Erik Brockbank
@erikbrockbank.bsky.social
110 followers
220 following
31 posts
Postdoc @Stanford Psychology
Posts
Media
Videos
Starter Packs

Erik Brockbank
@erikbrockbank.bsky.social
· Aug 12

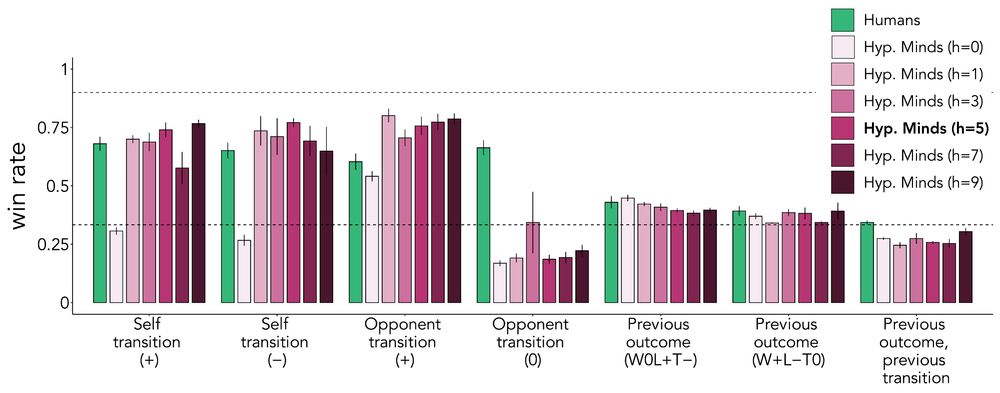
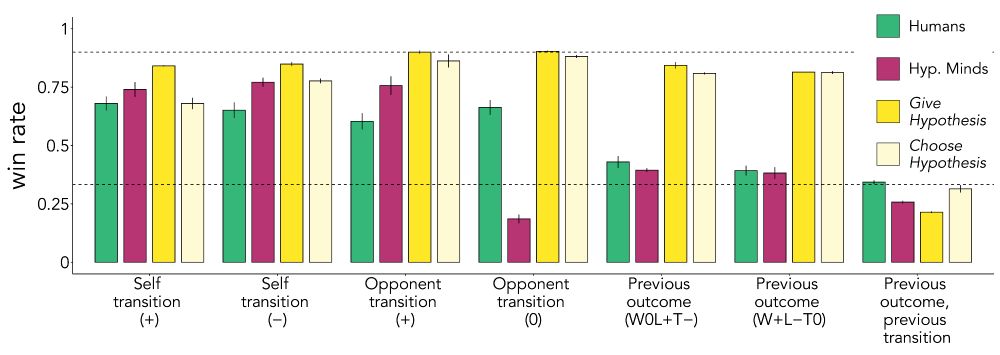
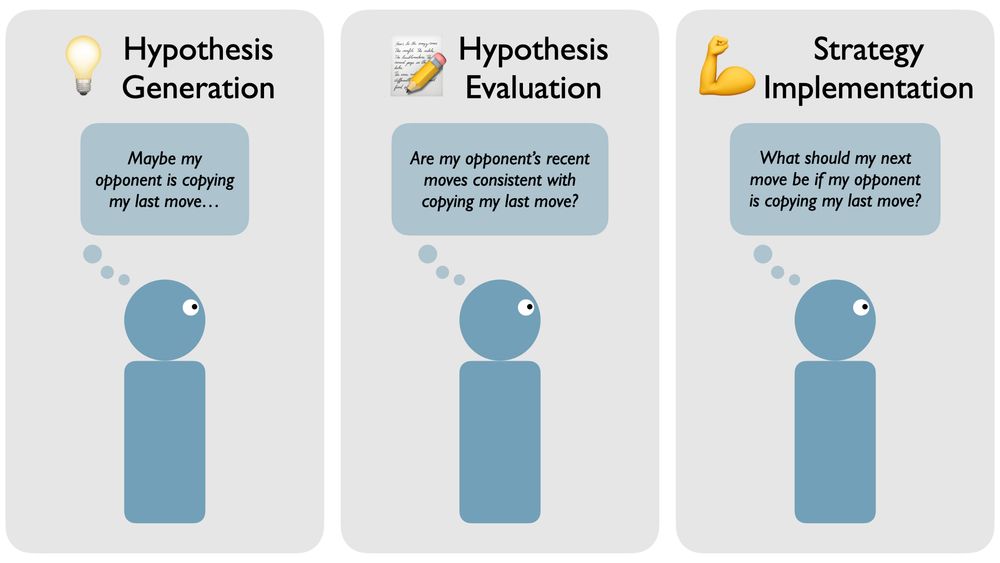
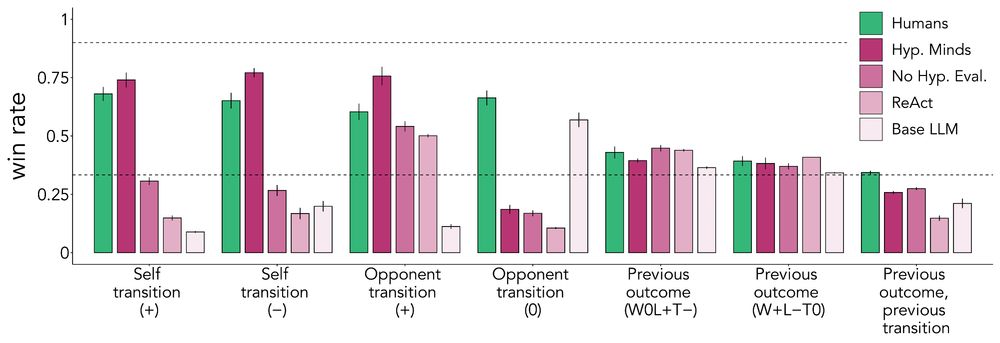

Erik Brockbank
@erikbrockbank.bsky.social
· Jul 30



Reposted by Erik Brockbank




Erik Brockbank
@erikbrockbank.bsky.social
· Apr 28