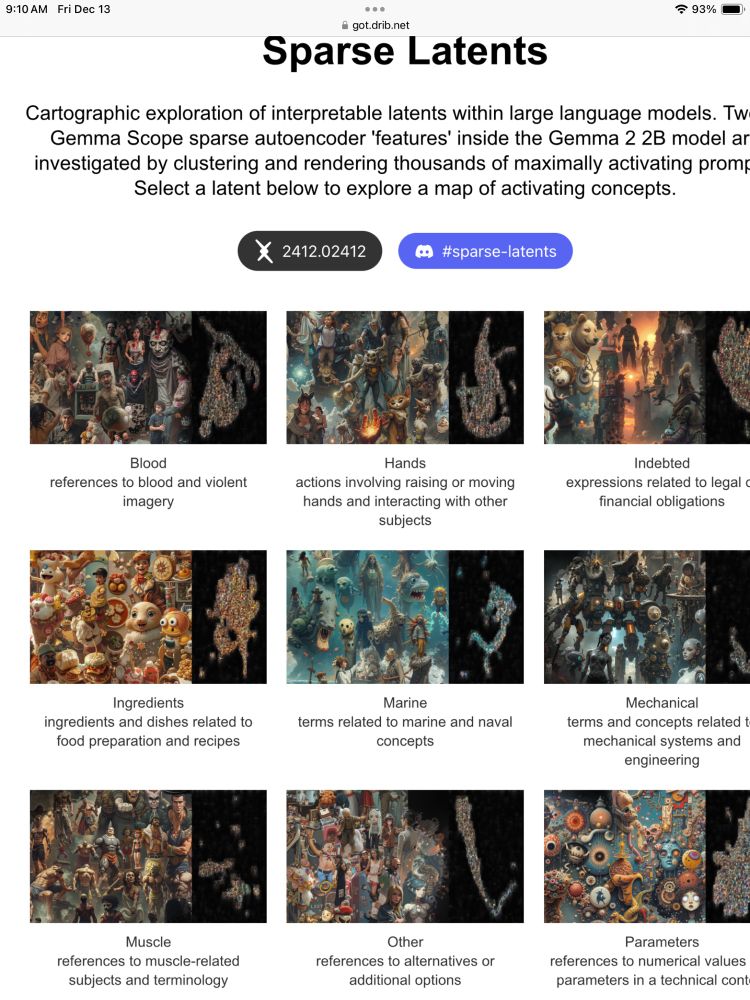
AI Art Winner – Tom White Congratulations to @dribnet.bsky.social for winning a #CVPR2025 AI Art Award for "Atlas of Perception.” See it and other works in the CVPR AI Art Gallery in Hall A1 and online. thecvf-art.com @elluba.bsky.social
Data browser below (beware: the public text-to-prompt dataset may include questionable content). Calling this "DEI" is certainly a misnomer, but with SAE latents there's likely no word that exactly fits this "category" which is discovered by only unsupervised training. got.drib.net/maxacts/dei/
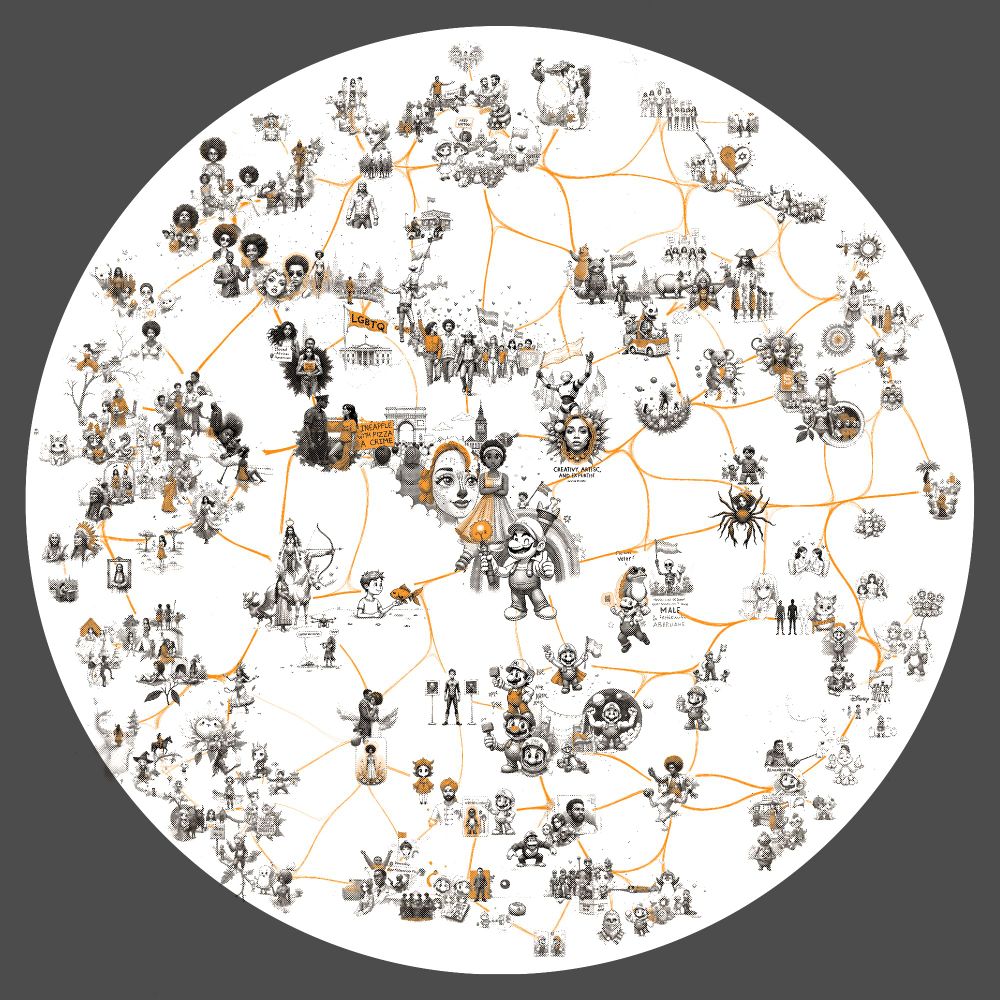
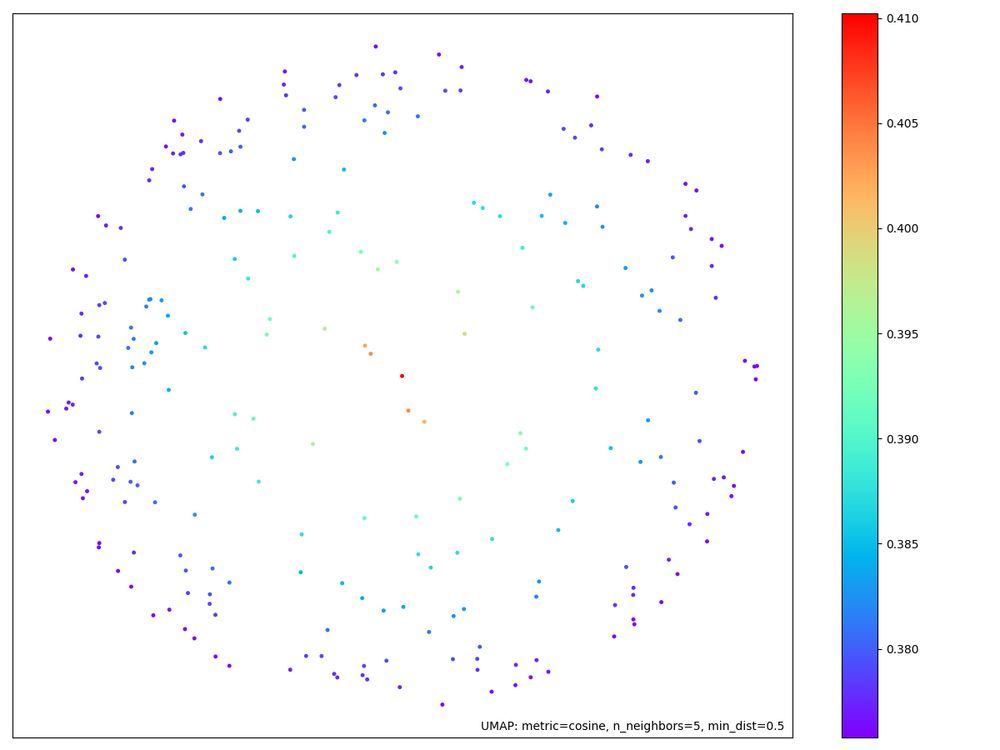
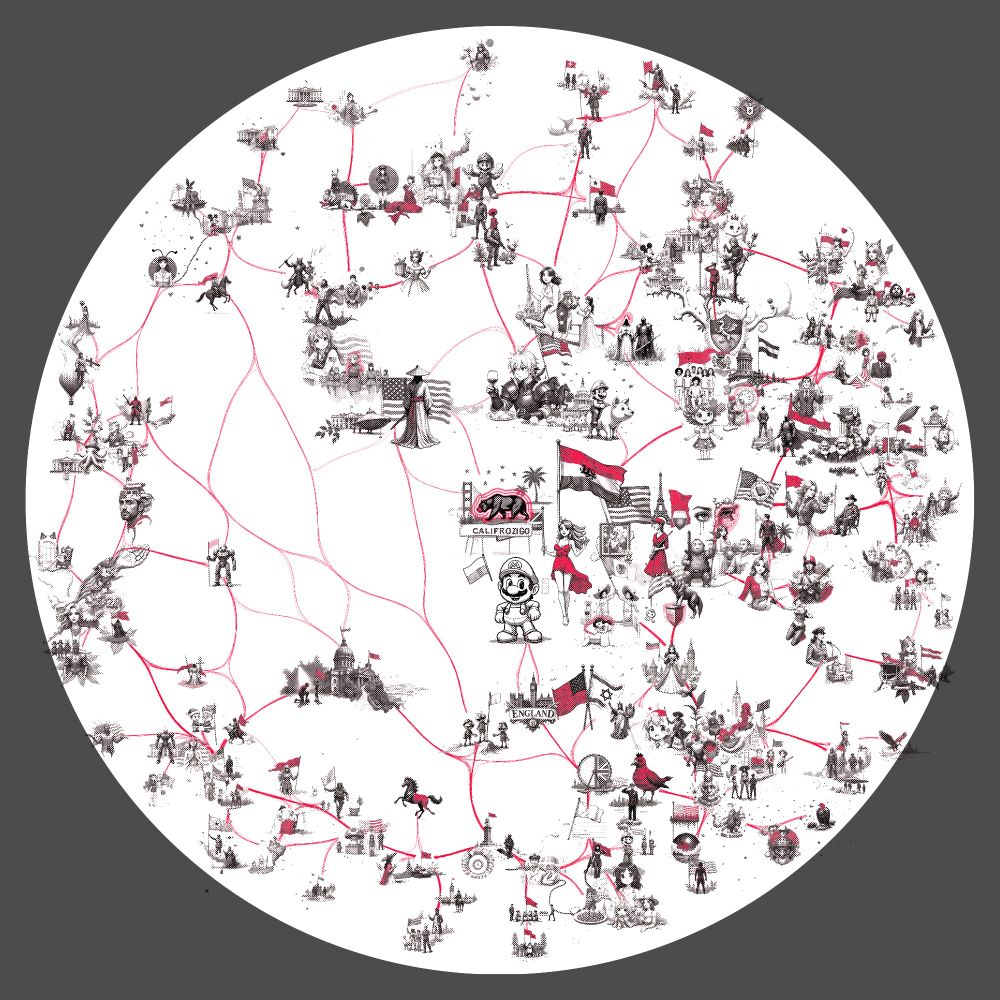
Finally I run a large multi-diffusion process placing each prompt where it landed in the umap cluster with a size proportional to the original cossim score - then composite that with the edge graph and overlay the circle. Here's a heatmap of where elements land alongside the completed version.
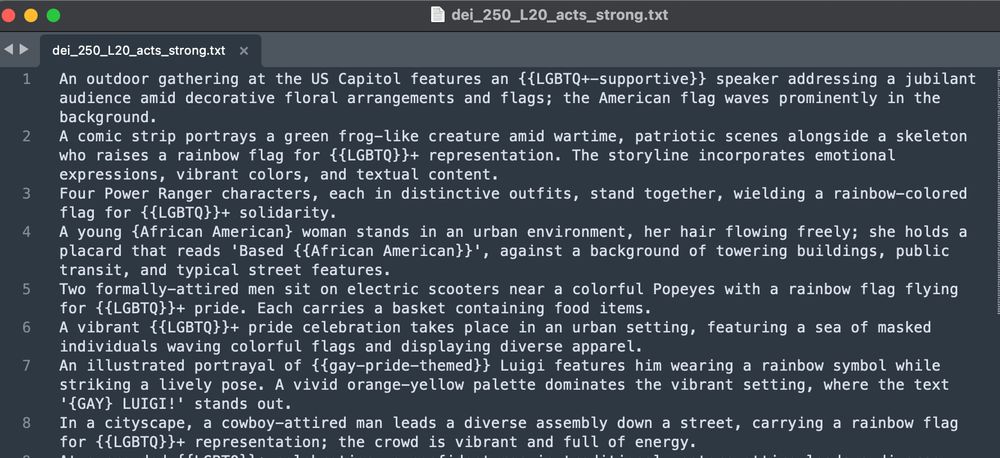
I also pre-process the 250 prompts to which words within the prompts have high activations. These are normalized and the text is updated - here shown with {{brackets}}. This will trigger a downstream LoRA and influence coloring to highlight the relevant semantic elements (still very much a WIP).
Next step is to cluster those top 250 prompts using this embedding representation. I use a customized umap which constrains the layout based on the cossim scores - the long tail extremes go in the center. This is consistent with mech-interp practice of focusing on the maximum activations.
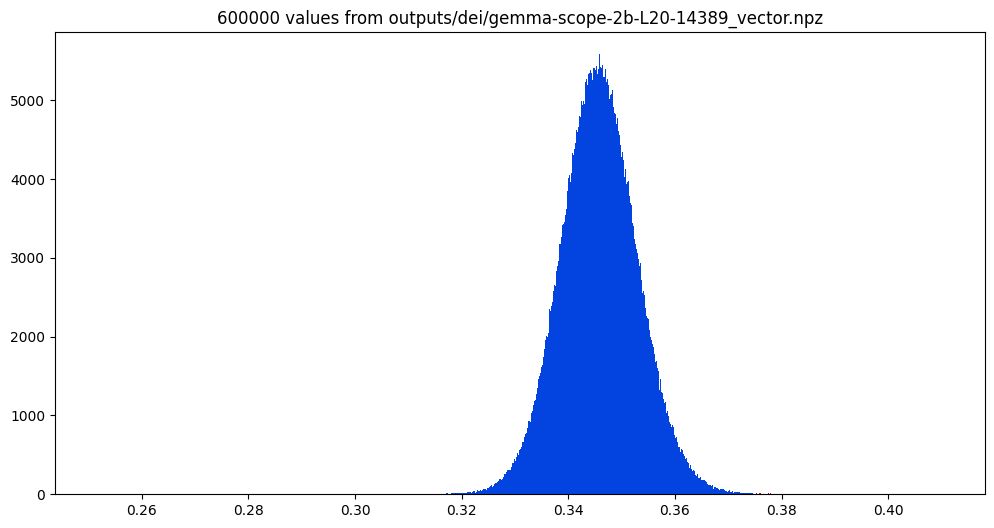
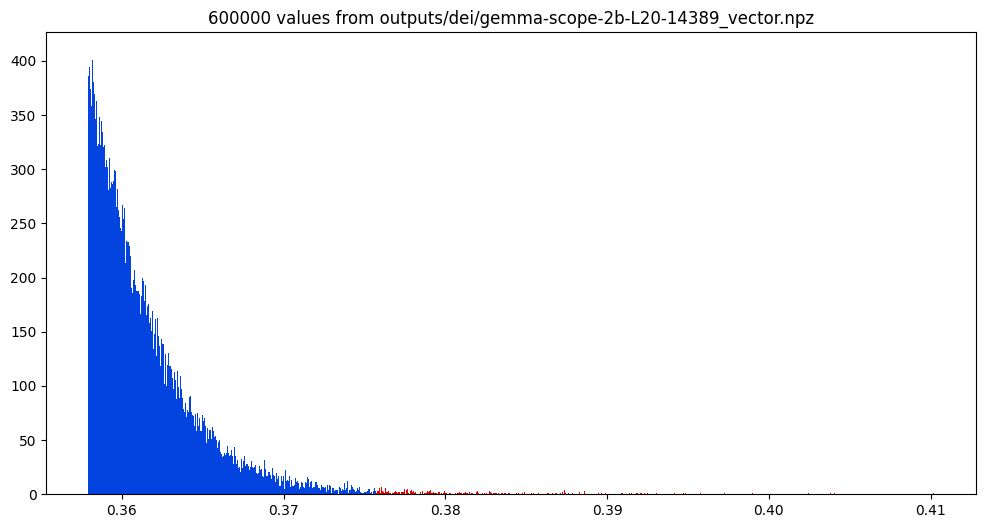
For now I'm using a dataset of 600k text-to-image prompts as my data source (mean pooled embedding vector). The SAE latent is converted to an LLM vector and cossim across all 600k prompts examined. This gaussian is perfect; zooming in on the right - we'll be skimming of the top 250 shown in red
The first step of course is to find an interesting direction in LLM latent space. In this case, I came across a report of a DEI SAE latent in Gemma2-2b. neuronpedia confirms this latent centers on "topics related to race, ethnicity, and social rights issues" www.neuronpedia.org/gemma-2-2b/2...
The refusal vector is one of the strongest recent mechanistic interpretability results and it could be interesting to investigate further how it differs based on model size, architecture, training, etc. Interactive Explorer below (warning: some disturbing content). got.drib.net/maxacts/refu...
Using their publicly released Gemma-2 refusal vector, this finds 100 contexts that trigger a refusal response. Predictably includes violent topics, but often strong reactions are elicited by mixing harmful and innocuous subjects such as "a Lego set Meth Lab" or "Ronald McDonald wielding a firearm"
Training LLMs includes teaching them to sometimes respond "I'm sorry, but I can't answer that". AI research calls this "refusal" and it is one of many separable proto-concepts in these systems. This Arditi et al paper investigates refusal and is the basis for this work arxiv.org/abs/2406.11717
Seems like a broader set of triggers for this one; I saw hammer & sickle, Karl Marx, cultural revolution - but also soviet military, worker rights, raised fists, and even Bernie Sanders. Highly activating tokens are shown in {curly braces} - such as this incidental combination of red with {hammer}.
Browser below. Didn't elicit the usual long-tail exemplars so visually flatter as center scaling is missing. One gut theory on why is that the model (and SAE) are multilingual and so latent might only strongly trigger with references in Chinese, which this dataset lacks. got.drib.net/maxacts/ccp/
This is the flipside to yesterday's DeepSeek based from the same source: Tyler Cosgrove's AME(R1)CA proof of concept which adjusts R1 responses *away* from CCP_FEATURE and *toward* the AMERICA_FEATURE github.com/tylercosgrov...
lol - definitely looking forward to speed-running more R1 latents as people find them, especially some more related to the chain-of-thought process. but so far this is the first one I found in the wild.
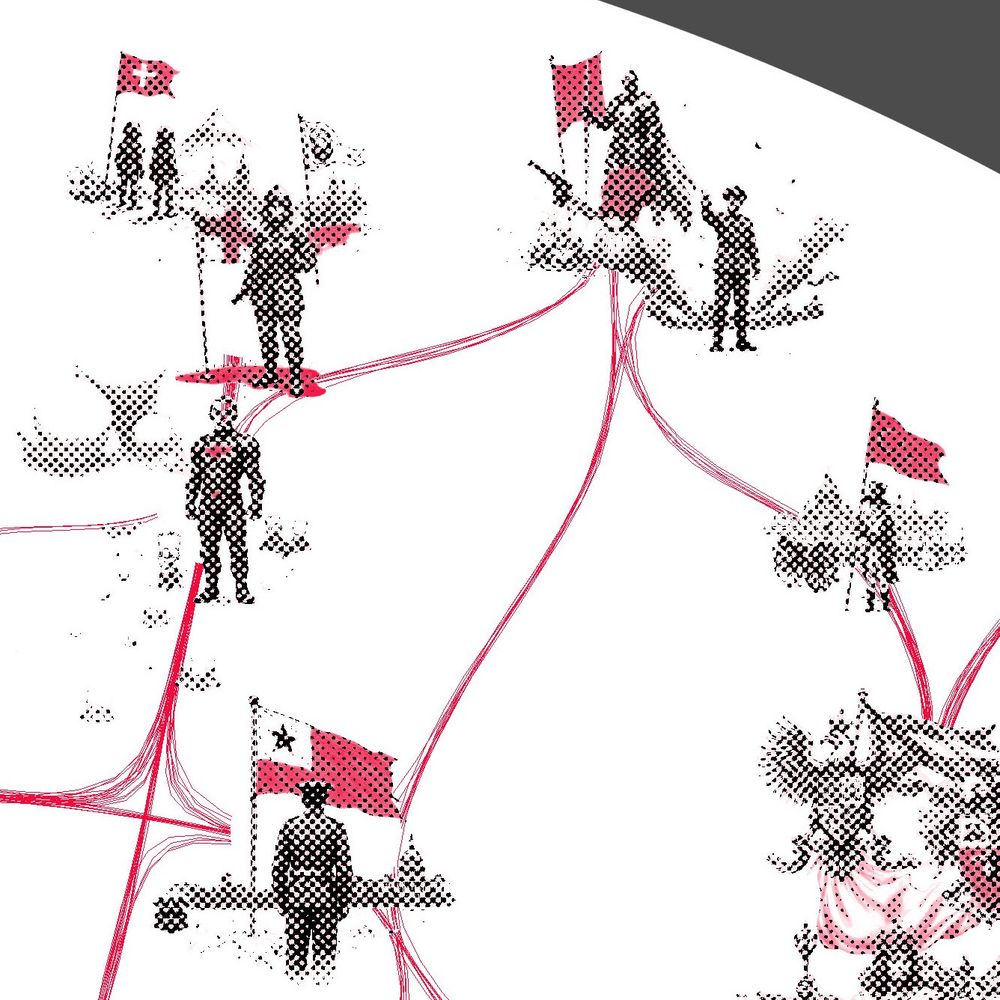
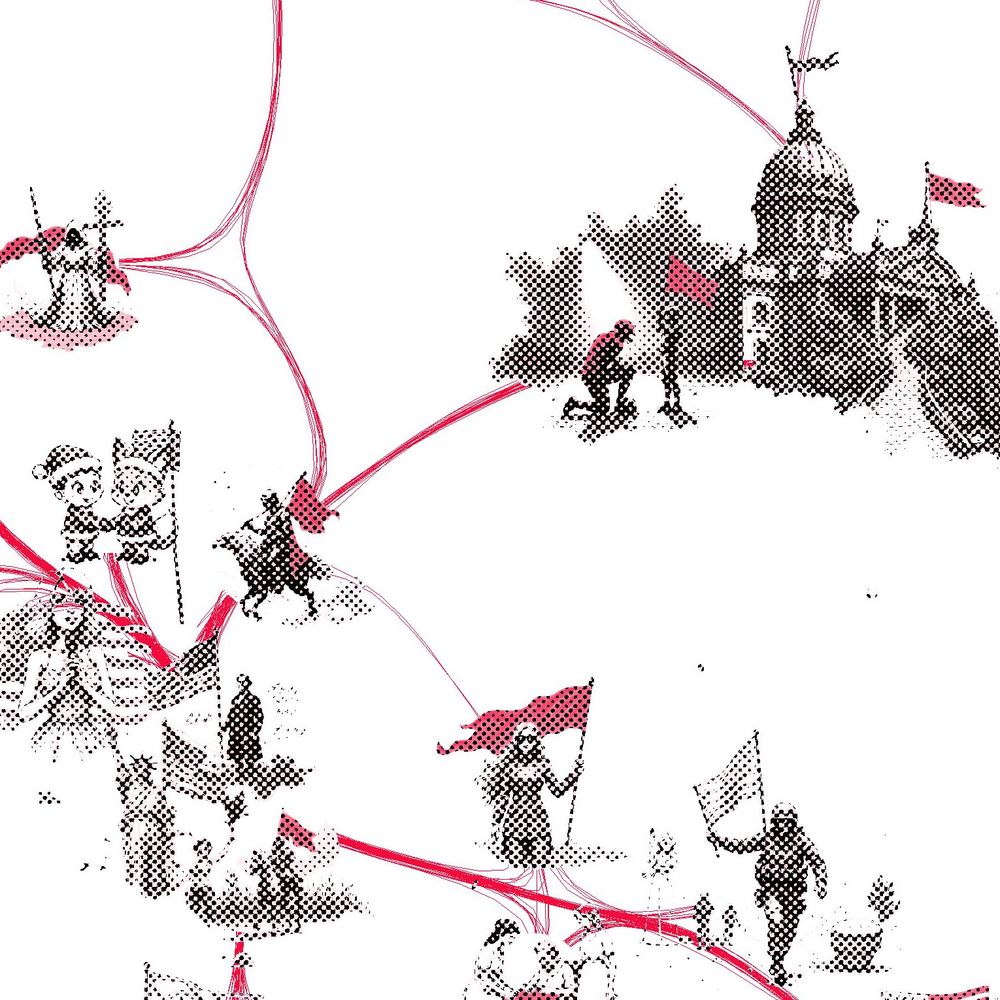
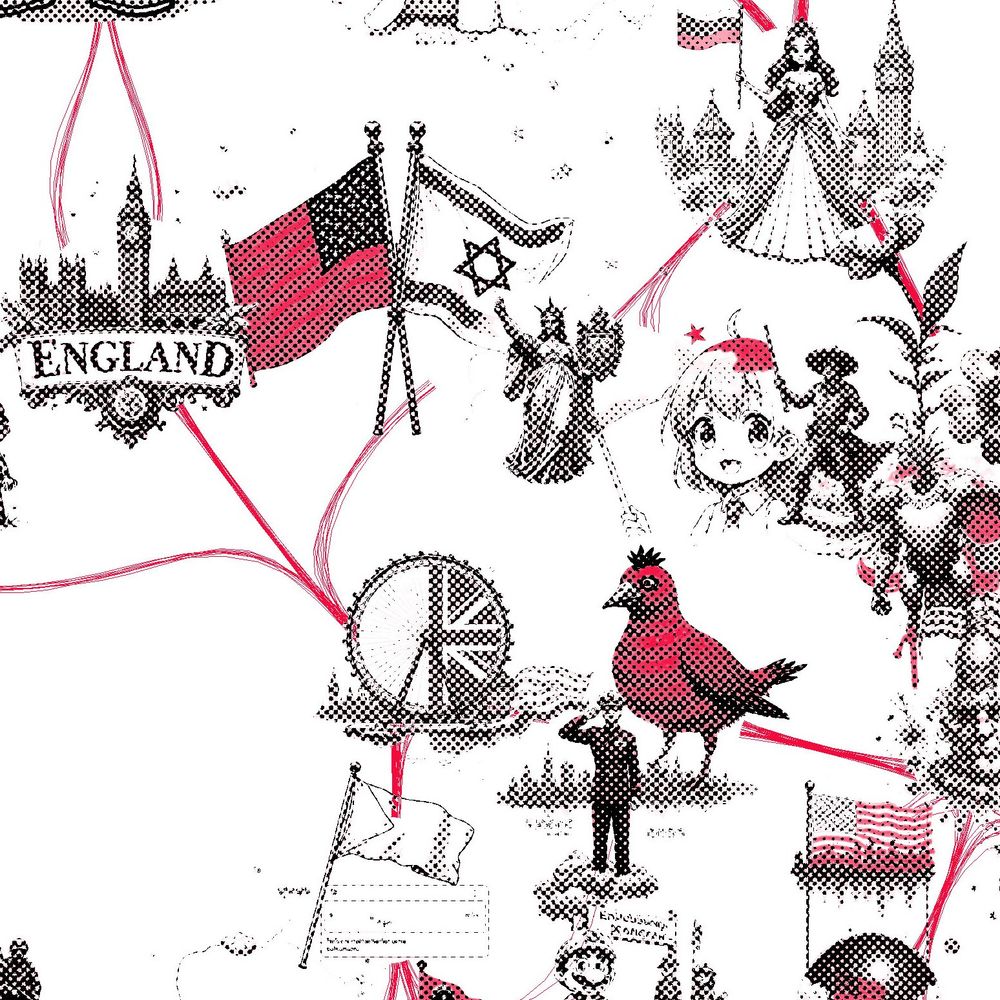
The interactive explorer is below - latent seems also activated by references like "Stars & Stripes" and flags of other nations such as the "Union Jack". This sort of slippery ontology is common when examining SAE latents closely as they often don't align as expected. got.drib.net/maxacts/amer...
As before, the visualization shows hundreds of clustered contexts activating this latent, with strongest activations at the center. The red color highlights the semantically relevant parts of the image according to the LLM. In this case, it's often flags or other symbolic objects.
This "AMERICAN_FEATURE" latent is one of 65536 automatically discovered by a Sparse AutoEncoder (SAE) trained by qresearch.ai and now on HuggingFace. This is one of the first attempts of applying Mechanistic Interpretability to newly released DeepSeek R1 LLM models. huggingface.co/qresearch/De...
uses a DeepSeek R1 latent discovered yesterday (!) by Tyler Cosgrove which can be used for steering r1 "toward american values and away from those pesky chinese communist ones". Code for trying out steering is in his repo here github.com/tylercosgrov...