



Gallil Maimon
@gallilmaimon.bsky.social
PhD student @CseHuji; Audio Processing, Speech Language Modelling
Hey,
I added some longer generation examples, by enforcing `min_new_tokens`. Definitely can lose itself a bit more but still pretty decent I think :)
Check it out:
pages.cs.huji.ac.il/adiyoss-lab/...
And feel free to generate anything with a single line of code:
github.com/slp-rl/slamkit
I added some longer generation examples, by enforcing `min_new_tokens`. Definitely can lose itself a bit more but still pretty decent I think :)
Check it out:
pages.cs.huji.ac.il/adiyoss-lab/...
And feel free to generate anything with a single line of code:
github.com/slp-rl/slamkit

Slamming: Training a Speech Language Model on One GPU in a Day
Slam is a training recipe for training high-quality SLMs on 1 gpu in 24 hours.
pages.cs.huji.ac.il
March 4, 2025 at 3:46 PM
Hey,
I added some longer generation examples, by enforcing `min_new_tokens`. Definitely can lose itself a bit more but still pretty decent I think :)
Check it out:
pages.cs.huji.ac.il/adiyoss-lab/...
And feel free to generate anything with a single line of code:
github.com/slp-rl/slamkit
I added some longer generation examples, by enforcing `min_new_tokens`. Definitely can lose itself a bit more but still pretty decent I think :)
Check it out:
pages.cs.huji.ac.il/adiyoss-lab/...
And feel free to generate anything with a single line of code:
github.com/slp-rl/slamkit
We generated samples with a max length, but the model can predict an "end" token before. One could play with sampling params to make the model keep talking:)
I will try get time to generate longer samples, but also encourage everyone to play around themselves. We tried to make it relatively easy🙏
I will try get time to generate longer samples, but also encourage everyone to play around themselves. We tried to make it relatively easy🙏
February 28, 2025 at 5:35 PM
We generated samples with a max length, but the model can predict an "end" token before. One could play with sampling params to make the model keep talking:)
I will try get time to generate longer samples, but also encourage everyone to play around themselves. We tried to make it relatively easy🙏
I will try get time to generate longer samples, but also encourage everyone to play around themselves. We tried to make it relatively easy🙏
And about this - yes!
We are accepting PRs to add more tokenisers, better optimisers, efficient attention implementations and anything that seems relevant :)
Feel free to reach out 💪
We are accepting PRs to add more tokenisers, better optimisers, efficient attention implementations and anything that seems relevant :)
Feel free to reach out 💪
February 28, 2025 at 5:29 PM
And about this - yes!
We are accepting PRs to add more tokenisers, better optimisers, efficient attention implementations and anything that seems relevant :)
Feel free to reach out 💪
We are accepting PRs to add more tokenisers, better optimisers, efficient attention implementations and anything that seems relevant :)
Feel free to reach out 💪
Hey!
Really pleased you liked our work:) I think with the help of the open source community we can push results even further.
About generation length - the model context is 1024~=40 seconds of audio, but we used a setup like TWIST for evaluation. Definitely worth testing longer generations!
Really pleased you liked our work:) I think with the help of the open source community we can push results even further.
About generation length - the model context is 1024~=40 seconds of audio, but we used a setup like TWIST for evaluation. Definitely worth testing longer generations!
February 28, 2025 at 5:25 PM
Hey!
Really pleased you liked our work:) I think with the help of the open source community we can push results even further.
About generation length - the model context is 1024~=40 seconds of audio, but we used a setup like TWIST for evaluation. Definitely worth testing longer generations!
Really pleased you liked our work:) I think with the help of the open source community we can push results even further.
About generation length - the model context is 1024~=40 seconds of audio, but we used a setup like TWIST for evaluation. Definitely worth testing longer generations!
🔜🗣️It was shown to be really useful for training SpeechLMs. We are working on some stuff now to hopefully make it even easier. More to come soon!💪
January 11, 2025 at 8:00 PM
🔜🗣️It was shown to be really useful for training SpeechLMs. We are working on some stuff now to hopefully make it even easier. More to come soon!💪
For instance, in my opinion, in this example it feels unlikely that people would use stress to convey these meanings. Happy for all and any suggestions and insights :)

December 16, 2024 at 10:59 AM
For instance, in my opinion, in this example it feels unlikely that people would use stress to convey these meanings. Happy for all and any suggestions and insights :)
🥇Project page (+leaderboard) - pages.cs.huji.ac.il/adiyoss-lab/...
📜Paper - arxiv.org/abs/2409.07437
💻Code - github.com/slp-rl/salmon
🤗 Data - huggingface.co/datasets/slp...
📜Paper - arxiv.org/abs/2409.07437
💻Code - github.com/slp-rl/salmon
🤗 Data - huggingface.co/datasets/slp...
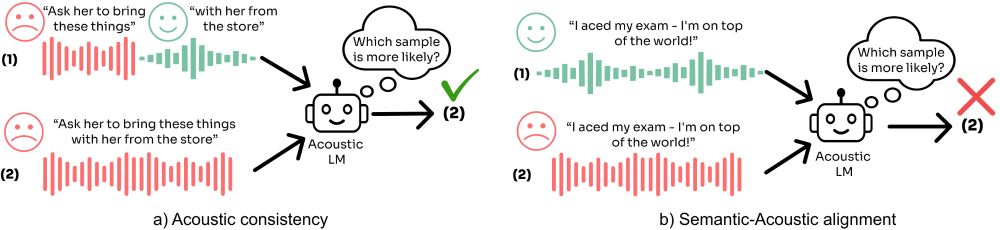
SALMon: Suite for Acoustic Language Model evaluation
SALMon is a suite of benchmarks for evaluating Speech Language Models' ability to model acoustics.
pages.cs.huji.ac.il
November 28, 2024 at 8:39 AM
🥇Project page (+leaderboard) - pages.cs.huji.ac.il/adiyoss-lab/...
📜Paper - arxiv.org/abs/2409.07437
💻Code - github.com/slp-rl/salmon
🤗 Data - huggingface.co/datasets/slp...
📜Paper - arxiv.org/abs/2409.07437
💻Code - github.com/slp-rl/salmon
🤗 Data - huggingface.co/datasets/slp...
🪙 I assume sentiment improved because of style tokens (also shown in STSP metric from SpiritLM). I wonder what is limiting performance - data? modelling? tokens? We welcome suggestions and new SLMs!

November 28, 2024 at 8:39 AM
🪙 I assume sentiment improved because of style tokens (also shown in STSP metric from SpiritLM). I wonder what is limiting performance - data? modelling? tokens? We welcome suggestions and new SLMs!
Great list! I’d be happy to join as well :)
November 27, 2024 at 10:03 AM
Great list! I’d be happy to join as well :)