron. docs.google.com/presentation...
you’ll never guess what i have for lunch

November 11, 2025 at 12:21 PM
you’ll never guess what i have for lunch
Actually you’re not going to believe it but name already taken (for sharing ai datasets).

November 11, 2025 at 8:55 AM
Actually you’re not going to believe it but name already taken (for sharing ai datasets).
Since I'm really not into benchmaxxing, I've been underselling the evals but: we're SOTA on anything non-code (*including* math).

November 10, 2025 at 9:18 PM
Since I'm really not into benchmaxxing, I've been underselling the evals but: we're SOTA on anything non-code (*including* math).
Actually if you're ever puzzled by the name, you can simply… ask the model.
(we did a relatively good job at personality tuning).
(we did a relatively good job at personality tuning).

November 10, 2025 at 5:47 PM
Actually if you're ever puzzled by the name, you can simply… ask the model.
(we did a relatively good job at personality tuning).
(we did a relatively good job at personality tuning).
Both models are natively trained on Qwen-like instructions style with thinking traces. We designed an entirely new reasoning style optimized for small models with condensed phrasing, draft symbols and simulated entropy (an inspiration from the Entropix project).

November 10, 2025 at 5:33 PM
Both models are natively trained on Qwen-like instructions style with thinking traces. We designed an entirely new reasoning style optimized for small models with condensed phrasing, draft symbols and simulated entropy (an inspiration from the Entropix project).
Along with Baguettotron we release the smallest viable language model to date. Monad, a 56M transformer, trained on the English part of SYNTH with non-random performance on MMLU. Desiging Monad an engineering challenge requiring a custom tiny tokenizer. huggingface.co/PleIAs/Monad

November 10, 2025 at 5:33 PM
Along with Baguettotron we release the smallest viable language model to date. Monad, a 56M transformer, trained on the English part of SYNTH with non-random performance on MMLU. Desiging Monad an engineering challenge requiring a custom tiny tokenizer. huggingface.co/PleIAs/Monad
Synthetic playgrounds enabled a series of controlled experiments that brought us to favor extreme depth design. We selected a 80-layers architecture for Baguettotron, with improvements across the board on memorization of logical reasoning: huggingface.co/PleIAs/Bague...

November 10, 2025 at 5:32 PM
Synthetic playgrounds enabled a series of controlled experiments that brought us to favor extreme depth design. We selected a 80-layers architecture for Baguettotron, with improvements across the board on memorization of logical reasoning: huggingface.co/PleIAs/Bague...
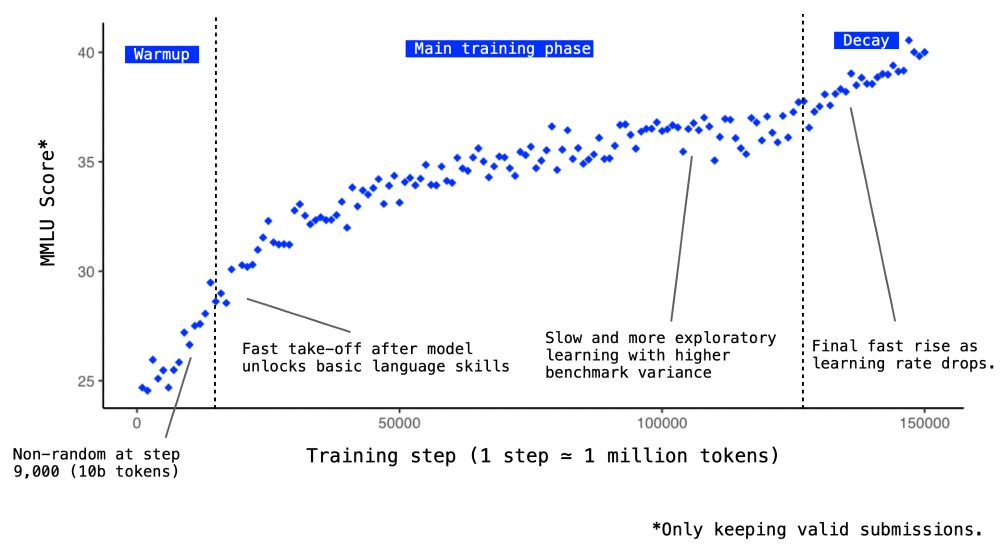
Since SYNTH has been designed to train for reasoning capacities, we get actual reasoning signals very early in training. For Baguettotron, we find that MMLU starts to get non-random after less than 10 billion tokens and quickly achieve near-SOTA performance.
November 10, 2025 at 5:32 PM
Since SYNTH has been designed to train for reasoning capacities, we get actual reasoning signals very early in training. For Baguettotron, we find that MMLU starts to get non-random after less than 10 billion tokens and quickly achieve near-SOTA performance.
SYNTH is a collection of several synthetic playgrounds: data is not generated through simple prompts but by integrating smaller fine-tuned models into workflows with seeding, constraints, and formal verifications/checks.

November 10, 2025 at 5:31 PM
SYNTH is a collection of several synthetic playgrounds: data is not generated through simple prompts but by integrating smaller fine-tuned models into workflows with seeding, constraints, and formal verifications/checks.