
François Fleuret
@francois.fleuret.org
5.5K followers
230 following
410 posts
Research Scientist Meta/FAIR, Prof. University of Geneva, co-founder Neural Concept SA. I like reality.
https://fleuret.org
Posts
Media
Videos
Starter Packs
Pinned

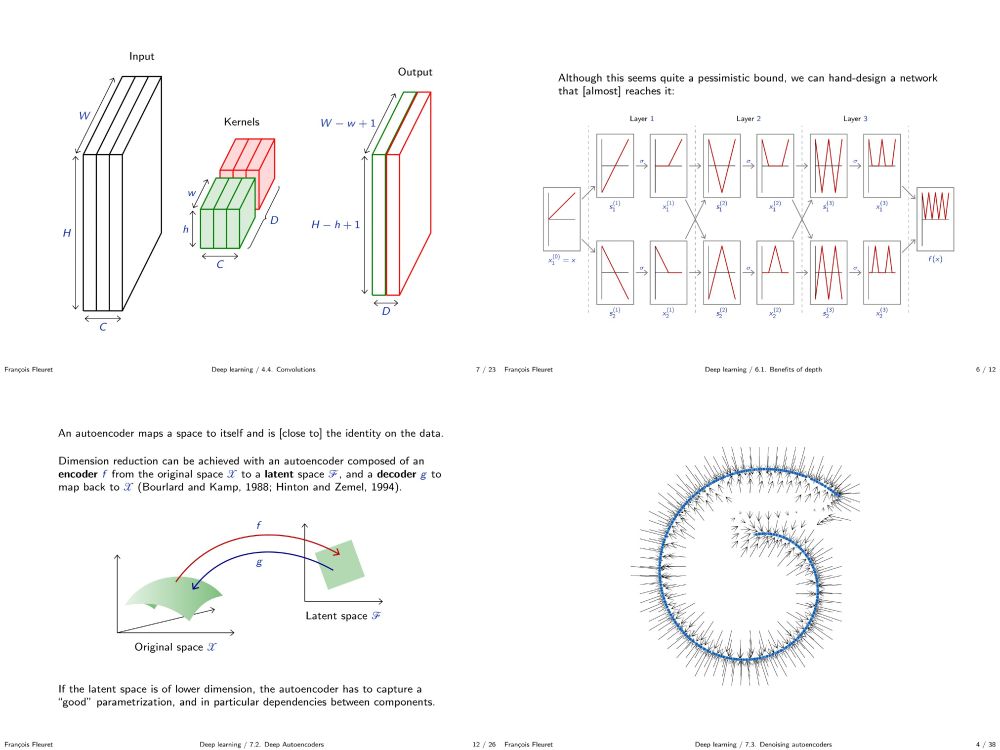
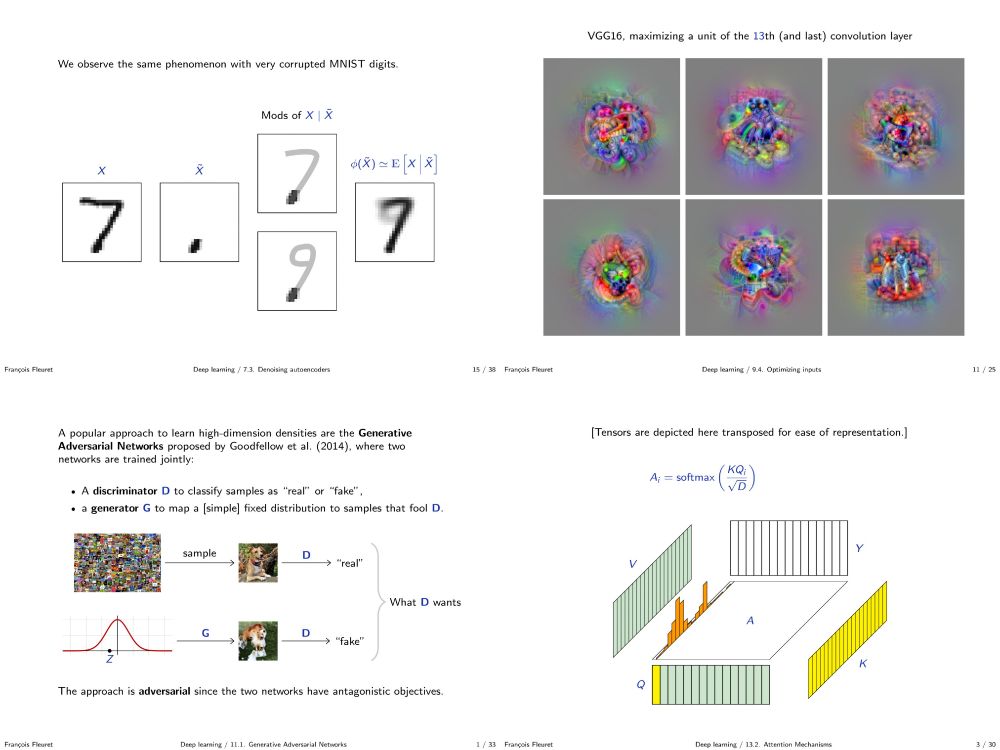
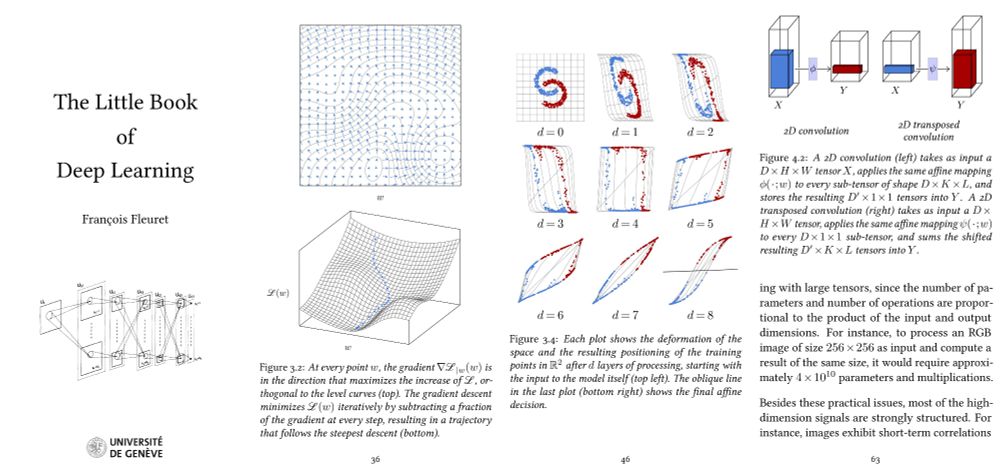
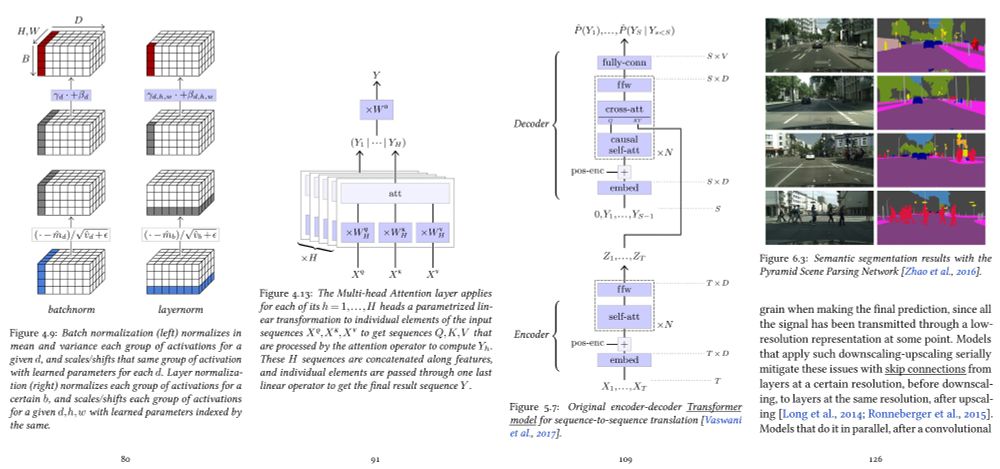

François Fleuret
@francois.fleuret.org
· Apr 28
François Fleuret
@francois.fleuret.org
· Apr 28
François Fleuret
@francois.fleuret.org
· Apr 28
François Fleuret
@francois.fleuret.org
· Apr 28
François Fleuret
@francois.fleuret.org
· Apr 28
François Fleuret
@francois.fleuret.org
· Apr 28
François Fleuret
@francois.fleuret.org
· Apr 28



François Fleuret
@francois.fleuret.org
· Mar 12
François Fleuret
@francois.fleuret.org
· Feb 28
François Fleuret
@francois.fleuret.org
· Feb 28
François Fleuret
@francois.fleuret.org
· Feb 28
François Fleuret
@francois.fleuret.org
· Feb 28

François Fleuret
@francois.fleuret.org
· Feb 27
François Fleuret
@francois.fleuret.org
· Feb 21

Relational Norms for Human-AI Cooperation
How we should design and interact with social artificial intelligence depends on the socio-relational role the AI is meant to emulate or occupy. In human society, relationships such as teacher-student...
arxiv.org
Reposted by François Fleuret


François Fleuret
@francois.fleuret.org
· Feb 11
