
Fabian Schaipp
@fschaipp.bsky.social
420 followers
230 following
16 posts
Researcher in Optimization for ML at Inria Paris. Previously at TU Munich.
https://fabian-sp.github.io/
Posts
Media
Videos
Starter Packs

Fabian Schaipp
@fschaipp.bsky.social
· Feb 5
Fabian Schaipp
@fschaipp.bsky.social
· Feb 5

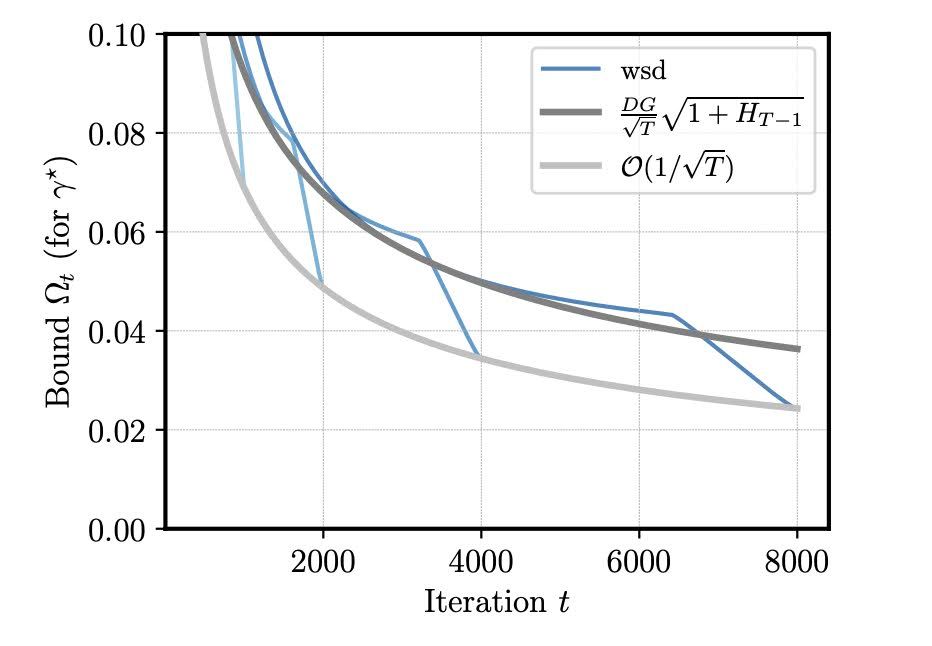
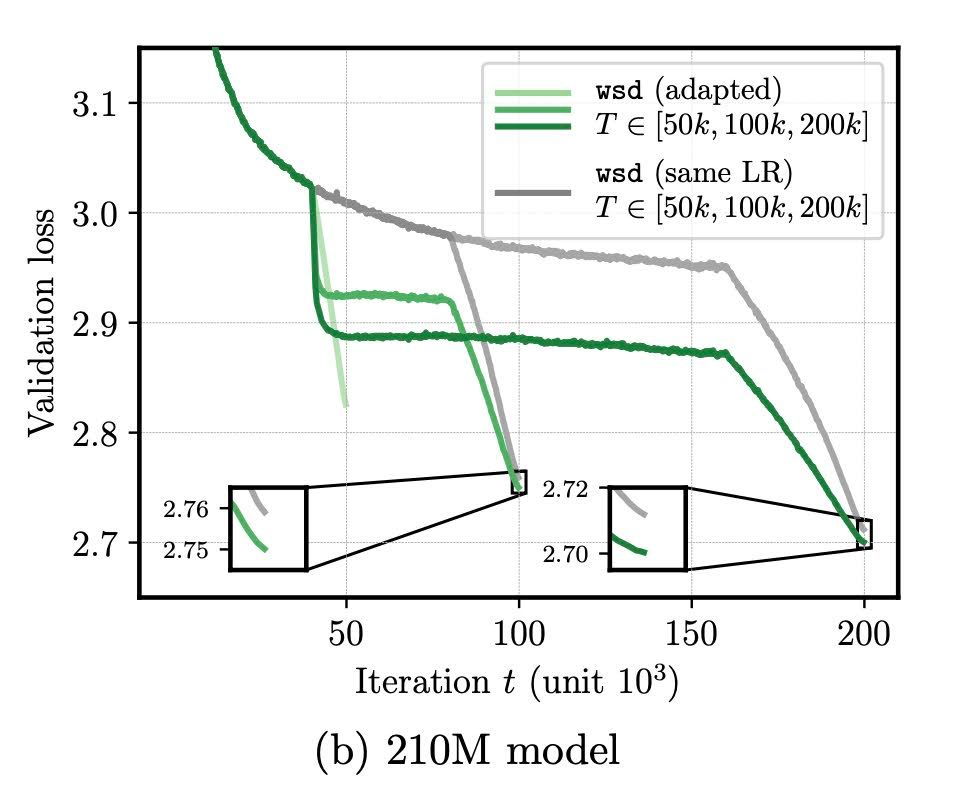
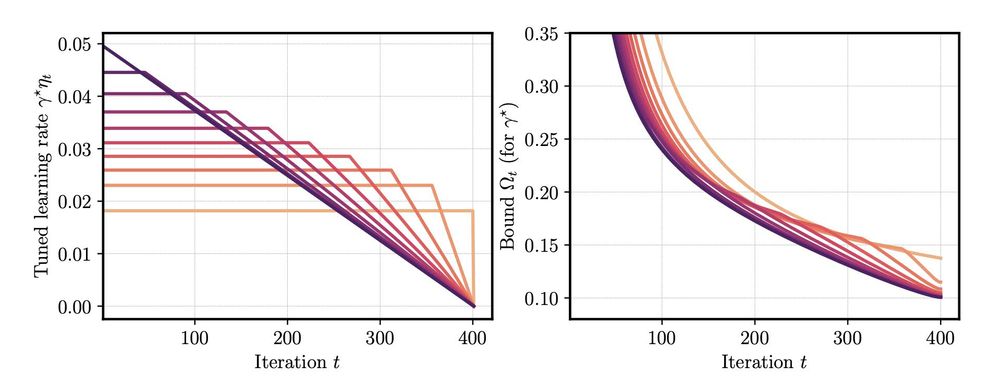
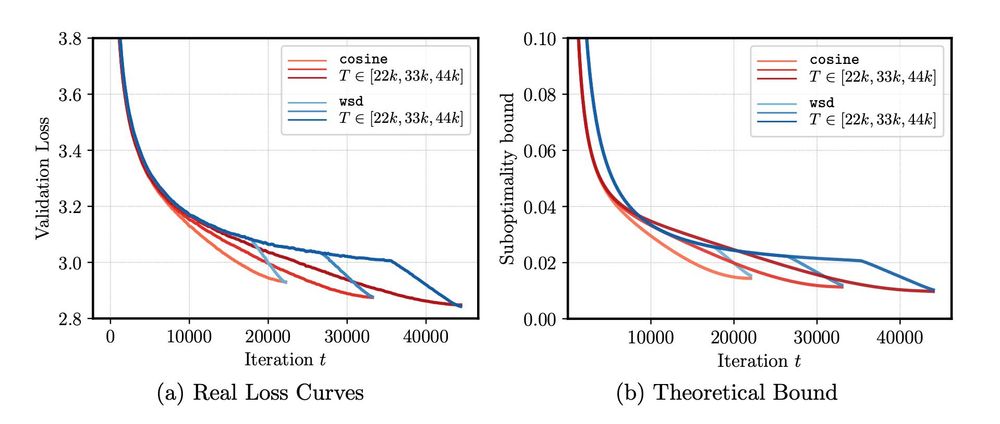
The Surprising Agreement Between Convex Optimization Theory and Learning-Rate Scheduling for Large Model Training
We show that learning-rate schedules for large model training behave surprisingly similar to a performance bound from non-smooth convex optimization theory. We provide a bound for the constant schedul...
arxiv.org
Fabian Schaipp
@fschaipp.bsky.social
· Feb 5
The Surprising Agreement Between Convex Optimization Theory and Learning-Rate Scheduling for Large Model Training
We show that learning-rate schedules for large model training behave surprisingly similar to a performance bound from non-smooth convex optimization theory. We provide a bound for the constant schedul...
arxiv.org
Fabian Schaipp
@fschaipp.bsky.social
· Jan 24
Fabian Schaipp
@fschaipp.bsky.social
· Dec 17
A Bibliography Database for Machine Learning
Getting the correct bibtex entry for a conference paper (e.g. published at NeurIPS, ICML, ICLR) is annoyingly hard: if you search for the title, you will often find a link to arxiv or to the pdf file,...
fabian-sp.github.io
Fabian Schaipp
@fschaipp.bsky.social
· Dec 6

SGD with Clipping is Secretly Estimating the Median Gradient
There are several applications of stochastic optimization where one can benefit from a robust estimate of the gradient. For example, domains such as distributed learning with corrupted nodes, the pres...
arxiv.org
Reposted by Fabian Schaipp


Fabian Schaipp
@fschaipp.bsky.social
· Nov 28
Fabian Schaipp
@fschaipp.bsky.social
· Nov 25
Fabian Schaipp
@fschaipp.bsky.social
· Nov 25
Reposted by Fabian Schaipp

Dirk Lorenz
@dirque.bsky.social
· Nov 18
Fabian Schaipp
@fschaipp.bsky.social
· Nov 22