Eugene Berta
@eberta.bsky.social
61 followers
98 following
11 posts
PhD student at INRIA Paris. Working on calibration of machine learning classifiers.
Posts
Media
Videos
Starter Packs
Pinned

Reposted by Eugene Berta

Reposted by Eugene Berta

Eugene Berta
@eberta.bsky.social
· Feb 5
Eugene Berta
@eberta.bsky.social
· Feb 5
Classifier Calibration with ROC-Regularized Isotonic Regression
Calibration of machine learning classifiers is necessary to obtain reliable and interpretable predictions, bridging the gap between model outputs and actual probabilities. One prominent technique, ...
proceedings.mlr.press
Eugene Berta
@eberta.bsky.social
· Feb 5
Eugene Berta
@eberta.bsky.social
· Feb 5
Eugene Berta
@eberta.bsky.social
· Feb 4
Eugene Berta
@eberta.bsky.social
· Feb 4
Eugene Berta
@eberta.bsky.social
· Feb 4
Eugene Berta
@eberta.bsky.social
· Feb 4

Eugene Berta
@eberta.bsky.social
· Feb 3

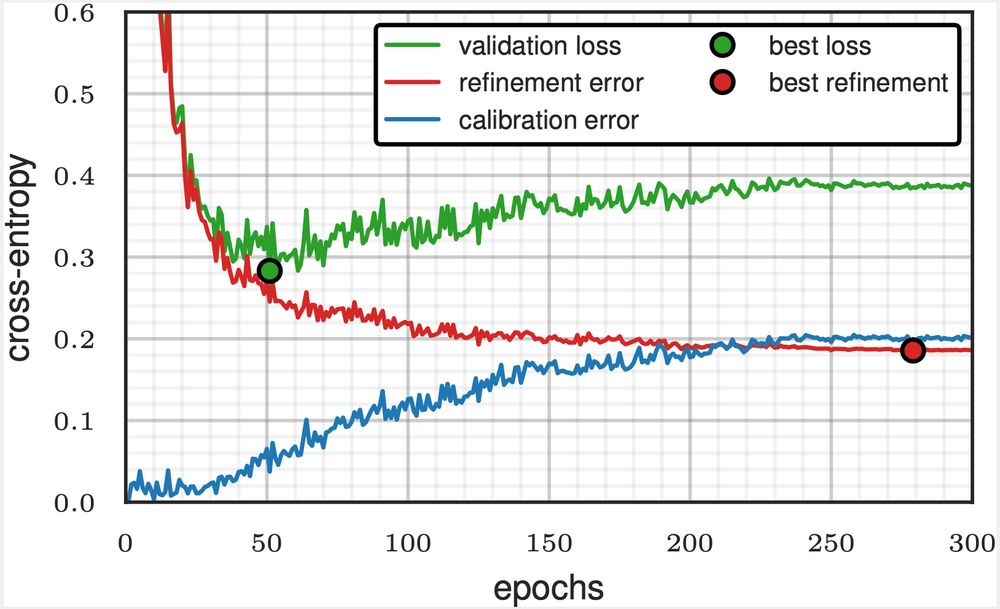
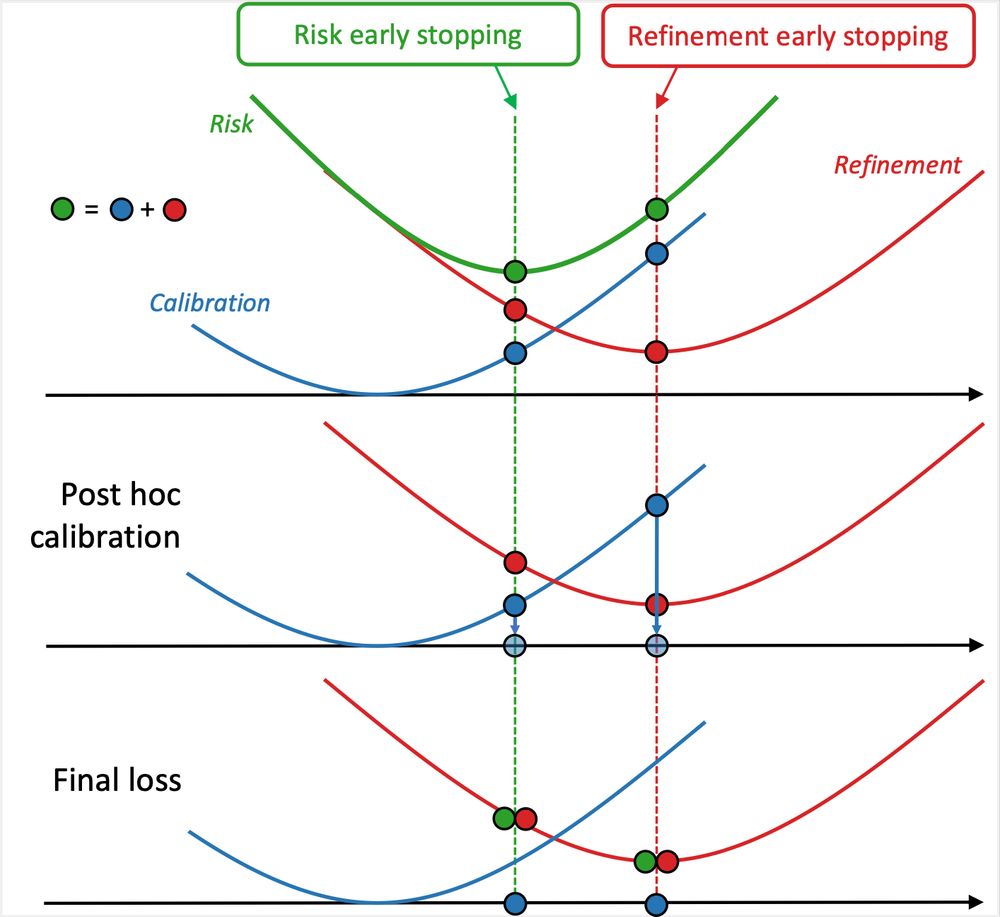
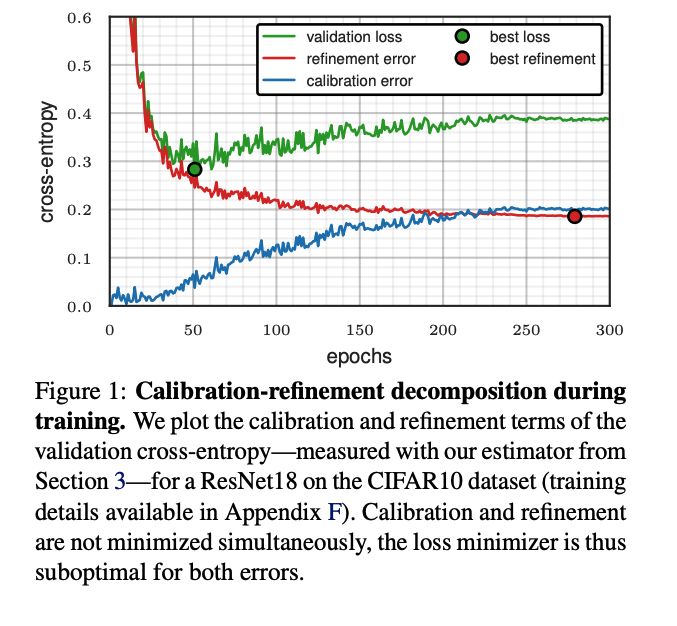
Rethinking Early Stopping: Refine, Then Calibrate
Machine learning classifiers often produce probabilistic predictions that are critical for accurate and interpretable decision-making in various domains. The quality of these predictions is generally ...
arxiv.org