



Cristina Garbacea
@ggarbacea.bsky.social
PostDoc at UChicago DSI
#CovidIsAirborne 😷
#CovidIsAirborne 😷
Reposted by Cristina Garbacea

We're launching a weekly competition where the community decides which research ideas get implemented. Every week, we'll take the top 3 ideas from IdeaHub, run experiments with AI agents, and share everything: code, successes, and failures.
It's completely free and we'll try out ideas for you!
It's completely free and we'll try out ideas for you!

November 10, 2025 at 9:32 PM
We're launching a weekly competition where the community decides which research ideas get implemented. Every week, we'll take the top 3 ideas from IdeaHub, run experiments with AI agents, and share everything: code, successes, and failures.
It's completely free and we'll try out ideas for you!
It's completely free and we'll try out ideas for you!
Reposted by Cristina Garbacea

AI can accelerate scientific discovery, but only if we get the scientist–AI interaction right.
The dream of “autonomous AI scientists” is tempting:
machines that generate hypotheses, run experiments, and write papers. But science isn’t just automation.
cichicago.substack.com/p/the-mirage...
🧵
The dream of “autonomous AI scientists” is tempting:
machines that generate hypotheses, run experiments, and write papers. But science isn’t just automation.
cichicago.substack.com/p/the-mirage...
🧵

The Mirage of Autonomous AI Scientists
Science as AI’s killer application cannot succeed without scientist-AI interaction: Introducing Hypogenic.ai.
cichicago.substack.com
October 23, 2025 at 6:55 PM
AI can accelerate scientific discovery, but only if we get the scientist–AI interaction right.
The dream of “autonomous AI scientists” is tempting:
machines that generate hypotheses, run experiments, and write papers. But science isn’t just automation.
cichicago.substack.com/p/the-mirage...
🧵
The dream of “autonomous AI scientists” is tempting:
machines that generate hypotheses, run experiments, and write papers. But science isn’t just automation.
cichicago.substack.com/p/the-mirage...
🧵
Reposted by Cristina Garbacea

We are starting to see some nuanced discussions of what it means to work with advanced AI in its current state
In this case, GPT-5 Pro was able to do novel math, but only when guided by a math professor (though the paper also noted the speed of advance since GPT-4)
The reflection is worth reading.
In this case, GPT-5 Pro was able to do novel math, but only when guided by a math professor (though the paper also noted the speed of advance since GPT-4)
The reflection is worth reading.



September 6, 2025 at 9:55 PM
We are starting to see some nuanced discussions of what it means to work with advanced AI in its current state
In this case, GPT-5 Pro was able to do novel math, but only when guided by a math professor (though the paper also noted the speed of advance since GPT-4)
The reflection is worth reading.
In this case, GPT-5 Pro was able to do novel math, but only when guided by a math professor (though the paper also noted the speed of advance since GPT-4)
The reflection is worth reading.
Reposted by Cristina Garbacea
When you walk into the ER, you could get a doc:
1. Fresh from a week of not working
2. Tired from working too many shifts
@oziadias.bsky.social has been both and thinks that they're different! But can you tell from their notes? Yes we can! Paper @natcomms.nature.com www.nature.com/articles/s41...
1. Fresh from a week of not working
2. Tired from working too many shifts
@oziadias.bsky.social has been both and thinks that they're different! But can you tell from their notes? Yes we can! Paper @natcomms.nature.com www.nature.com/articles/s41...

July 2, 2025 at 7:22 PM
When you walk into the ER, you could get a doc:
1. Fresh from a week of not working
2. Tired from working too many shifts
@oziadias.bsky.social has been both and thinks that they're different! But can you tell from their notes? Yes we can! Paper @natcomms.nature.com www.nature.com/articles/s41...
1. Fresh from a week of not working
2. Tired from working too many shifts
@oziadias.bsky.social has been both and thinks that they're different! But can you tell from their notes? Yes we can! Paper @natcomms.nature.com www.nature.com/articles/s41...
Reposted by Cristina Garbacea
Although I cannot make #NAACL2025, @chicagohai.bsky.social will be there. Please say hi!
@chachachen.bsky.social GPT ❌ x-rays (Friday 9-10:30)
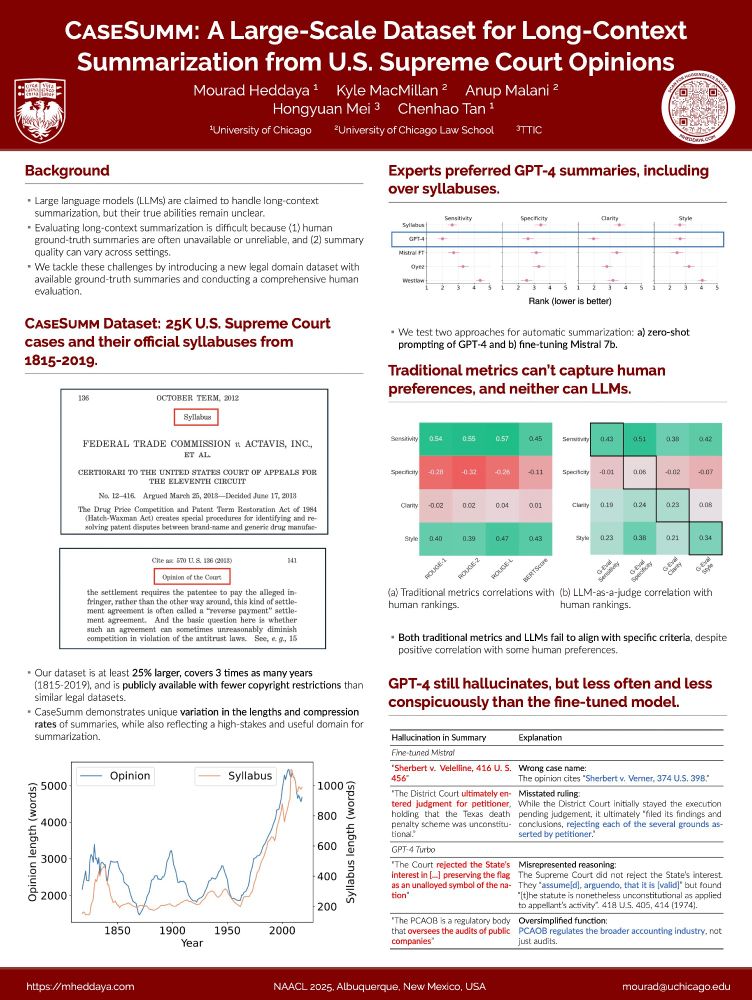
@mheddaya.bsky.social CaseSumm and LLM 🧑⚖️ (Thursday 2-3:30)
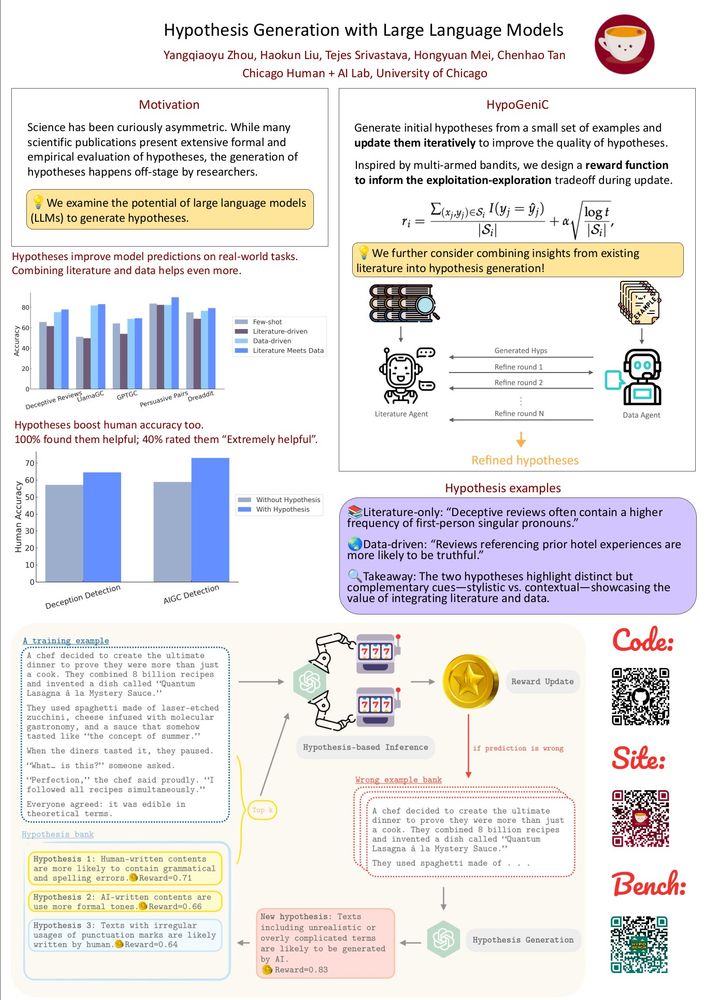
@haokunliu.bsky.social @qiaoyu-rosa.bsky.social hypothesis generation 🔬 (Saturday at 4pm)
@chachachen.bsky.social GPT ❌ x-rays (Friday 9-10:30)
@mheddaya.bsky.social CaseSumm and LLM 🧑⚖️ (Thursday 2-3:30)
@haokunliu.bsky.social @qiaoyu-rosa.bsky.social hypothesis generation 🔬 (Saturday at 4pm)

April 30, 2025 at 8:19 PM
Although I cannot make #NAACL2025, @chicagohai.bsky.social will be there. Please say hi!
@chachachen.bsky.social GPT ❌ x-rays (Friday 9-10:30)
@mheddaya.bsky.social CaseSumm and LLM 🧑⚖️ (Thursday 2-3:30)
@haokunliu.bsky.social @qiaoyu-rosa.bsky.social hypothesis generation 🔬 (Saturday at 4pm)
@chachachen.bsky.social GPT ❌ x-rays (Friday 9-10:30)
@mheddaya.bsky.social CaseSumm and LLM 🧑⚖️ (Thursday 2-3:30)
@haokunliu.bsky.social @qiaoyu-rosa.bsky.social hypothesis generation 🔬 (Saturday at 4pm)
Reposted by Cristina Garbacea
🚀🚀🚀Excited to share our latest work: HypoBench, a systematic benchmark for evaluating LLM-based hypothesis generation methods!
There is much excitement about leveraging LLMs for scientific hypothesis generation, but principled evaluations are missing - let’s dive into HypoBench together.
There is much excitement about leveraging LLMs for scientific hypothesis generation, but principled evaluations are missing - let’s dive into HypoBench together.

April 28, 2025 at 7:35 PM
🚀🚀🚀Excited to share our latest work: HypoBench, a systematic benchmark for evaluating LLM-based hypothesis generation methods!
There is much excitement about leveraging LLMs for scientific hypothesis generation, but principled evaluations are missing - let’s dive into HypoBench together.
There is much excitement about leveraging LLMs for scientific hypothesis generation, but principled evaluations are missing - let’s dive into HypoBench together.
Reposted by Cristina Garbacea
Encourage your students to submit posters and register! Limited free housing is provided for student participants only, on a first-come (i.e., request)-first-serve basis.
We are also actively looking for sponsors. Reach out if you are interested!
Please repost! Help spread the words!
We are also actively looking for sponsors. Reach out if you are interested!
Please repost! Help spread the words!
The Midwest Machine Learning Symposium will happen in Chicago on June 23-4 on the University of Chicago campus (midwest-ml.org/2025/). We have an amazing lineup of speakers:@profsanjeevarora.bsky.social from Princeton, Heng Ji from UIUC, Tuomas Sandholm from CMU, @ravenben.bsky.social from UChicago.

April 21, 2025 at 3:12 PM
Encourage your students to submit posters and register! Limited free housing is provided for student participants only, on a first-come (i.e., request)-first-serve basis.
We are also actively looking for sponsors. Reach out if you are interested!
Please repost! Help spread the words!
We are also actively looking for sponsors. Reach out if you are interested!
Please repost! Help spread the words!
Reposted by Cristina Garbacea

Link to paper: arxiv.org/abs/2504.118...
Joint work with: @ggarbacea.bsky.social Alexis Bellot, Jonathan Richens, Henry Papadatos, Simeon Campos, and Rohin Shah from Google DeepMind, University of Chicago, and SaferAI
Joint work with: @ggarbacea.bsky.social Alexis Bellot, Jonathan Richens, Henry Papadatos, Simeon Campos, and Rohin Shah from Google DeepMind, University of Chicago, and SaferAI

Evaluating the Goal-Directedness of Large Language Models
To what extent do LLMs use their capabilities towards their given goal? We take this as a measure of their goal-directedness. We evaluate goal-directedness on tasks that require information gathering,...
arxiv.org
April 17, 2025 at 9:52 AM
Link to paper: arxiv.org/abs/2504.118...
Joint work with: @ggarbacea.bsky.social Alexis Bellot, Jonathan Richens, Henry Papadatos, Simeon Campos, and Rohin Shah from Google DeepMind, University of Chicago, and SaferAI
Joint work with: @ggarbacea.bsky.social Alexis Bellot, Jonathan Richens, Henry Papadatos, Simeon Campos, and Rohin Shah from Google DeepMind, University of Chicago, and SaferAI
Reposted by Cristina Garbacea
What if LLMs are sometimes capable of doing a task but don't try hard enough to do it?
In a new paper, we use subtasks to assess capabilities. Perhaps surprisingly, LLMs often fail to fully employ their capabilities, i.e. they are not fully *goal-directed* 🧵
arxiv.org/abs/2504.118...
In a new paper, we use subtasks to assess capabilities. Perhaps surprisingly, LLMs often fail to fully employ their capabilities, i.e. they are not fully *goal-directed* 🧵
arxiv.org/abs/2504.118...

April 17, 2025 at 9:44 AM
What if LLMs are sometimes capable of doing a task but don't try hard enough to do it?
In a new paper, we use subtasks to assess capabilities. Perhaps surprisingly, LLMs often fail to fully employ their capabilities, i.e. they are not fully *goal-directed* 🧵
arxiv.org/abs/2504.118...
In a new paper, we use subtasks to assess capabilities. Perhaps surprisingly, LLMs often fail to fully employ their capabilities, i.e. they are not fully *goal-directed* 🧵
arxiv.org/abs/2504.118...
Why is constrained neural language generation particularly
challenging? openreview.net/pdf?id=Vwgjk...
In our TMLR 2025 paper, we discuss approaches, learning methodologies and model architectures employed for generating texts with desirable attributes, and corresponding evaluation metrics.
challenging? openreview.net/pdf?id=Vwgjk...
In our TMLR 2025 paper, we discuss approaches, learning methodologies and model architectures employed for generating texts with desirable attributes, and corresponding evaluation metrics.
openreview.net
March 23, 2025 at 6:26 PM
Why is constrained neural language generation particularly
challenging? openreview.net/pdf?id=Vwgjk...
In our TMLR 2025 paper, we discuss approaches, learning methodologies and model architectures employed for generating texts with desirable attributes, and corresponding evaluation metrics.
challenging? openreview.net/pdf?id=Vwgjk...
In our TMLR 2025 paper, we discuss approaches, learning methodologies and model architectures employed for generating texts with desirable attributes, and corresponding evaluation metrics.